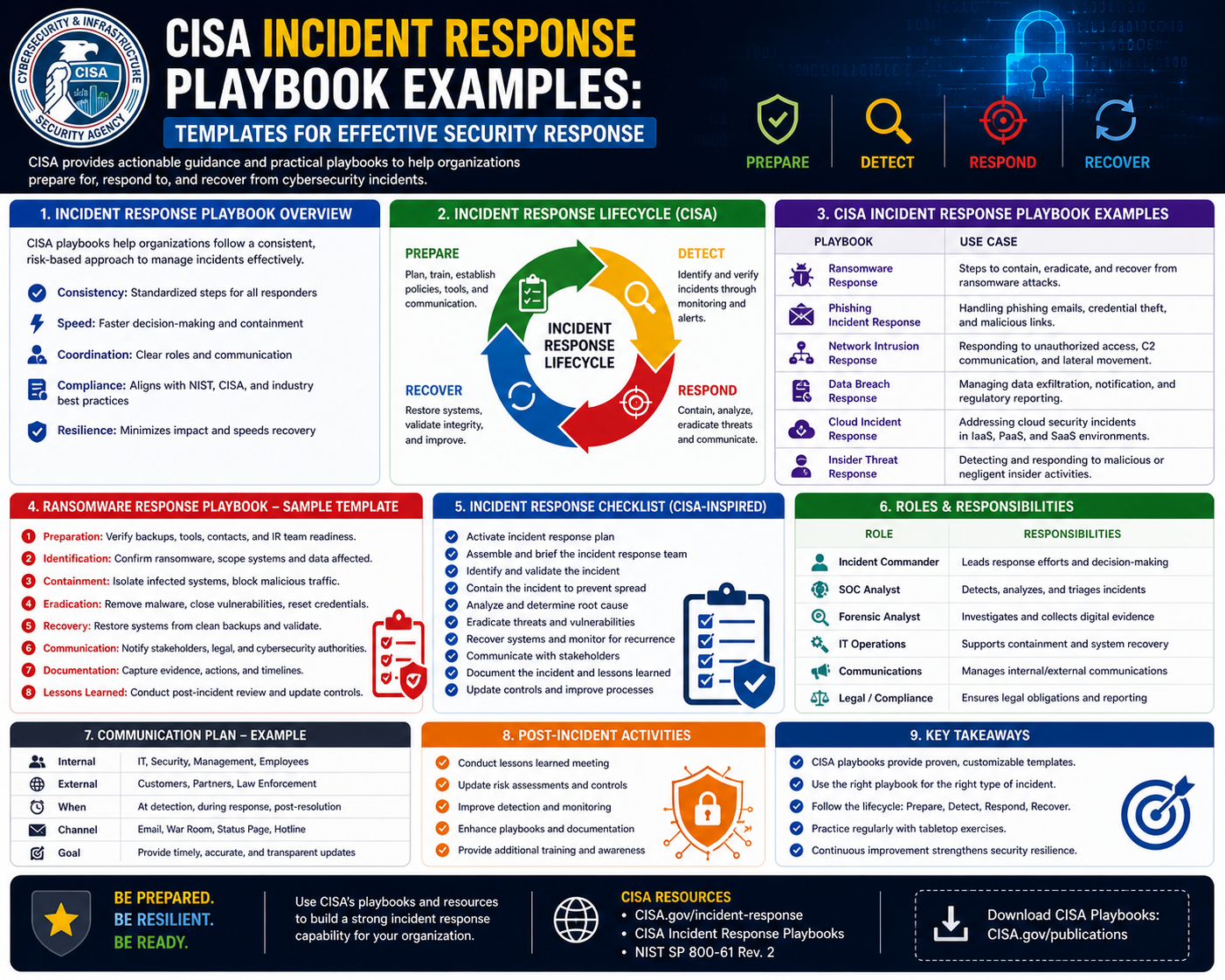
An incident response playbook is a structured operational framework designed to guide cybersecurity and IT teams through the complete handling of security incidents. It establishes a repeatable methodology for detecting, analyzing, containing, eradicating, and recovering from cyber events in a controlled manner. Rather than relying on improvised decision-making during high-pressure situations, organizations use playbooks to ensure that every response follows a predefined and validated sequence of actions. This reduces ambiguity, improves response speed, and ensures that critical steps are not missed when systems are under attack or compromised. In complex enterprise environments where multiple systems, applications, and users interact continuously, the likelihood of security incidents is not a matter of possibility but inevitability. Phishing campaigns, malware infections, credential misuse, and misconfigured systems all represent common entry points for attackers. Without structured guidance, these incidents can escalate rapidly, causing operational disruption, financial loss, and reputational damage. A playbook acts as a stabilizing mechanism that transforms chaotic incident scenarios into controlled operational workflows. It ensures that responses remain consistent across different teams and shifts, regardless of individual experience levels or situational stress.
Strategic Importance of Structured Response Mechanisms
The strategic value of incident response playbooks lies in their ability to impose order on unpredictable security events. Cyber incidents are rarely static; they evolve dynamically as attackers adapt to defensive actions. This requires response teams to act quickly while maintaining precision and coordination. Structured response mechanisms ensure that every action taken during an incident aligns with predefined organizational policies and technical standards. This reduces the risk of conflicting actions, such as multiple teams attempting different containment strategies simultaneously, which can worsen the impact of an incident. A structured approach also enhances decision-making efficiency by removing uncertainty regarding what steps should be taken next. Instead of debating procedures during an active incident, teams follow established workflows that have been designed and tested in advance. This allows responders to focus their cognitive resources on analyzing the specific characteristics of the incident rather than determining procedural steps. Additionally, structured response mechanisms improve organizational resilience by ensuring that knowledge is embedded in documented processes rather than relying on individual expertise. This is particularly important in environments with high staff turnover or distributed teams, where consistency of response is critical for maintaining security posture.
Lifecycle-Based Framework of Incident Handling
The foundation of every incident response playbook is the lifecycle-based framework that defines how incidents progress from detection to resolution. This lifecycle typically includes several interconnected phases that collectively ensure complete incident management. The first phase is identification, where potential security events are detected through monitoring systems, user reports, or automated alerts. During this phase, the primary objective is to validate whether the observed activity represents a genuine security incident or a benign anomaly. Accurate identification is essential because misclassification can lead to unnecessary disruption or delayed response to real threats. Once an incident is confirmed, the containment phase begins. Containment focuses on limiting the spread and impact of the incident within the environment. This may involve isolating affected systems, restricting network traffic, or disabling compromised credentials. The goal is to prevent further damage while preserving evidence for investigation. Following containment, eradication procedures are implemented to remove the root cause of the incident. This may include eliminating malicious code, closing exploited vulnerabilities, or removing unauthorized access mechanisms. After eradication, the recovery phase restores systems to normal operational status. This often involves system restoration from backups, validation of system integrity, and gradual reintegration into production environments. The final phase is post-incident analysis, where teams evaluate the incident response process, identify gaps, and implement improvements. This cyclical model ensures continuous refinement of security practices over time.
Incident Identification and Detection Processes
Effective incident response begins with reliable detection and identification mechanisms. Modern IT environments generate vast amounts of data from logs, network traffic, endpoint activities, and application behavior. Within this data, potential indicators of compromise must be identified and assessed. Detection mechanisms may include automated security tools, intrusion detection systems, endpoint monitoring solutions, or manual reporting by users. However, detection alone is not sufficient; accurate identification requires contextual analysis to determine whether an alert represents a legitimate security incident. This process involves correlating multiple data points, analyzing behavioral patterns, and evaluating system anomalies. For example, repeated failed login attempts from unfamiliar locations may indicate a brute force attack, while unexpected data transfers may suggest exfiltration activity. The identification phase also involves determining the scope of the incident, including which systems are affected and how deeply the compromise has penetrated the environment. Accurate scoping is critical because it directly influences containment and eradication strategies. If the scope is underestimated, the incident may persist undetected in other parts of the system. If overestimated, unnecessary disruption may occur during containment actions.
Classification of Security Incidents for Operational Efficiency
Incident classification is a key component of structured response systems because it ensures that different types of threats are handled using appropriate methodologies. Security incidents vary significantly in nature and severity, requiring tailored response strategies. Common classifications include malicious software infections, unauthorized access attempts, denial of service disruptions, data exposure events, and insider threats. Each category presents unique technical challenges and requires specific containment and remediation approaches. For instance, malware incidents often require system isolation and forensic analysis, while data exposure incidents may require legal coordination and regulatory assessment. Classification also helps prioritize response efforts based on severity levels. High-impact incidents affecting critical systems or sensitive data require immediate escalation, while lower-impact events may follow standard response timelines. Proper classification improves operational efficiency by ensuring that resources are allocated appropriately and that response teams are not overwhelmed by unnecessary escalation. It also enhances communication clarity by providing a shared understanding of the incident type across technical and non-technical stakeholders. This shared understanding is essential for coordinated action during time-sensitive security events.
Governance Structures and Accountability Mechanisms
Incident response playbooks are closely tied to organizational governance structures that define how security operations are managed and controlled. Governance ensures that incident response activities align with organizational policies, regulatory requirements, and risk management frameworks. A key aspect of governance is accountability, which assigns specific responsibilities to individuals or teams involved in incident handling. Without clear accountability, response efforts can become fragmented, leading to delays or incomplete actions. Playbooks define roles such as incident coordinators, technical analysts, system administrators, communication managers, and executive decision-makers. Each role has clearly defined responsibilities that contribute to the overall response process. The incident coordinator typically oversees the entire response effort, ensuring that procedures are followed correctly and that communication remains consistent. Technical analysts focus on identifying root causes and executing remediation steps, while system administrators manage infrastructure-level changes. Communication roles ensure that stakeholders receive timely and accurate updates. Governance also extends to documentation requirements, where every action taken during an incident must be recorded with precision. This documentation provides transparency and supports both internal reviews and external audits. It ensures that organizations can demonstrate compliance with security standards and regulatory obligations.
Consistency and Standardization in Incident Handling
Consistency is one of the most important benefits provided by incident response playbooks. In many organizations, multiple teams may be involved in incident handling across different time zones or operational shifts. Without standardized procedures, responses may vary significantly depending on who is managing the incident. This inconsistency can lead to inefficiencies, duplicated efforts, or missed critical steps. Standardization ensures that every incident is handled using the same structured approach, regardless of personnel changes or situational pressures. This uniformity reduces uncertainty during high-stress situations and allows responders to focus on execution rather than decision-making. Consistency also improves training effectiveness, as new team members can learn established procedures more easily when they are clearly documented and consistently applied. Over time, standardized incident handling contributes to organizational maturity by creating predictable outcomes and measurable performance indicators. It also supports continuous improvement by providing a stable baseline against which changes and enhancements can be evaluated.
Advanced Structure of Incident Response Playbooks in Enterprise Environments
Incident response playbooks in enterprise cybersecurity environments are designed as highly structured operational documents that extend beyond simple procedural checklists. They function as comprehensive frameworks that integrate technical procedures, governance controls, communication protocols, and decision-making hierarchies into a unified response system. As organizations scale, their digital ecosystems become increasingly complex, involving hybrid cloud infrastructures, distributed endpoints, third-party integrations, and multi-layered authentication systems. In such environments, incident response cannot remain informal or reactive; it must be engineered as a controlled operational discipline. Playbooks, therefore, evolve into advanced structures that not only define what actions should be taken but also specify when, how, and by whom those actions must be executed. This level of precision ensures that incident handling remains consistent across geographically distributed teams and diverse technological environments. The structure typically includes modular sections that correspond to different phases of incident handling, enabling responders to quickly navigate to relevant instructions depending on the nature of the incident. This modular design also supports scalability, allowing organizations to add new response procedures as new threat vectors emerge without disrupting the entire framework.
Detailed Incident Classification Systems and Operational Mapping
A critical component of advanced incident response playbooks is the classification system used to categorize security events. Classification is not merely a labeling exercise; it is a strategic mechanism that determines the entire response pathway. In mature cybersecurity environments, incidents are categorized based on multiple dimensions, including impact severity, threat type, affected systems, data sensitivity, and potential regulatory implications. For example, a credential compromise affecting a privileged administrator account is classified differently from a low-level phishing attempt targeting general users. Similarly, a ransomware infection affecting production systems is treated with significantly higher priority than malware detected in a sandbox environment. Each classification triggers a predefined operational mapping that outlines specific response workflows. These mappings ensure that appropriate containment strategies, escalation paths, and communication protocols are activated automatically based on incident type. This structured mapping eliminates ambiguity during high-pressure situations and ensures that critical incidents receive immediate attention from the appropriate response teams. It also improves resource allocation by preventing unnecessary escalation of low-risk events, allowing security teams to focus their efforts on high-impact threats.
Role Definition and Responsibility Segmentation in Response Teams
Incident response playbooks rely heavily on clearly defined role structures to ensure coordinated execution during security events. In complex organizations, incident response is a collaborative effort involving multiple specialized roles, each contributing distinct expertise to the overall process. These roles are segmented based on functional responsibilities to ensure efficiency and accountability. The incident response lead or coordinator is responsible for overseeing the entire lifecycle of the incident, ensuring that all procedural steps are followed correctly and that communication remains aligned across teams. Security analysts focus on investigating the incident, identifying indicators of compromise, and determining the scope and impact of the attack. System administrators handle infrastructure-level actions such as isolating servers, applying patches, or restoring services. Network engineers manage traffic control measures, including firewall adjustments and segmentation strategies. Communication officers are responsible for disseminating information internally and externally, ensuring that messaging remains consistent and compliant with organizational policies. Executive stakeholders provide strategic oversight and authorize critical decisions, especially when incidents have legal, financial, or reputational implications. This segmentation of responsibilities ensures that no single individual is overwhelmed during an incident and that tasks are executed by personnel with appropriate expertise.
Communication Architecture During Security Incidents
Communication is one of the most critical elements in incident response operations, particularly in large-scale or high-severity incidents. A well-defined communication architecture ensures that information flows efficiently between technical teams, management, and external stakeholders. During a security incident, timely and accurate communication can significantly influence the outcome by enabling faster decision-making and coordinated action. Internal communication frameworks define how updates are shared among IT teams, security analysts, and leadership. These updates typically include incident status, affected systems, mitigation progress, and anticipated recovery timelines. External communication frameworks govern how information is shared with regulatory bodies, customers, partners, and, when necessary, the public. This is particularly important in incidents involving data exposure or regulatory compliance obligations. Communication protocols also define escalation thresholds, specifying when incidents must be reported to senior leadership based on severity or impact. Structured communication reduces the risk of misinformation, duplication of effort, or delayed responses. It also ensures that all stakeholders maintain a shared understanding of the incident, which is essential for coordinated response efforts. In addition, communication logs are often maintained as part of incident documentation, providing a record of all messages exchanged during the response process.
Containment Strategies and Operational Control Mechanisms
Containment is a critical phase in the incident response lifecycle that focuses on limiting the spread and impact of a security incident. Effective containment strategies are designed to isolate affected systems while preserving business continuity wherever possible. In modern enterprise environments, containment may involve a combination of technical and procedural controls. Technical controls include network segmentation, endpoint isolation, firewall rule adjustments, and access restriction mechanisms. Procedural controls may involve disabling compromised user accounts, restricting administrative privileges, or temporarily suspending affected services. The primary objective of containment is to prevent further damage while maintaining system stability and preserving forensic evidence for investigation. Containment strategies are typically categorized into short-term and long-term approaches. Short-term containment focuses on immediate actions to stop the spread of the incident, while long-term containment involves implementing more sustainable controls to ensure that the threat cannot re-emerge during recovery. Decision-making during containment requires careful balancing between operational continuity and security enforcement. Overly aggressive containment may disrupt business operations, while insufficient containment may allow the incident to escalate. Playbooks provide structured guidance to ensure that containment actions are proportional to the severity and nature of the incident.
Eradication Processes and Root Cause Elimination Techniques
Once an incident has been contained, the next phase involves eradication, which focuses on removing the root cause of the security event from the environment. Eradication is a technically intensive phase that requires detailed analysis and precise execution. The objective is to ensure that all malicious elements, including malware, unauthorized access points, or exploited vulnerabilities, are eliminated from affected systems. This process often begins with forensic analysis to identify the origin and behavior of the attack. Security teams examine system logs, network traffic, and endpoint activity to reconstruct the attack chain. Based on this analysis, eradication measures are implemented, which may include removing malicious files, uninstalling compromised software, resetting credentials, applying security patches, or reconfiguring system settings. In more severe cases, systems may need to be rebuilt from trusted baseline images to ensure complete remediation. Eradication also involves addressing the underlying vulnerability that allowed the incident to occur in the first place. This may include fixing software flaws, strengthening authentication mechanisms, or improving configuration controls. Without proper eradication, there is a risk that the incident could recur even after recovery, making this phase critical for long-term security stability.
Recovery Operations and System Restoration Procedures
Recovery is the phase in which affected systems and services are restored to normal operational status after containment and eradication have been completed. This phase focuses on ensuring that business operations can resume safely and efficiently without reintroducing vulnerabilities. Recovery procedures typically involve restoring data from secure backups, validating system integrity, and gradually reintegrating systems into the production environment. Before full restoration, systems are often tested in controlled environments to confirm that they are free from malicious artifacts and functioning correctly. Recovery also includes monitoring systems closely after restoration to detect any signs of residual activity or re-infection. This monitoring period is critical because some advanced threats may attempt to re-establish persistence after initial eradication efforts. In addition to technical restoration, recovery operations also involve validating that business processes dependent on affected systems are functioning correctly. This ensures that operational continuity is fully restored across the organization. Recovery procedures must be carefully documented to provide evidence of actions taken and to support post-incident analysis. This documentation also helps organizations refine their recovery strategies for future incidents.
Documentation Practices and Forensic Evidence Management
Documentation is a foundational element of incident response playbooks and plays a crucial role in both operational transparency and regulatory compliance. Every action taken during an incident must be recorded in detail, including timestamps, system changes, decision points, and communication exchanges. This documentation serves multiple purposes, including supporting forensic investigations, enabling post-incident analysis, and providing evidence for audits or legal proceedings. Forensic evidence management is particularly important in incidents involving data breaches or regulatory violations, where a detailed reconstruction of events is required. Evidence must be preserved in a secure and tamper-proof manner to maintain its integrity. This includes system logs, memory dumps, network traffic captures, and file system snapshots. Proper chain-of-custody procedures are followed to ensure that evidence remains admissible for investigative or legal purposes. Documentation also supports organizational learning by providing a detailed record of how incidents were handled, what challenges were encountered, and what improvements can be made. Over time, this historical data becomes a valuable resource for refining incident response strategies and improving overall security posture.
Operational Deployment of Incident Response Playbooks in Real-World Environments
The operational deployment of incident response playbooks involves integrating structured response procedures directly into day-to-day cybersecurity operations. Rather than existing as static documentation, playbooks are embedded into live security workflows, monitoring systems, and operational decision-making processes. In mature security environments, playbooks are treated as active operational assets that guide real-time actions during security incidents. Deployment begins with aligning playbooks to the organization’s infrastructure architecture, ensuring that every system, application, and network segment is mapped to relevant response procedures. This alignment ensures that when an incident occurs, responders can immediately identify which playbook applies and execute predefined steps without delay. Operational deployment also requires integration with monitoring tools that generate alerts based on anomalous behavior. These alerts are mapped to specific playbooks, enabling rapid activation of response workflows. In highly advanced environments, playbooks may be automatically triggered when certain conditions are detected, allowing for near real-time containment of threats. This level of integration transforms incident response from a manual process into a semi-automated operational capability that significantly reduces response time and improves consistency.
Simulation-Based Validation and Organizational Preparedness Testing
Simulation exercises are a fundamental component of validating incident response playbooks in operational environments. These exercises replicate realistic cyberattack scenarios in a controlled setting, allowing security teams to execute response procedures without risking production systems. The primary objective of simulation-based validation is to assess whether playbooks are practical, understandable, and executable under pressure. During these exercises, teams are presented with scenarios such as ransomware outbreaks, phishing campaigns, or unauthorized access events, and are required to follow playbook instructions step by step. This process reveals gaps in procedural clarity, communication breakdowns, and inefficiencies in role execution. It also highlights areas where additional training or refinement is required. Simulation exercises are typically conducted at regular intervals to ensure that teams remain familiar with response procedures and that playbooks remain aligned with evolving threats. These exercises also serve as a mechanism for improving coordination between different departments, including IT operations, cybersecurity teams, legal departments, and executive leadership. By simulating real-world conditions, organizations can identify weaknesses in their response strategies before they are exposed during actual incidents.
Continuous Evolution and Lifecycle Optimization of Playbooks
Incident response playbooks are dynamic frameworks that require continuous refinement to remain effective in evolving threat landscapes. Cyber threats are constantly changing in complexity, scale, and methodology, which means static response procedures quickly become outdated. Continuous evolution ensures that playbooks remain relevant and capable of addressing new attack vectors. This process is driven primarily by post-incident analysis, where organizations review how incidents were handled and identify areas for improvement. Lessons learned from these analyses are incorporated into updated versions of playbooks, refining procedural steps, enhancing decision-making criteria, and improving escalation mechanisms. Lifecycle optimization also involves periodic reviews of playbook structures to ensure alignment with organizational changes, such as infrastructure upgrades, cloud migrations, or changes in regulatory requirements. As organizations adopt new technologies, playbooks must evolve to account for new system dependencies and potential vulnerabilities. Continuous improvement also involves incorporating feedback from simulation exercises and operational drills. This iterative refinement process ensures that playbooks remain practical, efficient, and aligned with real-world operational needs.
Integration with Security Automation and Orchestration Systems
Modern cybersecurity environments increasingly rely on automation and orchestration technologies to enhance incident response capabilities. Incident response playbooks are often integrated with these systems to enable automated execution of predefined response actions. Security orchestration platforms can trigger specific playbook steps based on real-time security alerts, reducing the need for manual intervention in the early stages of an incident. For example, when suspicious login activity is detected, the system may automatically initiate account lockdown procedures, isolate affected endpoints, and notify response teams. This integration significantly reduces response time, which is critical in minimizing the impact of fast-moving cyberattacks. Automation also ensures consistency in response execution, eliminating human variability during initial containment phases. However, automation must be carefully governed to avoid unintended disruptions, as overly aggressive automated actions can impact legitimate business operations. Therefore, playbooks define clear boundaries for automated actions, specifying which steps can be automated and which require human approval. This hybrid approach combines the speed of automation with the judgment of human decision-making, creating a balanced and efficient incident response model.
Metrics, Performance Measurement, and Operational Effectiveness
Measuring the effectiveness of incident response playbooks is essential for ensuring continuous improvement and operational maturity. Organizations use a variety of performance metrics to evaluate how efficiently incidents are detected, contained, and resolved. One of the most important metrics is detection time, which measures how quickly an incident is identified after it occurs. Faster detection reduces the potential impact of an attack and allows for earlier containment. Another key metric is containment time, which measures how quickly the spread of an incident is controlled after detection. Recovery time is also critical, as it reflects how efficiently systems are restored to normal operation after an incident. In addition to time-based metrics, organizations also evaluate the accuracy of incident classification, the effectiveness of communication during incidents, and the frequency of recurring incidents. High recurrence rates may indicate that underlying vulnerabilities are not being adequately addressed. These performance indicators are analyzed regularly to identify trends and areas for improvement. Over time, they provide a quantitative measure of incident response maturity and help organizations benchmark their performance against industry standards. Continuous monitoring of these metrics ensures that playbooks remain effective and aligned with organizational security objectives.
Governance Integration and Regulatory Alignment in Incident Response
Incident response playbooks play a critical role in ensuring compliance with governance frameworks and regulatory requirements. In many industries, organizations are required to demonstrate that they have structured processes in place for handling security incidents. Playbooks provide the documented evidence needed to satisfy these requirements by outlining standardized procedures for detection, response, and recovery. Governance integration ensures that incident response activities are aligned with broader organizational risk management strategies. This includes ensuring that response actions comply with legal obligations, industry standards, and internal security policies. Regulatory alignment is particularly important in sectors that handle sensitive data, where breaches may require mandatory reporting to regulatory authorities within strict timeframes. Playbooks define these reporting requirements and ensure that communication procedures are followed correctly during incidents. They also establish documentation standards that support audit readiness by maintaining detailed records of all actions taken during an incident. This level of governance integration ensures that incident response is not only technically effective but also legally and organizationally compliant.
Post-Incident Review and Knowledge Consolidation Processes
Post-incident review is a critical phase in the incident response lifecycle that focuses on analyzing the effectiveness of response efforts after an incident has been resolved. This process involves a detailed examination of what occurred, how it was handled, and what improvements can be made. Teams review detection timelines, containment strategies, eradication effectiveness, and recovery procedures to identify strengths and weaknesses in the response process. The insights gained from this analysis are used to update playbooks and improve future response capabilities. Post-incident reviews also serve as a knowledge consolidation mechanism, capturing lessons learned and embedding them into organizational processes. This ensures that knowledge gained from individual incidents is not lost but instead used to strengthen the overall security posture. The review process typically involves collaboration between technical teams, management, and sometimes external stakeholders, depending on the severity of the incident. By systematically analyzing each incident, organizations create a feedback loop that continuously improves their incident response maturity over time.
Conclusion
Incident response playbooks represent a foundational capability in modern cybersecurity operations, functioning as structured mechanisms that transform unpredictable security events into controlled, repeatable, and measurable response processes. Their importance lies not only in technical execution but also in the way they unify governance, operational discipline, and organizational accountability into a single coherent framework. In environments where digital infrastructure is continuously exposed to evolving threats, the absence of structured response mechanisms significantly increases the likelihood of operational disruption, data compromise, and regulatory exposure. Playbooks address this risk by ensuring that every incident, regardless of its origin or severity, is handled through a predefined sequence of validated actions.
One of the most critical outcomes of implementing incident response playbooks is the reduction of ambiguity during high-pressure situations. Security incidents are inherently stressful, often involving incomplete information, time constraints, and potential business impact. In such conditions, human decision-making alone can lead to inconsistency, delays, or procedural errors. Playbooks mitigate this risk by providing responders with a clear operational path that defines what actions should be taken, in what order, and by whom. This structured clarity allows technical teams to focus on execution rather than interpretation, significantly improving response efficiency and reducing the probability of escalation.
Another essential contribution of playbooks is the establishment of operational consistency across the organization. In large enterprises, incident response responsibilities are often distributed across multiple teams, geographic regions, and time zones. Without standardized procedures, each team may develop its own interpretation of how incidents should be handled, resulting in fragmented responses and uneven outcomes. Playbooks eliminate this variability by enforcing a unified response model that applies consistently across all teams and environments. This consistency is particularly important for organizations with complex infrastructures that include cloud services, on-premises systems, third-party integrations, and remote endpoints, all of which must be managed cohesively during security events.
From a governance perspective, incident response playbooks serve as critical compliance artifacts that demonstrate organizational readiness and control maturity. Regulatory frameworks and industry standards increasingly require organizations to maintain documented incident response procedures that define roles, responsibilities, escalation paths, and communication protocols. Playbooks fulfill these requirements by providing structured documentation that can be reviewed during audits or investigations. More importantly, they demonstrate that incident handling is not dependent on individual expertise but is instead embedded within formal organizational processes. This level of structure is essential for maintaining trust with stakeholders, regulators, and customers, particularly in industries that handle sensitive or regulated data.
Playbooks also play a significant role in improving organizational resilience. Resilience in cybersecurity is not solely defined by the ability to prevent attacks but also by the ability to respond and recover effectively when incidents occur. A well-designed playbook ensures that organizations can quickly transition from disruption to recovery by following clearly defined restoration procedures. This reduces downtime, minimizes financial loss, and helps maintain continuity of critical business operations. Over time, repeated use of structured response procedures strengthens organizational confidence and capability, allowing teams to handle increasingly complex incidents with greater efficiency.
The integration of playbooks with detection and monitoring systems further enhances their operational value. Modern security environments generate vast amounts of telemetry data, which can be analyzed to detect anomalies and trigger alerts. When these alerts are mapped to specific playbooks, organizations can achieve rapid response activation, significantly reducing the time between detection and containment. In more advanced implementations, automation technologies can initiate initial response actions without human intervention, such as isolating affected systems or disabling compromised accounts. This combination of automation and structured guidance creates a hybrid response model that maximizes both speed and accuracy.
However, the effectiveness of incident response playbooks depends heavily on continuous refinement and adaptation. Cyber threats are not static; they evolve in complexity, technique, and scale. As a result, playbooks must be treated as living documents that are regularly updated based on new threat intelligence, post-incident analysis, and operational feedback. Organizations that fail to maintain their playbooks risk relying on outdated procedures that may no longer be effective against modern attack methods. Continuous improvement ensures that response strategies remain aligned with current threat landscapes and technological environments.
Training and simulation exercises also play a crucial role in ensuring that playbooks remain practical and usable. It is not sufficient for teams to simply have access to documented procedures; they must also be familiar with how to execute them under realistic conditions. Simulation exercises such as tabletop scenarios or controlled incident drills provide opportunities for teams to practice response workflows, identify gaps, and improve coordination. These exercises help reinforce procedural knowledge and ensure that responders can act effectively even under pressure. They also expose weaknesses in communication structures, role definitions, and escalation mechanisms, allowing organizations to refine their playbooks accordingly.
Another important dimension of incident response playbooks is their contribution to knowledge retention and organizational learning. Each incident provides valuable insights into system vulnerabilities, attacker behavior, and response effectiveness. Without structured documentation and review processes, this knowledge can be lost once an incident is resolved. Playbooks ensure that lessons learned are systematically captured and integrated into future response strategies. This creates a feedback loop in which each incident contributes to improved future performance, gradually increasing the maturity of the organization’s cybersecurity posture.
In addition to technical and operational benefits, playbooks also strengthen communication discipline during incidents. Security events often require coordination between multiple stakeholders, including technical teams, management, legal departments, and external entities. Without structured communication protocols, information can become inconsistent or delayed, leading to confusion and misaligned decision-making. Playbooks define clear communication pathways and escalation rules, ensuring that the right information reaches the right stakeholders at the right time. This structured communication reduces uncertainty and supports coordinated decision-making during critical events.
Ultimately, incident response playbooks represent a convergence of technology, process, and governance. They are not simply operational checklists but strategic tools that define how organizations respond to adversity in digital environments. Their value extends beyond immediate incident handling to include long-term improvements in resilience, compliance, and operational maturity. Organizations that invest in developing, maintaining, and practicing effective playbooks are better positioned to manage cyber risk, maintain business continuity, and adapt to an increasingly complex threat landscape.