In modern IT infrastructure, reliability is not optional but a fundamental requirement for any organization that depends on digital services. Networks today support business operations, communication systems, data processing, virtualization platforms, and application delivery. When these services become unavailable, even for a short time, the impact can range from minor inconvenience to major operational disruption. High availability is the architectural principle designed to eliminate single points of failure and ensure that services remain continuously accessible even when components fail. It focuses on maintaining uptime, minimizing downtime, and ensuring consistent performance under both normal and failure conditions. In enterprise environments, high availability is typically measured in uptime percentages, where systems are expected to remain operational for extremely high durations throughout the year. Achieving this level of reliability requires more than a single server or isolated system. It requires coordinated infrastructure that can detect failures, recover automatically, and continue delivering services without user interruption. This is where clustering technologies become essential.
What High Availability Means in Networking Environments
High availability refers to a system design approach that ensures the continuous operation of services by eliminating single points of failure. Instead of relying on one machine to handle all workloads, high availability systems distribute responsibilities across multiple components. These components work together in a coordinated manner to ensure that if one part fails, another can immediately take over. The goal is to maintain service continuity without noticeable disruption to users or applications. In networking environments, high availability is often implemented through redundancy, load distribution, and automated recovery mechanisms. Redundancy ensures that backup systems are always available. Load distribution balances workloads across multiple systems to prevent overload. Automated recovery mechanisms detect failures and initiate corrective actions without human intervention. Together, these principles create an environment where services remain operational even under adverse conditions. High availability is not limited to hardware but also extends to software, network connectivity, and storage systems. Every layer of the infrastructure must be designed to support continuity in order to achieve true resilience.
Introduction to High Availability Clusters
High availability clusters are a structured approach to implementing redundancy and fault tolerance in IT systems. A cluster is a group of interconnected computers, known as nodes, that work together as a unified system. Each node in the cluster is capable of running services and applications, and all nodes participate in monitoring the health of the system. The primary objective of a cluster is to ensure that services remain available even if one or more nodes fail. This is achieved by distributing workloads across multiple nodes and enabling automatic failover when a failure occurs. In a clustered environment, applications are not tied to a single physical server. Instead, they are assigned to a cluster role that can move between nodes as needed. This flexibility ensures that services can continue running even when hardware or software issues arise. High-availability clusters are widely used in enterprise environments where downtime is unacceptable. They provide resilience for critical systems such as databases, file servers, virtualization hosts, and application platforms. The strength of a cluster lies in its ability to behave as a single logical system while being composed of multiple independent machines working together.
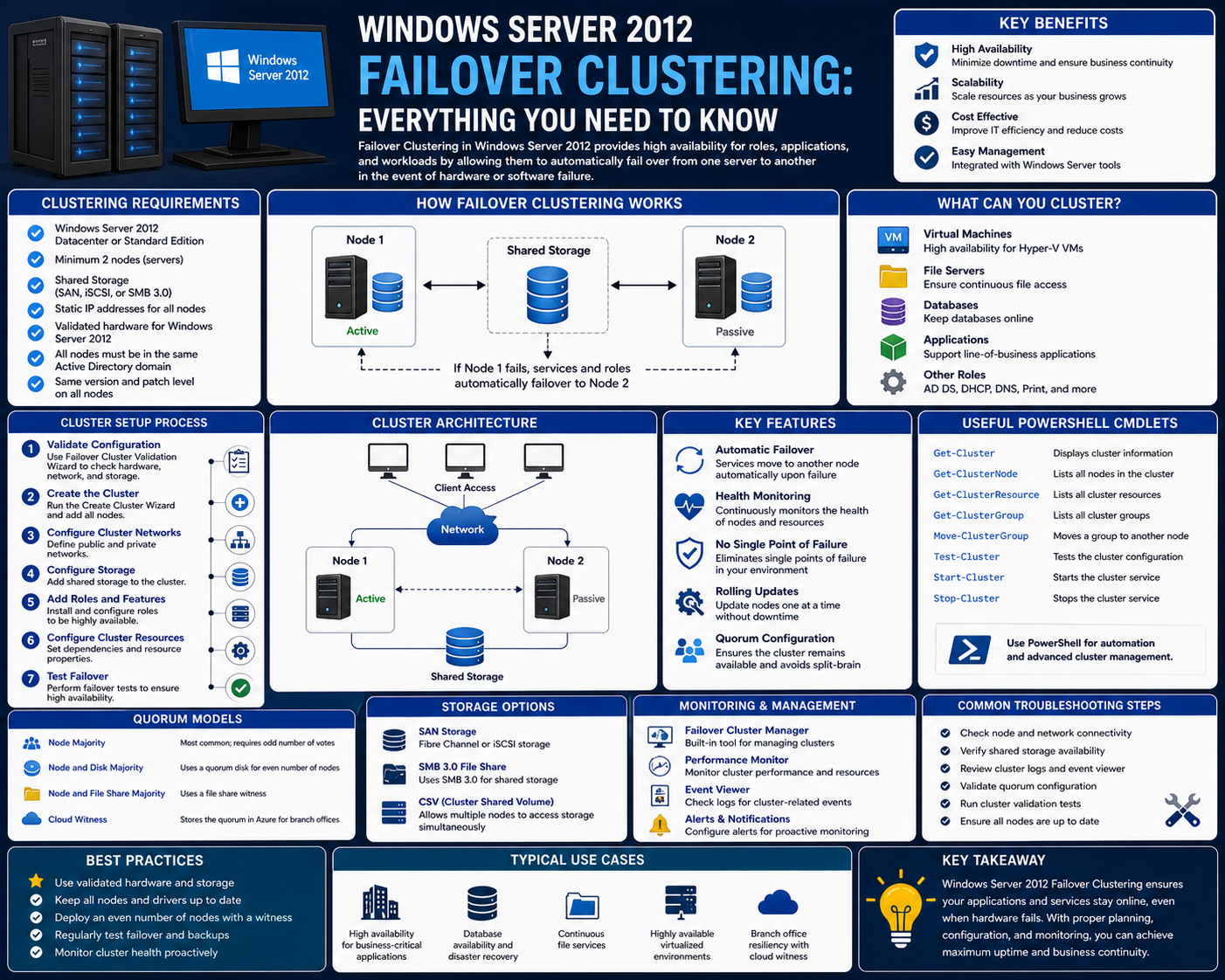
Failover Clustering in Windows Server 2012 Overview
Failover clustering in Windows Server 2012 is Microsoft’s implementation of high-availability clustering technology. It allows multiple servers to work together to maintain the continuous availability of applications and services. Each server in the cluster is referred to as a node, and these nodes collaborate to host workloads and monitor system health. The primary purpose of failover clustering is to ensure that services remain operational even if one node fails or becomes unavailable. Windows Server 2012 introduced significant improvements to clustering technology, making it more stable, scalable, and easier to manage. It enhanced support for virtualized workloads and improved integration with storage systems and networking components. In this environment, clustered services are configured as roles, which can be moved between nodes depending on availability. The system continuously monitors node health and initiates failover automatically when a failure is detected. This ensures minimal disruption to users and applications. Failover clustering in Windows Server 2012 is designed to support enterprise workloads that require high reliability, including file services, database systems, and virtual machine hosting.
Core Architecture of Failover Clustering
The architecture of failover clustering in Windows Server 2012 is built around multiple key components that work together to provide resilience. The most fundamental component is the node, which is an individual server participating in the cluster. Each node is configured with similar hardware and software to ensure compatibility and consistency across the cluster. Nodes are connected through dedicated network interfaces that allow them to communicate and monitor each other’s health. Another critical component is shared storage, which provides centralized access to data for all nodes in the cluster. This shared storage ensures that applications can access the same data regardless of which node is actively hosting them. The cluster also includes a management layer that coordinates resource allocation, monitors system health, and controls failover operations. Communication between nodes is maintained through a heartbeat mechanism, where each node sends regular signals to confirm its operational status. If a node stops responding, it is marked as failed, and its workloads are transferred to another node. This architecture ensures that the cluster operates as a unified system rather than a collection of independent servers.
Role of Nodes in a Cluster Environment
Nodes are the building blocks of a failover cluster. Each node is a fully functional server capable of hosting applications and services independently. However, in a clustered environment, nodes work together to provide redundancy and load balancing. Each node participates in monitoring the health of other nodes through continuous communication. Nodes are also responsible for hosting cluster roles, which represent the services or applications running within the cluster. When a role is assigned to a node, that node becomes responsible for delivering the associated service to users. However, this assignment is not permanent. Roles can be transferred to other nodes if the current node fails or requires maintenance. This dynamic assignment of roles is what enables failover clustering to provide high availability. Nodes must be configured with compatible hardware and software to ensure that roles can be transferred seamlessly without compatibility issues. The coordination between nodes is essential for maintaining system stability and ensuring that workloads are distributed efficiently across the cluster.
Shared Storage and Data Consistency in Clusters
Shared storage is a critical component of failover clustering because it ensures data consistency across all nodes. In a clustered environment, applications rely on centralized storage that is accessible to every node. This means that when a role moves from one node to another, it continues to access the same data without interruption. Shared storage systems are typically implemented using technologies such as iSCSI or Fibre Channel, which allow multiple servers to access the same storage devices simultaneously. This centralized approach eliminates the risk of data inconsistency and ensures continuity during failover events. Shared storage also simplifies management because administrators do not need to replicate data across multiple servers manually. Instead, all nodes access a single source of truth. In Windows Server 2012 failover clustering, shared storage plays a vital role in enabling seamless workload migration and maintaining application integrity during node transitions.
Cluster Communication and Health Monitoring
Communication between nodes is essential for maintaining the stability and reliability of a failover cluster. Each node continuously exchanges health information with other nodes through a process known as heartbeat communication. These signals are used to determine whether a node is operational and responsive. If a node fails to send or receive heartbeat signals within a defined timeframe, it is considered unresponsive. This triggers the cluster to initiate failover procedures. Health monitoring ensures that failures are detected quickly and accurately, allowing workloads to be transferred before users experience service disruption. In addition to heartbeat signals, nodes also exchange configuration data and status updates to maintain synchronization across the cluster. This constant communication ensures that all nodes have up-to-date information about the state of the cluster and can respond appropriately to changes in system conditions.
Cluster Roles and Workload Management
Cluster roles represent the services and applications that are hosted within a failover cluster. Each role is assigned to a specific node but is not permanently bound to it. Instead, roles are designed to be mobile and can move between nodes depending on system conditions. This flexibility allows the cluster to maintain service availability even when individual nodes fail. Common examples of cluster roles include file services, database services, and virtual machines. When a role is active on a node, that node handles all requests associated with the service. If the node becomes unavailable, the role is automatically transferred to another node in the cluster. This process is managed by the cluster software, which ensures that workloads are distributed efficiently and failover occurs smoothly. The use of roles provides a structured way to manage services within the cluster and ensures that applications remain accessible under all conditions.
Virtualization and Service Abstraction in Clustering
Failover clustering in Windows Server 2012 uses abstraction techniques to separate services from physical hardware. This means that applications are not directly tied to a specific server but are instead associated with virtual identities. These virtual identities include network names and IP addresses that remain consistent regardless of which node is hosting the service. This abstraction allows users and applications to connect to services without needing to know the physical location of the underlying resources. When a failover occurs, the virtual identity remains unchanged, ensuring seamless connectivity. This design principle is essential for maintaining transparency in clustered environments and preventing service disruption during transitions.
Deep Dive Into Failover Cluster Architecture
Failover clustering in Windows Server 2012 is built on a layered architecture designed to ensure continuous service availability through coordination between multiple physical servers. At its core, the architecture consists of nodes, shared storage, cluster networking, cluster services, and a resource management layer that governs how workloads are assigned and transferred. Each of these components plays a specific role in maintaining system stability and enabling automated recovery from failures. The cluster is not simply a collection of servers working independently, but a tightly integrated system that behaves as a single logical computing unit. This abstraction is what allows applications and services to remain operational even when individual hardware components fail.
Nodes form the foundation of the architecture. Each node is a fully functional server that participates in the cluster by hosting workloads and monitoring the health of other nodes. These nodes are configured with consistent operating system versions, similar hardware capabilities, and synchronized cluster software. This uniformity is essential because it ensures that workloads can be moved between nodes without compatibility issues. The cluster treats all nodes as potential hosts for any workload, which creates flexibility and redundancy.
Above the node layer sits the cluster service, which acts as the coordination engine for the entire system. This service is responsible for maintaining cluster state, managing communication between nodes, detecting failures, and orchestrating failover operations. It continuously evaluates the health of each node using heartbeat signals and other monitoring mechanisms. If a node becomes unresponsive, the cluster service initiates recovery procedures to maintain service continuity.
The architecture also includes a resource management layer. This layer defines how applications, services, and workloads are grouped and managed within the cluster. These groupings are known as roles, and they represent the functional units of the cluster. Each role contains the resources required to run a service, including network configuration, storage access, and application-specific settings. The resource manager ensures that roles are assigned to appropriate nodes and can be moved when necessary.
Node Communication and Cluster Membership
Communication between nodes is a critical aspect of failover clustering. Nodes continuously exchange information to confirm their operational status and maintain cluster membership. This communication is primarily achieved through heartbeat signals, which are small packets of data sent at regular intervals. These signals allow each node to verify that other nodes are still active and responsive.
If a node fails to send heartbeat signals within a defined threshold, it is considered to be in a failed state. This triggers the cluster to remove it from active membership and redistribute its workloads to remaining nodes. This process is essential for maintaining cluster integrity and ensuring that failed nodes do not disrupt overall system performance.
Cluster membership is dynamic and can change based on node availability. When a node joins the cluster, it undergoes a validation process to ensure compatibility with existing nodes. Once validated, it becomes part of the cluster and can participate in hosting roles. Similarly, when a node leaves or fails, the cluster automatically adjusts its configuration to reflect the change. This dynamic membership system allows the cluster to adapt to changing conditions without manual intervention.
Communication between nodes is typically separated into multiple networks to improve reliability and performance. One network may be dedicated to client traffic, another to storage communication, and another to internal cluster communication. This segmentation ensures that critical cluster operations are not affected by external network traffic or congestion.
Shared Storage Architecture and Data Handling
Shared storage is one of the most important components of failover clustering. It provides a centralized location where all cluster nodes can access application data and system files. This ensures that when a workload moves from one node to another, it continues to operate using the same data without interruption.
In Windows Server 2012, shared storage is typically implemented using technologies such as iSCSI, fiber channel, or Serial Attached SCSI. These technologies allow multiple servers to connect to the same storage devices simultaneously. The storage system appears as a unified resource to all nodes in the cluster, even though it may be physically distributed.
One of the key benefits of shared storage is data consistency. Since all nodes access the same storage location, there is no need for data replication between servers. This eliminates the risk of data mismatch and simplifies management. It also ensures that failover operations can occur instantly because the new node already has access to the required data.
Clustered Shared Volumes is an important feature introduced in Windows Server environments that enhances storage flexibility. It allows multiple nodes to access the same volume concurrently while maintaining data integrity. This is particularly useful for virtualization workloads, where virtual machines may need to move between nodes without downtime.
Storage pools also play a role in modern clustering environments. They allow physical disks to be grouped into logical units that can be dynamically managed. This provides flexibility in allocating storage resources and simplifies scaling as storage demands increase.
Cluster Networks and Traffic Segmentation
Networking in a failover cluster is designed to support multiple types of communication simultaneously. Different types of traffic are separated into distinct networks to improve performance and reliability. This segmentation ensures that critical cluster functions are not affected by external traffic loads.
Client networks handle communication between users and services hosted within the cluster. These networks carry application requests, file access operations, and other user interactions. Storage networks are dedicated to communication between nodes and shared storage systems. These networks handle data transfer operations and must be highly reliable to prevent performance bottlenecks.
Internal cluster networks are used for heartbeat communication and coordination between nodes. These networks are critical for maintaining cluster health and detecting failures. Because of their importance, they are typically isolated from external traffic to ensure stability.
The separation of network roles improves fault tolerance. If one network experiences issues, other networks can continue functioning independently. This layered communication model enhances overall system resilience and ensures that cluster operations remain unaffected by localized network problems.
Cluster Resource Management and Role Assignment
Resource management in failover clustering is based on the concept of roles. A role represents a service or application that runs within the cluster environment. Each role is composed of multiple resources, including network configurations, storage access points, and application components.
When a role is assigned to a node, that node becomes responsible for hosting the service. The cluster service ensures that all required resources are available on the selected node before activating the role. This includes verifying storage accessibility and network connectivity.
Roles are not permanently tied to specific nodes. They can be moved between nodes based on availability, performance, or administrative actions. This flexibility allows the cluster to adapt to changing conditions and maintain service continuity.
Role ownership can change automatically during failover events or manually during maintenance operations. When a role moves to a new node, the cluster ensures that all dependencies are transferred correctly and that the service resumes without interruption.
Heartbeat Mechanism and Failure Detection
The heartbeat mechanism is central to failure detection in failover clustering. It operates by sending periodic signals between nodes to confirm that each node is operational. These signals are lightweight and frequent, allowing the cluster to detect failures quickly.
If a node fails to respond within a defined timeframe, it is marked as unresponsive. The cluster then initiates recovery procedures, which include removing the node from active membership and redistributing its workloads to other nodes.
Heartbeat communication is typically implemented over dedicated networks to ensure reliability. This prevents false failure detection caused by network congestion or delays. The system is designed to distinguish between actual node failure and temporary communication issues.
Failure detection is not limited to complete node failure. It can also detect service-level failures, where a node is still operational but a specific application or service has become unresponsive. In such cases, the cluster can restart or relocate the affected service without affecting other workloads.
Failover Process and Workload Migration
Failover is the process of transferring workloads from a failed or unavailable node to another operational node in the cluster. This process is fully automated and designed to minimize service disruption. When a failure is detected, the cluster evaluates available nodes and selects the most suitable candidate to take over the workload.
The selected node must have sufficient resources and access to shared storage to support the workload. Once the node is selected, the cluster initiates the transfer of role ownership. The application or service is then restarted on the new node using the same configuration and data.
Workload migration is designed to be seamless from the user perspective. Because services are accessed through virtual identities such as network names and IP addresses, users do not experience any change during the transition. The underlying physical infrastructure changes, but the service endpoint remains consistent.
In virtualized environments, failover clustering supports live migration, which allows virtual machines to be moved between nodes without downtime. This enhances flexibility and allows maintenance operations to be performed without service interruption.
Cluster Stability and Recovery Behavior
Cluster stability depends on continuous monitoring and rapid recovery mechanisms. When a node fails, the cluster must quickly redistribute workloads to prevent service disruption. This requires accurate failure detection and efficient resource allocation.
Recovery behavior includes restarting services on new nodes, re-establishing network connections, and verifying storage access. The cluster ensures that all dependencies are satisfied before activating workloads on a new node.
Once a failed node becomes available again, it can rejoin the cluster. Depending on the configuration, workloads may be moved back to the original node through a process known as failback. This helps restore the intended workload distribution and optimize resource usage across the cluster.
Understanding Cluster Roles and Their Importance
In Windows Server 2012 failover clustering, roles are the fundamental building blocks that define how services and applications are delivered within a clustered environment. A role represents a complete workload package that includes all the components required to run a specific service, such as network configuration, storage dependencies, and application settings. Instead of binding applications directly to a physical server, failover clustering abstracts them into roles that can be dynamically assigned to any node in the cluster. This abstraction is what enables high availability, because it removes the dependency on a single machine and allows workloads to move freely across multiple servers.
Each role is designed to function independently of the underlying hardware. This means that whether a role is running on Node A or Node B, the service behaves the same way from the perspective of users and applications. Roles can represent a wide range of services, including file servers, database systems, application services, and virtual machines. The key idea is that the cluster treats each role as a mobile unit that can be relocated based on system conditions.
Roles are assigned to nodes based on resource availability and configuration policies. Once assigned, a node becomes the active owner of that role and is responsible for handling all requests associated with it. However, ownership is not permanent. If the node becomes unavailable or experiences performance issues, the role can be transferred to another node in the cluster. This flexibility ensures that services remain continuously available even when infrastructure conditions change.
Role Ownership and Resource Dependencies
Each role in a failover cluster consists of multiple resources that must work together for the service to function correctly. These resources include storage components, network identities, and application-specific services. The cluster ensures that all dependencies are satisfied before a role is brought online on a node.
Storage dependencies are particularly important because they ensure that applications have access to consistent data regardless of which node is hosting the role. In a clustered environment, shared storage is used to store application data so that it remains accessible to all nodes. When a role moves between nodes, it continues to use the same storage location, ensuring continuity.
Network dependencies include virtual IP addresses and network names that allow users and applications to connect to services without needing to know the physical location of the node. These virtual identities remain consistent even when the role moves between nodes, which is essential for maintaining seamless connectivity.
Application dependencies refer to the services or executables that must be running for the role to function properly. The cluster ensures that these components are initialized correctly during failover or startup operations. If any dependency fails, the role is not brought online until the issue is resolved.
Failover Process in Detail
Failover is the automated process that occurs when a node hosting a role becomes unavailable. This can happen due to hardware failure, software issues, network disruption, or administrative actions such as maintenance. When the cluster detects that a node is no longer responsive, it immediately begins the failover process to ensure service continuity.
The first step in failover is failure detection. The cluster continuously monitors nodes using heartbeat signals and health checks. If a node fails to respond within a predefined timeframe, it is marked as failed. Once failure is confirmed, the cluster removes the node from active participation and begins redistributing its workloads.
The next step is resource reallocation. The cluster evaluates all available nodes to determine which one is best suited to host the affected roles. This decision is based on resource availability, current load, and predefined policies. Once a target node is selected, the role is transferred to that node.
During the transfer, the new node takes ownership of all role resources, including storage connections and network identities. The application or service is then restarted on the new node using the same configuration. Because shared storage is used, the new node immediately has access to all necessary data.
From the user perspective, failover is designed to be transparent. Applications continue to function without requiring manual reconnection or reconfiguration. This seamless transition is one of the key benefits of failover clustering.
Failback Mechanisms and Workload Redistribution
Failback is the process of returning a role to its original node after a failure has been resolved. When a failed node comes back online, it rejoins the cluster and becomes eligible to host roles again. Depending on cluster configuration, roles may automatically move back to their preferred nodes or remain on their current nodes.
Failback can be configured as automatic or manual. In automatic failback, the cluster moves roles back to their preferred nodes once they become available. In manual failback, administrators control when and how roles are moved. This provides flexibility in managing workloads and ensures that changes do not disrupt active services.
Workload redistribution is not limited to failure scenarios. Administrators can also move roles between nodes for maintenance, performance optimization, or load balancing. This process is known as live migration when applied to virtual machines. It allows workloads to be shifted without downtime, improving operational flexibility.
Cluster Manager Interface and Administrative Control
Windows Server 2012 provides a centralized management interface for configuring and monitoring failover clusters. This interface allows administrators to view cluster nodes, roles, storage systems, and network configurations in a structured format. It also provides real-time information about system health and performance.
The interface is organized into multiple sections, each focusing on a specific aspect of cluster management. The roles section displays all active workloads and their current host nodes. The nodes section shows the status of each server in the cluster. The storage section provides information about shared disks and volumes. The network section displays communication paths between nodes.
Administrators can use this interface to perform a wide range of tasks, including creating new roles, moving workloads, configuring storage, and monitoring system events. It also provides tools for troubleshooting cluster issues and analyzing failure events.
Cluster Events and Monitoring Systems
Monitoring is a critical component of failover clustering. The system continuously records events related to node health, role status, and network communication. These events are stored in a centralized log that can be accessed through the management interface.
Cluster events provide detailed information about system behavior, including warnings, errors, and informational messages. These logs help administrators identify potential issues before they lead to failures. For example, repeated communication delays between nodes may indicate network congestion or hardware problems.
Event monitoring also plays a role in automated decision-making. The cluster uses event data to determine whether a node should remain active or be marked as failed. This ensures that decisions are based on real system behavior rather than static assumptions.
Storage Behavior During Failover
Storage plays a central role in maintaining continuity during failover operations. Because all nodes in a cluster access shared storage, data remains consistent regardless of which node is active. When a role moves from one node to another, it continues using the same storage location without requiring data replication or transfer.
Clustered storage systems are designed to handle concurrent access from multiple nodes. This allows workloads to be distributed efficiently and ensures that data remains available even during node transitions. In virtualized environments, storage systems also support clustered shared volumes, which enable multiple nodes to access the same volume simultaneously.
Storage consistency is maintained through locking mechanisms and coordination protocols that prevent conflicts between nodes. These mechanisms ensure that only one node has active control over a specific resource at any given time, preventing data corruption.
Network Identity and Virtual Access Layers
One of the most important features of failover clustering is the use of virtual network identities. These identities allow services to be accessed independently of the physical node hosting them. Each role is assigned a virtual IP address and network name that remains constant regardless of where the role is running.
This abstraction layer ensures that users and applications do not need to know the physical location of services. When a failover occurs, the virtual identity is transferred to the new node along with the role. This allows connections to continue without interruption.
The use of virtual identities is essential for maintaining transparency in clustered environments. It ensures that failover operations are invisible to end users and applications.
Live Migration and Virtual Workload Mobility
In virtualized environments, failover clustering supports live migration of virtual machines. This allows virtual workloads to be moved between nodes without shutting down or interrupting services. Live migration is particularly useful for maintenance operations, load balancing, and system optimization.
During live migration, the state of a virtual machine is transferred from one node to another while it continues running. This includes memory state, processor state, and storage connections. Once the transfer is complete, the virtual machine resumes execution on the new node without any downtime.
Live migration enhances flexibility and allows administrators to perform maintenance tasks without affecting service availability. It also improves resource utilization by allowing workloads to be distributed dynamically across the cluster.
Operational Behavior and Real-World Cluster Dynamics
In real-world environments, failover clusters operate continuously under varying conditions. Nodes may experience fluctuating loads, network variations, and hardware stress. The cluster is designed to adapt to these conditions dynamically.
Workloads are balanced across nodes to ensure optimal performance. If one node becomes overloaded, roles can be redistributed to maintain stability. Similarly, if a node becomes underutilized, it can take on additional workloads.
The system also adapts to maintenance activities. Administrators can move roles between nodes before performing updates or hardware changes. This ensures that services remain available during planned downtime.
In enterprise environments, failover clustering is often integrated with virtualization platforms, storage systems, and network infrastructure to create a fully resilient computing environment. This integration allows organizations to maintain continuous service delivery even under complex operational conditions.
Conclusion
Failover clustering in Windows Server 2012 represents one of the most important architectural approaches for achieving high availability in enterprise computing environments. At its core, it is not just a feature but a complete framework for ensuring that critical services remain operational even in the presence of hardware failures, software issues, or planned maintenance activities. In modern IT infrastructure, where downtime can lead to significant operational and financial impact, the importance of such resilience cannot be overstated. Failover clustering provides a structured and automated way to eliminate single points of failure and maintain continuity across complex systems.
The strength of failover clustering lies in its ability to transform a group of independent servers into a unified and coordinated system. Instead of relying on a single machine to host applications, workloads are distributed across multiple nodes that continuously monitor each other’s health. This design ensures that if one node fails, another can immediately take over without requiring manual intervention. The transition is managed automatically through built-in cluster services that detect failures using heartbeat communication and trigger recovery processes in real time.
One of the most important outcomes of this design is service continuity. From the perspective of users and applications, services remain accessible even when the underlying infrastructure changes. This is achieved through abstraction layers such as virtual network names and IP addresses, which decouple services from physical hardware. As a result, users connect to a stable endpoint while the cluster dynamically manages where the service is actually running. This separation between logical service identity and physical infrastructure is a key principle that makes failover clustering effective.
Another critical advantage of failover clustering is its support for shared storage systems. By centralizing data access, the cluster ensures that all nodes have consistent and immediate access to application data. This eliminates the need for complex data replication mechanisms between servers and reduces the risk of inconsistencies. When a failover occurs, the new node can immediately access the same storage resources, allowing the service to resume almost instantly. This design significantly reduces recovery time and improves overall system reliability.
The concept of roles within a cluster further enhances flexibility and manageability. Each service or application is packaged as a role, which can be assigned, moved, or redistributed across nodes depending on system conditions. This modular approach allows administrators to manage workloads at a higher level of abstraction without dealing with individual hardware dependencies. Roles can be dynamically reassigned during failover events or manually moved for maintenance and optimization purposes. This flexibility ensures that infrastructure can adapt to changing demands without disrupting service availability.
Failover clustering also plays a crucial role in virtualization environments. With the increasing adoption of virtual machines in enterprise systems, the ability to move workloads between physical hosts without downtime has become essential. Windows Server 2012 integrates clustering with virtualization technologies, allowing virtual machines to be migrated between nodes seamlessly. This capability enables maintenance operations, hardware upgrades, and load balancing without affecting running services. It also improves resource utilization by allowing workloads to be distributed dynamically based on system performance and availability.
From an operational perspective, failover clustering introduces a proactive approach to system management. Instead of reacting to failures after they occur, the system continuously monitors health indicators and takes corrective action when anomalies are detected. This includes not only complete node failures but also partial service degradation and performance issues. By identifying potential problems early, the cluster reduces the likelihood of service disruption and improves overall system stability.
The role of cluster management tools in Windows Server 2012 is also significant. These tools provide administrators with a centralized interface for monitoring, configuring, and controlling cluster behavior. Through this interface, administrators can view node status, manage roles, configure storage, and analyze system events. This centralized visibility simplifies complex infrastructure management and allows for more efficient decision-making. It also provides detailed insights into system behavior, helping administrators identify trends and potential issues before they escalate.
Network design within failover clusters further contributes to reliability. By separating different types of traffic into dedicated networks, the system ensures that critical communication channels remain unaffected by external load. Heartbeat communication, storage traffic, and client requests are handled independently, reducing congestion and improving performance. This segmentation enhances fault tolerance and ensures that even if one network segment experiences issues, the overall cluster remains operational.
Despite its complexity, failover clustering is ultimately designed to simplify high availability for enterprise systems. It abstracts many of the challenges associated with redundancy, failover detection, and workload migration into an automated system that operates continuously in the background. This allows organizations to focus on service delivery rather than infrastructure maintenance. However, proper planning and configuration are still essential to ensure optimal performance and reliability.
In real-world environments, failover clustering is widely used in scenarios where uptime is critical. This includes database systems, file storage platforms, virtualization infrastructure, and enterprise applications. These systems require continuous availability, and even short periods of downtime can have significant consequences. By providing automated failover capabilities and seamless workload migration, clustering ensures that these services remain operational under all conditions.
The introduction of failover clustering in Windows Server 2012 marked a significant improvement in Microsoft’s approach to high availability. Enhancements in stability, scalability, storage integration, and virtualization support made it more accessible and efficient for enterprise deployment. These improvements allowed organizations to build more resilient infrastructures without requiring overly complex configurations or specialized hardware.
Ultimately, failover clustering represents a shift in how infrastructure resilience is achieved. Instead of relying on isolated systems with manual recovery processes, modern environments use coordinated clusters that operate as unified systems. This approach not only improves reliability but also enhances scalability, flexibility, and operational efficiency. It allows organizations to respond dynamically to failures, maintenance requirements, and changing workloads without disrupting service delivery.
As IT environments continue to evolve, the principles behind failover clustering remain highly relevant. The need for continuous availability, automated recovery, and distributed workloads continues to grow as systems become more complex and interconnected. Failover clustering provides a foundational model for addressing these challenges and remains a key component in building resilient enterprise infrastructure.