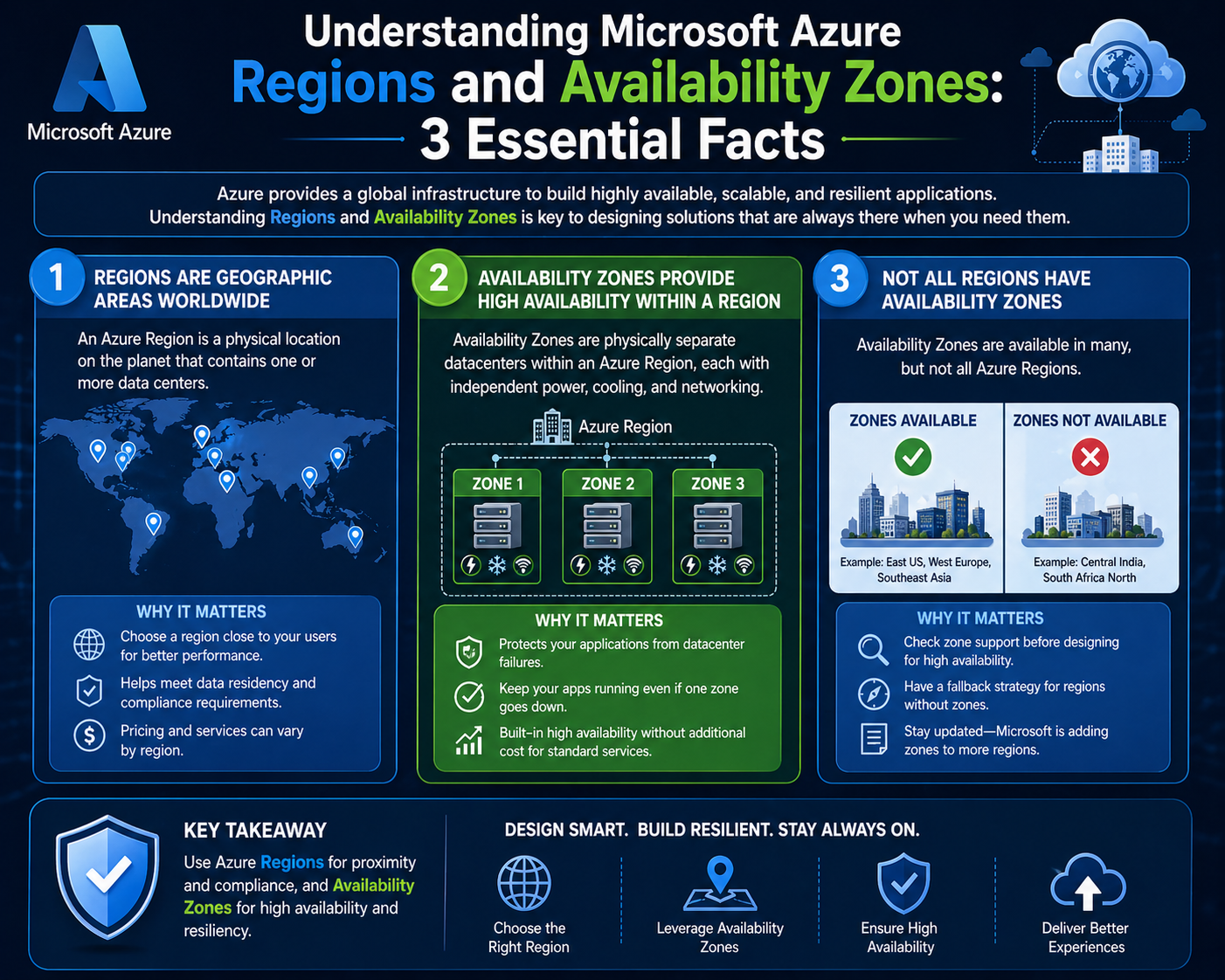
Microsoft Azure regions represent the foundational geographic units of one of the largest cloud computing ecosystems in the world. Each region is a carefully engineered collection of physically separate data centers that operate together as a single logical unit. These regions are distributed across continents to provide global coverage, enabling organizations to deploy applications, services, and workloads closer to their end users while maintaining performance, compliance, and resilience requirements.
At a structural level, an Azure region is not a single facility but a cluster of multiple data centers located within a defined geographic boundary. These facilities are interconnected using high-speed, low-latency networking infrastructure designed to support massive data throughput and distributed computing workloads. The architecture ensures that if one data center within a region experiences disruption, other facilities within the same region can continue operating without service interruption.
The design of regions reflects a balance between physical geography, regulatory constraints, and technical performance requirements. Microsoft strategically selects locations based on factors such as population density, enterprise demand, legal frameworks, energy availability, and proximity to major internet exchange points. This ensures that each region can support both current and future cloud computing demands while maintaining operational efficiency.
Azure regions also serve as the primary deployment boundary for most cloud services. When a virtual machine, database, or application service is created, it is assigned to a specific region. This decision determines where the underlying infrastructure resides and directly influences latency, compliance, and redundancy capabilities.
How Azure Regions Support Performance and Latency Optimization
One of the most critical functions of Azure regions is minimizing network latency between users and cloud-hosted services. Latency refers to the time it takes for data to travel between a client and a server and back again. Even small delays can significantly impact application performance, particularly in real-time systems such as financial trading platforms, video conferencing, gaming environments, and large-scale transactional systems.
By placing data centers closer to end users, Azure reduces the physical distance that data must travel. Although modern fiber-optic networks transmit data at extremely high speeds, physical distance still introduces measurable delays. For example, a request traveling across a few hundred miles may only experience milliseconds of delay, but when multiplied across thousands of requests per second, this delay becomes significant.
Azure regions are strategically distributed to reduce these latency impacts. In addition to geographic placement, Microsoft optimizes routing through its global backbone network, which interconnects all Azure regions. This backbone allows traffic to travel through optimized pathways rather than relying solely on public internet routes, further improving performance consistency.
Latency optimization is not only about distance but also about architectural design. Applications deployed within the same region benefit from intra-region communication, which is significantly faster than cross-region communication. This is why modern cloud architectures often emphasize region-specific deployments for tightly coupled services.
The Structural Reason Behind Azure Region Pairing
A defining characteristic of Azure’s global infrastructure is the concept of region pairing. Every Azure region is associated with another region within the same geographic area, forming a structured redundancy model. This pairing is not incidental; it is a deliberate architectural decision designed to enhance resilience, disaster recovery, and compliance alignment.
Region pairs are geographically separated to ensure that a single catastrophic event does not affect both regions simultaneously. This separation might involve hundreds of miles of distance, depending on the geography. Despite this separation, paired regions are still close enough to allow efficient data replication and synchronization when required.
The primary purpose of region pairing is to provide a built-in disaster recovery mechanism. In traditional IT infrastructure, organizations must manually design and configure backup systems across different locations. Azure simplifies this process by offering predefined region relationships that are already optimized for recovery scenarios.
When data is replicated across paired regions, it ensures continuity of operations in the event of regional failure. This replication can include databases, storage systems, and application states, depending on the configuration. The system is designed so that if one region becomes unavailable, services can be restored in the paired region with minimal disruption.
Region pairing also helps manage platform updates and maintenance operations. Microsoft often staggers updates between paired regions to reduce the risk of simultaneous outages. This approach ensures that at least one region remains stable during infrastructure changes.
Redundancy as a Core Principle in Azure Architecture
Redundancy is a foundational principle in Azure’s design philosophy. In traditional IT environments, redundancy typically refers to duplicating hardware components such as servers, storage devices, or network connections. In cloud environments like Azure, redundancy extends far beyond hardware and encompasses entire geographic regions, availability zones, and service instances.
At the infrastructure level, Azure incorporates redundancy into every layer of its architecture. Data centers are equipped with multiple power sources, backup generators, redundant cooling systems, and multiple network providers. Within these data centers, compute and storage resources are also duplicated to ensure that no single hardware failure can disrupt service availability.
At a higher level, redundancy is achieved through distribution across availability zones and regions. This multi-layered approach ensures that failures at any single point do not cascade into system-wide outages. Applications can be designed to automatically fail over to backup resources without manual intervention, ensuring continuous availability.
Redundancy in Azure is closely tied to the concept of high availability. High availability refers to the ability of a system to remain operational for extended periods without interruption. Azure achieves this through a combination of infrastructure redundancy, intelligent load balancing, and automated failover mechanisms.
How Availability Zones Enhance Regional Resilience
Within each Azure region, there are additional layers of isolation known as availability zones. These zones are physically separate data center locations within the same region, each with independent power, cooling, and networking infrastructure. The purpose of availability zones is to protect against localized failures that may affect a single data center.
While region pairs protect against large-scale geographic failures, availability zones protect against localized disruptions such as hardware failures, power outages, or environmental incidents. By distributing workloads across multiple zones, organizations can achieve even higher levels of resilience.
Availability zones are interconnected through high-speed, low-latency networks, enabling synchronous or near-synchronous replication of data and services. This ensures that applications remain highly responsive even when operating across multiple zones.
The combination of regions and availability zones creates a hierarchical resilience model. Regions provide geographic redundancy, while availability zones provide intra-regional fault tolerance. Together, they form a comprehensive strategy for maintaining service continuity under a wide range of failure scenarios.
The Role of Capacity Management in Azure Regions
Although cloud computing is often perceived as virtually limitless, the underlying physical infrastructure still imposes capacity constraints. Each Azure region is built based on projected demand, hardware availability, and infrastructure planning cycles. This means that while Azure offers massive scalability, individual regions may experience capacity limitations depending on demand patterns.
Capacity management is a critical aspect of cloud operations. Microsoft continuously monitors resource utilization across regions to ensure that compute, storage, and networking resources remain available. When demand increases significantly in a particular region, additional infrastructure is deployed to expand capacity.
However, capacity is not uniform across all regions. Some regions may support a broader range of services and larger-scale deployments, while others may have limited service availability due to regulatory constraints or infrastructure maturity. This variability requires organizations to carefully evaluate regional capabilities before deploying workloads.
Capacity constraints can also influence deployment strategies. In some cases, workloads may need to be distributed across multiple regions to ensure resource availability. This introduces additional architectural complexity but enhances scalability and resilience.
Geographic Representation and Physical Location of Azure Regions
An important aspect of Azure regions is the distinction between logical naming and physical location. The name of a region often reflects a well-known city or geographic area, but the actual data centers may be located at varying distances from that reference point.
This naming convention is designed to provide users with a general understanding of geographic placement without revealing exact physical locations for security and operational reasons. For example, a region labeled with a major city name may be located tens of miles away from the actual urban center.
This approach allows Microsoft to maintain operational flexibility in selecting optimal data center locations while still providing users with meaningful geographic context. The actual placement of data centers is influenced by factors such as land availability, energy infrastructure, cooling efficiency, and network connectivity.
Despite these variations, the performance impact of such distance differences is minimal in most cases. Modern networking infrastructure ensures that data can travel across short geographic distances with negligible latency, making these differences largely transparent to end users.
Data Sovereignty and Regulatory Compliance in Azure Regions
Data sovereignty is a critical consideration in global cloud computing. It refers to the legal principle that data is subject to the laws of the country in which it is stored or processed. Different countries enforce different regulations regarding data storage, access, and transfer, making compliance a complex challenge for multinational organizations.
Azure regions are designed to address these challenges by providing localized data storage options that align with regional legal requirements. In some jurisdictions, data must remain within national borders, while in others, it may be subject to specific handling or encryption requirements.
To support these requirements, Azure offers specialized regions that are designed to comply with strict regulatory frameworks. These regions may have limited service availability or additional security controls to meet government or industry standards.
Data sovereignty also impacts disaster recovery planning. When replicating data across regions, organizations must ensure that replication remains within permitted geographic boundaries. Azure region pairs are designed with these constraints in mind, enabling compliant replication strategies.
The importance of data sovereignty continues to grow as governments introduce more stringent data protection laws. This trend reinforces the need for cloud platforms to provide flexible yet compliant infrastructure solutions that can adapt to evolving regulatory environments.
Why Azure Region Pairing Exists as a Core Cloud Design Strategy
Azure region pairing is a structural design principle that underpins Microsoft’s approach to global cloud resilience. Each Azure region is paired with another region within the same geopolitical area, forming a deliberately engineered relationship that supports disaster recovery, service continuity, and operational stability. This pairing is not optional or arbitrary; it is embedded into the platform’s architecture to ensure predictable resilience behavior across the entire cloud ecosystem.
The fundamental reason for region pairing is risk isolation. Even though cloud infrastructure is distributed, large-scale disruptions such as natural disasters, power grid failures, or major network outages can still impact entire geographic zones. By pairing regions that are physically separated by a significant distance, Azure reduces the probability that both regions will experience simultaneous failure. This ensures that at least one region in the pair remains operational under extreme conditions.
Region pairing also supports controlled redundancy. Instead of requiring organizations to manually architect multi-region failover systems from scratch, Azure provides a pre-defined structure that simplifies replication planning. This reduces engineering complexity while ensuring that redundancy follows a standardized, best-practice model.
Another important aspect of region pairing is operational independence. Paired regions are designed so that maintenance activities, updates, and infrastructure changes are staggered. This ensures that neither region in a pair changes at the same time, reducing the risk of correlated downtime. This staggered operational model is a key component of Azure’s reliability engineering strategy.
How Data Replication Works Between Paired Regions
Data replication between Azure region pairs is a critical mechanism that ensures continuity of services during outages. Replication can occur at multiple layers, including storage replication, database synchronization, and application-level state replication, depending on the service configuration.
At the storage level, data is often asynchronously replicated to the paired region. This means that changes in the primary region are periodically copied to the secondary region, ensuring that a near-real-time backup exists. This replication model balances performance and resilience, as synchronous replication across large geographic distances would introduce unacceptable latency.
For database systems, replication strategies vary depending on the service type and configuration. Some systems support active-active replication, where both regions can serve traffic simultaneously, while others operate in active-passive mode, where one region serves as a standby. The choice depends on application requirements, consistency needs, and performance considerations.
Application-level replication involves maintaining consistency of application state across regions. This is particularly important for distributed applications that rely on session data, transaction states, or real-time processing pipelines. By replicating this information, Azure ensures that applications can resume operation seamlessly in a secondary region if required.
The replication process is tightly integrated with Azure’s global infrastructure backbone, which provides high-speed connectivity between regions. This backbone ensures that data transfer between paired regions is efficient and reliable, minimizing the risk of replication lag or data inconsistency.
Disaster Recovery Planning Using Azure Region Pairs
Disaster recovery is one of the primary use cases for region pairing in Azure. Traditional disaster recovery strategies often involve complex configurations, manual synchronization processes, and significant infrastructure overhead. Azure simplifies this by providing a built-in geographic redundancy model.
In a disaster recovery scenario, if a primary region becomes unavailable due to a large-scale disruption, services can be failed over to the paired region. This failover process can be automated or manually triggered, depending on the application architecture and recovery requirements.
The goal of disaster recovery in Azure is to minimize both Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO refers to the time required to restore service functionality after an outage, while RPO refers to the amount of data loss that can be tolerated. Region pairing helps reduce both metrics by maintaining continuously synchronized or near-synchronized copies of data in the paired region.
Azure provides tools and services that allow organizations to define recovery strategies based on their specific needs. These strategies can include full application replication, partial service failover, or data-only recovery mechanisms. The flexibility of these options allows organizations to balance cost, complexity, and resilience.
Disaster recovery planning also involves testing failover scenarios. Azure supports controlled testing of region failovers without impacting production systems. This ensures that recovery procedures are validated and reliable before being required in real-world scenarios.
Understanding Capacity Limitations in Cloud Infrastructure
Despite the perception of infinite scalability, cloud platforms such as Azure operate within physical infrastructure constraints. Each region is built on a finite amount of hardware, networking capacity, and power resources. These constraints mean that capacity is a managed and carefully monitored resource.
Capacity planning in Azure is based on forecasting demand patterns and provisioning infrastructure accordingly. Microsoft continuously analyzes usage trends across regions to anticipate future growth and expand infrastructure where necessary. However, sudden spikes in demand can still result in temporary capacity limitations.
These limitations are more visible during high-demand periods or when new services are launched. In such cases, certain regions may temporarily restrict the creation of new resources until additional capacity becomes available. This behavior reflects the underlying reality that cloud systems are still physical systems with finite limits.
Not all regions have identical capacity or service availability. Some regions support a broader range of services due to more mature infrastructure, while others may offer limited capabilities based on regulatory constraints or development stage. This variability requires careful planning when selecting deployment regions.
Capacity constraints also influence architectural decisions. Organizations may need to distribute workloads across multiple regions to ensure the availability of required resources. This introduces additional complexity but improves scalability and resilience.
Historical Evolution of Azure Capacity Challenges
In the early stages of Azure’s global expansion, capacity limitations were more pronounced. As demand for cloud computing grew rapidly, certain regions experienced shortages in compute, storage, and networking resources. This led to temporary restrictions on resource provisioning in affected areas.
Over time, Microsoft responded by significantly expanding its global data center footprint. New regions were added, existing regions were expanded, and infrastructure efficiency was improved through advancements in virtualization and resource management.
Today, Azure operates one of the largest cloud infrastructures in the world, but capacity management remains an ongoing concern. As more organizations migrate to the cloud and adopt high-performance workloads such as artificial intelligence, machine learning, and big data analytics, demand continues to grow.
This growth-driven expansion model ensures that Azure can scale with global demand, but it also means that capacity is never entirely static. Instead, it is continuously evolving based on usage patterns and technological advancements.
Service Variability Across Azure Regions
One important characteristic of Azure’s global infrastructure is that not all services are available in all regions. Service availability depends on several factors, including infrastructure maturity, regulatory compliance, and local demand.
Some regions are considered “feature-rich,” meaning they support a wide range of Azure services, including advanced analytics, artificial intelligence platforms, and specialized compute offerings. Other regions may offer a more limited set of core services.
This variability exists because deploying new services in a region requires significant infrastructure investment and validation. Microsoft typically rolls out new services gradually, starting with select regions before expanding globally.
Service variability has important implications for architectural design. Organizations must carefully evaluate whether a chosen region supports all required services before deploying workloads. In some cases, hybrid or multi-region architectures may be necessary to meet functional requirements.
Geographic Abstraction and Real-World Data Center Placement
Azure region names often correspond to recognizable cities or geographic areas, but the actual physical data centers may be located at varying distances from those reference points. This abstraction is intentional and serves both operational and security purposes.
Data center placement is influenced by multiple factors beyond city boundaries. These include land availability, energy infrastructure, cooling efficiency, regulatory zoning laws, and proximity to network backbone connections. As a result, the physical location of a data center may be outside the core metropolitan area.
Despite this abstraction, performance impact is minimal. Modern network infrastructure ensures that even tens of miles of separation introduce negligible latency for most workloads. In many cases, data transmission over such distances occurs in milliseconds.
The use of geographic labels provides users with a simplified mental model of where their data resides without exposing sensitive operational details. This balance between transparency and security is an important aspect of cloud infrastructure design.
Latency Considerations in Distributed Cloud Systems
Latency remains one of the most important performance factors in distributed cloud systems. Even though Azure uses high-speed networking and global backbones, physical distance still introduces measurable delays in data transmission.
Latency becomes particularly important in applications that require real-time or near-real-time interaction. These include online gaming, financial trading systems, live video streaming, and distributed IoT networks.
To mitigate latency, Azure encourages the deployment of resources as close as possible to end users. This is achieved through region selection, content distribution strategies, and edge computing integration.
Edge computing further reduces latency by processing data closer to its source rather than relying solely on centralized regions. This distributed processing model complements Azure’s regional infrastructure and enhances overall system responsiveness.
Interplay Between Regions, Zones, and Global Network Infrastructure
Azure’s global architecture is built on three interconnected layers: regions, availability zones, and the global network backbone. Each layer serves a distinct purpose in ensuring performance, reliability, and scalability.
Regions provide geographic distribution and compliance boundaries. Availability zones provide intra-regional fault tolerance. The global backbone connects all regions and zones through high-speed, private networking infrastructure.
This layered design allows Azure to support complex workloads that require both local responsiveness and global distribution. Data can be processed locally within a region, replicated across zones for resilience, and synchronized across regions for disaster recovery.
The integration of these layers creates a highly resilient and scalable cloud environment capable of supporting enterprise-grade applications at a global scale.
Azure Regions and the Reality of Global Data Center Geography
Azure regions are often perceived as exact geographic locations tied directly to the cities they are named after, but the actual physical reality is more nuanced. Each region represents a logical grouping of data centers rather than a single fixed site within city limits. The naming convention is primarily designed to provide users with an intuitive geographic reference point rather than a precise physical coordinate.
In practice, the physical data centers that constitute a region may be located outside the urban center referenced in the region name. This is a deliberate design choice driven by multiple operational factors such as land availability, energy efficiency, cooling infrastructure, and proximity to high-capacity fiber networks. Large-scale data centers require significant space and environmental control, which is often more feasible in suburban or rural areas surrounding major cities.
Despite these differences between naming and physical placement, the performance impact is minimal for most workloads. Modern networking infrastructure is capable of transmitting data across tens of miles in milliseconds. As a result, whether a data center is located within a city or several dozen miles away typically has a negligible impact on application responsiveness.
This abstraction between logical region naming and physical infrastructure allows cloud providers to maintain flexibility in expanding infrastructure without being constrained by city boundaries. It also enhances operational security by avoiding unnecessary disclosure of precise facility locations.
How Azure Uses Geographic Abstraction for Infrastructure Planning
Geographic abstraction plays a central role in how Azure designs and communicates its global infrastructure. Rather than exposing exact facility coordinates, Azure uses region names that correspond to recognizable geographic markers. This approach provides a balance between transparency and operational confidentiality.
From an infrastructure planning perspective, geographic abstraction allows Microsoft to optimize data center placement based on technical requirements rather than urban constraints. Factors such as power grid stability, renewable energy access, cooling efficiency, seismic risk, and network topology all influence where data centers are built.
This flexibility ensures that each region can achieve optimal operational efficiency while still being associated with a meaningful geographic identity. It also allows Azure to scale infrastructure in response to demand without being limited by metropolitan real estate constraints.
Geographic abstraction also supports long-term sustainability planning. Data centers consume significant amounts of energy, and their placement often takes into account proximity to renewable energy sources. This helps reduce environmental impact while maintaining performance and reliability standards.
Understanding Latency in Real-World Cloud Applications
Latency is one of the most important performance characteristics in distributed computing environments. It refers to the time delay between a request being sent and a response being received. Even in high-speed cloud networks, latency cannot be eliminated due to physical constraints such as distance and network routing.
In Azure, latency is influenced by several factors, including regional distance, network congestion, routing efficiency, and application architecture. While intra-region communication is highly optimized and typically very fast, cross-region communication introduces additional latency due to increased physical distance and additional network hops.
For most enterprise applications, latency within a region is measured in milliseconds and is often negligible. However, when applications span multiple regions, latency can increase depending on geographic separation. This is why architectural decisions often prioritize keeping tightly coupled services within the same region.
Latency becomes especially important in real-time systems. Applications such as financial trading platforms, multiplayer gaming environments, live streaming services, and IoT control systems require extremely low latency to function effectively. In these scenarios, even small delays can significantly impact user experience or system accuracy.
To mitigate latency, Azure provides multiple optimization mechanisms, including global load balancing, edge computing integration, and content delivery optimization. These systems work together to ensure that user requests are routed through the most efficient path possible.
The Role of Azure’s Global Backbone Network
Azure’s global backbone network is a privately managed high-speed network that connects all Azure regions and data centers worldwide. Unlike public internet routing, which can be subject to congestion and unpredictable paths, the Azure backbone provides optimized routing between cloud resources.
This backbone is critical for enabling efficient cross-region communication. When data needs to move between regions, it is often routed through dedicated network infrastructure rather than public internet pathways. This improves both performance and reliability.
The backbone network also supports large-scale data replication between regions and availability zones. This ensures that data can be synchronized efficiently across geographically distributed systems, enabling disaster recovery and global workload distribution.
One of the key advantages of this network is consistency. Because Microsoft controls the entire infrastructure, it can optimize routing paths dynamically to reduce latency and improve throughput. This level of control is not possible in traditional internet-based communication systems.
How Azure Handles Regional Service Differences
Not all Azure regions provide identical service offerings. Service availability varies depending on infrastructure maturity, regulatory requirements, and regional demand. This means that some regions may support advanced services such as artificial intelligence platforms, machine learning tools, or specialized analytics capabilities, while others may only support core compute and storage services.
This variability exists because deploying services into a region requires significant infrastructure investment, validation, and compliance alignment. New services are often introduced gradually, starting in select regions before expanding globally.
For organizations, this means that region selection is not only about geography but also about service capability. Choosing a region requires evaluating whether all required services are available and whether the region meets performance and compliance needs.
In some cases, organizations may need to distribute workloads across multiple regions to access specific services. This introduces additional architectural complexity but allows for greater flexibility and capability alignment.
Capacity Distribution and Regional Resource Constraints
Each Azure region operates within a defined capacity envelope based on available physical infrastructure. This includes compute resources, storage systems, networking bandwidth, and power availability. While Azure is designed to scale massively, individual regions still have finite limits.
Capacity distribution is managed dynamically based on demand patterns. Microsoft continuously monitors resource utilization across regions and expands infrastructure where needed. However, sudden spikes in demand can temporarily strain capacity in specific regions.
When capacity limits are reached, certain services or resource types may become temporarily unavailable for new deployments in that region. This behavior is not unique to Azure but is a natural consequence of physical infrastructure constraints in any large-scale computing system.
To mitigate these limitations, Azure encourages distributed deployment strategies. By spreading workloads across multiple regions, organizations can reduce dependency on a single region’s capacity and improve overall resilience.
Capacity planning also influences pricing and availability strategies. Regions with higher demand may experience different pricing structures or resource availability patterns compared to less saturated regions.
Evolution of Azure Infrastructure Expansion Over Time
Azure’s global infrastructure has evolved significantly since its early deployment stages. Initially, the platform operated with a relatively limited number of regions and faced frequent capacity constraints due to rapid adoption growth.
As demand for cloud services increased, Microsoft invested heavily in expanding its global data center footprint. This expansion included building new regions, increasing capacity in existing regions, and improving efficiency through virtualization and automation technologies.
Over time, Azure transitioned from a limited regional platform into a globally distributed cloud ecosystem with extensive geographic coverage. This expansion has enabled organizations of all sizes to deploy applications closer to their users while benefiting from scalable infrastructure.
Despite this growth, infrastructure expansion remains an ongoing process. New regions continue to be added based on demand, regulatory requirements, and strategic planning. Existing regions are also continuously upgraded to support higher performance and broader service offerings.
Interdependence Between Regions and Availability Zones
Azure regions and availability zones are closely interconnected components of the cloud infrastructure model. While regions provide geographic distribution, availability zones provide intra-regional isolation.
Availability zones are physically separate locations within a single region, each with independent power, cooling, and networking systems. This design ensures that failures affecting one zone do not impact others within the same region.
When combined with region pairing, availability zones create a multi-layered resilience model. Regions protect against large-scale geographic failures, while availability zones protect against localized infrastructure failures.
This interdependence allows organizations to design highly resilient architectures that can withstand a wide range of failure scenarios. Applications can be distributed across zones within a region for high availability and replicated across regions for disaster recovery.
The Importance of Strategic Cloud Architecture Design
Designing effective cloud architectures in Azure requires a deep understanding of how regions, availability zones, capacity, and networking infrastructure interact. Strategic architecture design involves balancing performance, cost, resilience, and compliance requirements.
One of the key architectural decisions is determining how workloads are distributed across regions and zones. Some applications benefit from single-region deployments with zone redundancy, while others require multi-region architectures for global availability.
Another important consideration is data consistency. Distributed systems must manage synchronization between regions while minimizing latency and maintaining data integrity. This often requires careful selection of replication models and consistency strategies.
Cost management is also an important factor. Multi-region deployments increase infrastructure usage and data transfer costs. Organizations must evaluate whether the benefits of increased resilience justify the additional expense.
Conclusion
Microsoft Azure regions and availability zones form the backbone of one of the most sophisticated global cloud infrastructures in operation today. When viewed collectively, these components are not just technical building blocks but carefully engineered systems designed to solve fundamental challenges in computing: reliability, scalability, performance, compliance, and global accessibility. Understanding how these elements interact provides a clearer picture of why Azure is structured the way it is and why architectural decisions within it matter so significantly.
At the core, Azure regions exist to solve the problem of geographic distribution. In traditional computing environments, applications were often confined to a single data center or physical location. This created obvious risks, including downtime due to hardware failure, natural disasters, or infrastructure overload. By distributing infrastructure across multiple regions worldwide, Azure ensures that workloads can be deployed closer to users while also being protected from localized failures. This dual benefit of proximity and resilience is central to modern cloud design.
The concept of region pairing adds another layer of architectural intelligence. Instead of treating each region as an isolated unit, Azure intentionally links regions into pairs that support redundancy and disaster recovery. This ensures that even in extreme scenarios where an entire region becomes unavailable, a secondary region can take over operations. What makes this model particularly effective is that it is not left to user implementation alone. The platform itself enforces and encourages best-practice pairing strategies, reducing the likelihood of misconfiguration or incomplete disaster recovery planning.
Availability zones further refine this model by addressing a different class of failure: localized infrastructure disruption. While regions protect against large-scale geographic issues, availability zones protect against more granular failures such as power outages or hardware breakdowns within a single data center. By distributing workloads across multiple zones within the same region, organizations can achieve extremely high levels of uptime without necessarily needing to span multiple geographic regions. This layered approach to redundancy is one of the reasons cloud platforms can offer service-level agreements that were previously unattainable in traditional infrastructure models.
Another critical dimension of Azure’s architecture is capacity management. Despite the perception that cloud computing offers infinite scalability, every region is ultimately constrained by physical infrastructure. Compute resources, storage systems, networking bandwidth, and power availability all impose real-world limits. Azure manages these constraints through continuous monitoring, demand forecasting, and infrastructure expansion. However, capacity is not uniform across all regions, and this introduces an important architectural consideration: not every service or workload can be deployed anywhere at any time. This reality requires organizations to plan deployments carefully, taking into account regional availability and scalability constraints.
Latency is another defining factor in cloud performance, and Azure’s regional distribution directly addresses this challenge. By positioning data centers closer to users, Azure reduces the physical distance data must travel, thereby minimizing response times. Even though modern networking technologies have significantly reduced the impact of distance, latency still plays a crucial role in user experience, especially in real-time or data-intensive applications. The difference between a few milliseconds may seem negligible in isolation, but at scale, across millions of transactions, it becomes a critical performance factor.
The global backbone network that connects Azure regions is another key enabler of performance and reliability. This private, high-speed network allows data to move between regions efficiently and consistently, without relying solely on public internet routes. This improves not only speed but also predictability, which is essential for enterprise-grade applications that require stable and consistent communication between distributed components. The backbone network effectively turns Azure into a unified global system rather than a collection of isolated data centers.
Geographic abstraction in Azure’s regional naming system reflects a balance between usability and operational security. While regions are named after recognizable cities or areas, the actual physical data centers may be located outside those exact locations. This abstraction allows Microsoft to optimize infrastructure placement based on technical and logistical requirements rather than being constrained by city boundaries. It also ensures a level of operational confidentiality while still providing customers with a meaningful understanding of where their data resides.
Data sovereignty further complicates the global cloud landscape, as different countries impose different rules on how and where data can be stored and processed. Azure addresses this through region-specific compliance models that ensure workloads meet local legal requirements. In some cases, data must remain within national borders, while in others, it must adhere to specific handling or encryption standards. This makes region selection not just a technical decision but also a legal and regulatory one, particularly for multinational organizations operating across multiple jurisdictions.
Service variability across regions adds another layer of complexity. Not all Azure services are available in every region, and this can influence architecture design decisions. Organizations must evaluate whether a chosen region supports all required services before deployment. In some cases, workloads must be distributed across multiple regions to meet functional requirements, which introduces additional architectural considerations such as data synchronization and cross-region communication.
Despite these complexities, the overall design of Azure regions and availability zones reflects a highly optimized balance between flexibility and control. It allows organizations to build systems that are both globally distributed and locally responsive, while also maintaining strong guarantees around uptime and resilience. The layered structure of regions, zones, and global networking ensures that failures are contained, performance is optimized, and scalability is preserved.
Ultimately, understanding Azure regions and availability zones is not just about learning infrastructure terminology. It is about understanding how modern digital systems achieve global scale while maintaining reliability and performance. These concepts influence how applications are designed, how data is managed, and how services are delivered to users around the world.