Modern digital communication systems depend on efficient data transfer across interconnected networks, where performance is shaped by several fundamental parameters. Among these, latency, bandwidth, and throughput form the core pillars used to evaluate how well a network is functioning under different conditions. These concepts are often misunderstood or used interchangeably, yet each describes a distinct aspect of network behavior. Understanding them in depth is essential for anyone involved in network design, administration, optimization, or troubleshooting, because real-world performance issues rarely originate from a single factor. Instead, they emerge from the interaction between these variables, along with physical infrastructure, protocol behavior, and traffic patterns.
In practical networking environments, performance is not defined only by how fast data can theoretically move, but by how efficiently it is delivered between endpoints under varying conditions. This distinction becomes critical when analyzing user experience in applications such as cloud services, streaming platforms, enterprise systems, and real-time communication tools. Even networks with high theoretical capacity can perform poorly if latency is high or if throughput is restricted by congestion or inefficiencies. This makes it essential to break down each concept independently before understanding how they interact in real-world scenarios.
Latency as a Fundamental Delay Metric in Data Communication
Latency represents the time required for a data packet to travel from a source device to a destination device across a network. It is fundamentally a time-based measurement and does not describe how much data can be transferred, but how quickly communication begins and completes. In most networking contexts, latency is measured in milliseconds because modern transmission systems operate at extremely high speeds, making second-level measurements too coarse for meaningful analysis.
Latency is influenced by several factors that accumulate along the data path. Physical distance is one of the most significant contributors because signals traveling through copper, fiber, or wireless mediums require finite time to propagate. Even though light and electrical signals move extremely fast, long-distance communication introduces measurable delay. Beyond distance, the number of intermediate devices also affects latency. Each router, switch, or gateway that processes a packet introduces processing delay, even if only for a fraction of a millisecond. These small delays accumulate across multiple hops, increasing the total response time experienced by the end user.
Another important component of latency is queuing delay. When network devices experience congestion, packets are temporarily held in buffers before being forwarded. This waiting time can vary significantly depending on traffic load. Under heavy congestion, queues become longer, resulting in noticeable performance degradation. Additionally, serialization delay contributes to latency, particularly in slower links, where it takes time to place all bits of a packet onto the transmission medium.
A widely used method for measuring latency is round-trip time, which calculates the total time taken for a packet to reach its destination and return to the source. This measurement is particularly useful because many network applications rely on acknowledgment-based communication protocols. These protocols require confirmation from the receiving end before additional data is transmitted, meaning round-trip delay directly impacts perceived responsiveness.
Latency plays a critical role in interactive and real-time systems. Applications such as voice communication, video conferencing, and online gaming are highly sensitive to delays. Even minor increases in latency can result in noticeable disruptions, including audio lag, video desynchronization, and delayed input response. In such systems, maintaining low and consistent latency is often more important than maximizing raw data transfer rates. This is because user experience depends on responsiveness rather than sheer throughput capacity.
Bandwidth as a Theoretical Capacity of Network Links
Bandwidth represents the maximum amount of data that a network link can carry within a given period of time under ideal conditions. Unlike latency, which measures delay, bandwidth defines potential capacity. It is typically expressed in bits per second and reflects the upper limit of data transmission capability for a given communication channel.
The concept of bandwidth is closely tied to physical infrastructure and hardware capabilities. Transmission media such as fiber optic cables, copper wires, and wireless spectrum each have inherent limitations that determine how much data they can carry. In addition, network interface devices such as routers, switches, and network cards are designed to support specific maximum speeds. These hardware constraints establish the theoretical bandwidth ceiling for a connection.
Service providers also play a significant role in defining bandwidth through provisioning policies. Network plans are typically structured around specific speed tiers, where users are allocated a maximum data rate based on subscription level. However, even when a high bandwidth connection is provisioned, actual performance depends on several external factors. Signal degradation, distance from infrastructure points, and equipment limitations can all reduce the effective utilization of available bandwidth.
It is important to understand that bandwidth does not guarantee actual performance. Instead, it defines potential capacity under optimal conditions. A connection may support high bandwidth on paper but fail to deliver equivalent real-world performance due to congestion, routing inefficiencies, or hardware constraints. This distinction is crucial when analyzing network behavior, as it prevents misinterpretation of performance issues.
Throughput as the Real-World Measurement of Data Transfer Performance
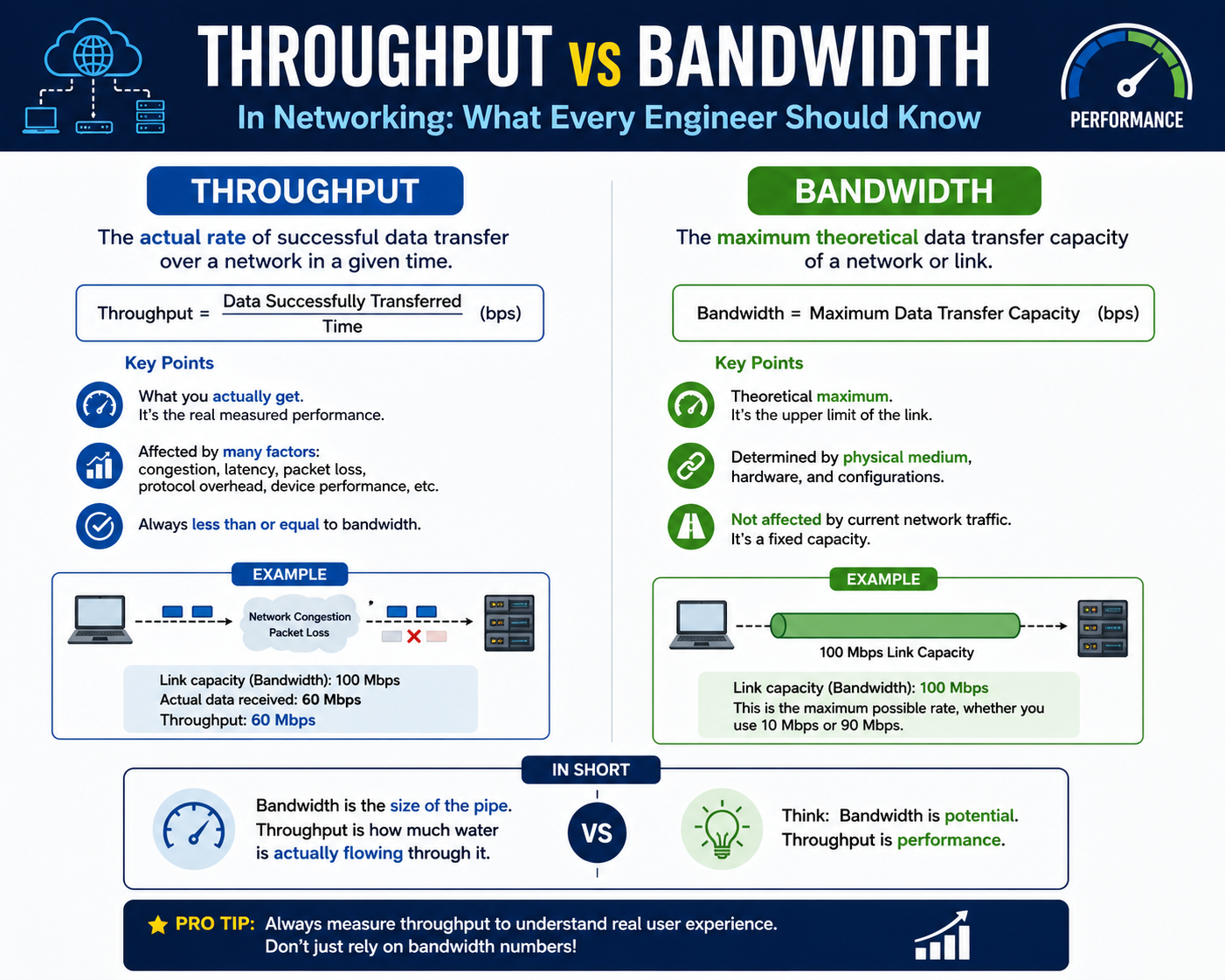
Throughput represents the actual rate at which data is successfully transmitted between two endpoints under real operating conditions. Unlike bandwidth, which is theoretical, throughput reflects measurable performance experienced during actual data transfer. It includes all real-world factors such as network congestion, packet loss, retransmissions, and protocol overhead.
Throughput is often lower than bandwidth because it accounts for inefficiencies and external conditions affecting transmission. For example, when data is sent across a network, not all packets reach their destination successfully on the first attempt. Some packets may be dropped due to congestion or errors, requiring retransmission. These retransmissions consume additional time and reduce the overall effective data transfer rate.
Routing paths also influence throughput significantly. Data traveling across networks may pass through multiple intermediate systems, each introducing potential delays or bottlenecks. If any segment of the path is congested or underperforming, it can reduce overall throughput even if the source and destination systems are capable of higher speeds.
Protocol behavior also plays a critical role. Many communication protocols rely on acknowledgement systems where data must be confirmed before additional packets are sent. While this ensures reliability, it can also limit speed, especially over high-latency connections. In such cases, throughput becomes dependent not only on bandwidth but also on how efficiently communication cycles are managed.
Throughput is the most practical indicator of network performance from a user perspective. When downloading files, streaming content, or accessing remote services, the speed experienced by the user is determined by throughput rather than theoretical bandwidth. This makes it a critical metric for performance evaluation, capacity planning, and troubleshooting.
Relationship Between Latency, Bandwidth, and Throughput in Network Behavior
Although latency, bandwidth, and throughput describe different aspects of network performance, they are closely interconnected. Changes in one parameter often influence the others, either directly or indirectly. For example, high latency can reduce throughput in acknowledgment-based communication systems because data transmission must pause while waiting for confirmation. Even if bandwidth is high, excessive delay can prevent full utilization of available capacity.
Similarly, limited bandwidth can constrain throughput regardless of latency conditions. If a network link has low capacity, it cannot transmit large volumes of data quickly, even if delays are minimal. This demonstrates that bandwidth defines potential throughput limits, while latency affects how efficiently that potential is realized.
Congestion is another factor that impacts all three metrics simultaneously. When network traffic exceeds available capacity, queues build up, increasing latency while reducing throughput. Packet loss may also occur, further degrading performance by requiring retransmissions. This creates a cascading effect where multiple performance indicators degrade together.
Understanding the interaction between these metrics is essential for diagnosing network issues. A slow network is not always caused by insufficient bandwidth; it may result from high latency or congestion affecting throughput. Accurate analysis requires evaluating all three parameters together rather than in isolation.
Network Throughput in Real-World Conditions and Performance Variability
Network throughput represents the actual rate of successful data delivery between two endpoints under real operating conditions, and it is one of the most practical indicators of how a network behaves in everyday use. Unlike theoretical capacity metrics, throughput is dynamic, fluctuating based on traffic load, routing efficiency, protocol overhead, and physical network conditions. In operational environments, throughput is rarely constant, even on stable infrastructure, because it is continuously influenced by a combination of controllable and uncontrollable variables.
One of the most important characteristics of throughput is its variability across different paths and destinations. A user may observe significantly different transfer speeds when accessing different services or servers, even when the local network connection remains unchanged. This variation occurs because each communication path has its own unique routing structure, congestion level, and processing overhead. Data traveling through fewer intermediate hops or less congested regions will typically achieve higher throughput compared to data routed through heavily loaded or geographically distant networks.
Another major factor affecting throughput is packet loss. When packets are lost during transmission, they must be retransmitted, which reduces the effective data delivery rate. Packet loss can occur due to congestion, faulty hardware, interference in wireless environments, or misconfigured network devices. Even small percentages of packet loss can have a noticeable impact on throughput because retransmission cycles consume both time and bandwidth. This is particularly impactful in high-volume data transfers or long-duration sessions where cumulative loss effects become more pronounced.
Protocol design also plays a significant role in determining throughput efficiency. Many network communication protocols are designed to prioritize reliability over speed. They use acknowledgment mechanisms to ensure data integrity, meaning that the sender must wait for confirmation before continuing transmission. While this improves accuracy, it introduces delays that reduce throughput, especially in environments with high latency. In contrast, some protocols designed for real-time communication prioritize speed and continuous data flow, which can improve throughput at the expense of reliability.
Congestion control mechanisms further influence throughput behavior. Modern networks implement algorithms that dynamically adjust transmission rates based on perceived network conditions. When congestion is detected, these systems reduce transmission speed to prevent packet loss and stabilize the network. While this helps maintain overall network stability, it can significantly reduce throughput during peak usage periods. As a result, users may experience slower performance even when their connection has high theoretical bandwidth.
Throughput is also affected by hardware limitations. Network interface cards, switches, routers, and transmission media all contribute to the overall data transfer capability. If any component in the communication chain becomes a bottleneck, it restricts throughput regardless of the capabilities of other components. For example, a high-speed internet connection connected to outdated networking hardware may not achieve expected performance levels due to internal processing limitations.
In wireless environments, throughput is further influenced by signal strength, interference, and environmental conditions. Physical obstacles such as walls, distance from access points, and electromagnetic interference can reduce effective data rates. Unlike wired connections, wireless throughput tends to fluctuate more frequently due to changing environmental conditions, making it less stable but more flexible in deployment scenarios.
Understanding throughput behavior requires analyzing the entire communication path rather than focusing on individual components. Bottlenecks can occur at multiple layers, including physical transmission, network routing, and application processing. Identifying the weakest link in the chain is essential for optimizing performance and improving data transfer efficiency.
Bandwidth Utilization and Its Role in Network Capacity Efficiency
Bandwidth represents the maximum theoretical data transfer capacity of a network link, but in real-world systems, the degree to which this capacity is utilized plays a critical role in determining overall performance efficiency. Bandwidth utilization refers to how effectively available capacity is being used at any given time. High utilization does not always indicate optimal performance, and low utilization does not necessarily indicate inefficiency, making interpretation context-dependent.
In many networks, bandwidth is provisioned at higher levels than typical usage to accommodate traffic spikes and ensure consistent performance. This approach prevents congestion during peak usage periods but also introduces variability in utilization levels. During low-traffic periods, bandwidth may remain underutilized, while during high-demand periods, it may approach or reach saturation. When saturation occurs, performance degradation becomes more likely due to queuing delays and packet loss.
Bandwidth efficiency is heavily influenced by traffic patterns. Bursty traffic, where large amounts of data are transmitted intermittently, can lead to uneven utilization. Continuous traffic, on the other hand, tends to produce more stable utilization patterns. Applications such as streaming services, cloud backups, and large-scale data transfers often generate sustained bandwidth consumption, while web browsing and interactive applications produce more variable usage patterns.
Another factor affecting bandwidth utilization is protocol overhead. Every data transmission includes additional information beyond the actual payload, such as headers, control information, and error-checking data. This overhead consumes a portion of available bandwidth without contributing directly to user data transfer. In high-volume networks, even small overhead percentages can significantly impact overall efficiency.
Traffic shaping and prioritization mechanisms are often implemented to manage bandwidth usage more effectively. These systems control how data is transmitted across the network by prioritizing certain types of traffic over others. For example, real-time communication traffic may be prioritized over bulk data transfers to ensure consistent performance. While this improves user experience for critical applications, it can also limit available bandwidth for lower-priority traffic.
Bandwidth efficiency is also influenced by network design. Poorly designed networks with excessive routing complexity or inefficient topology can waste available capacity due to suboptimal data paths. In contrast, well-optimized network architectures reduce unnecessary data traversal and improve overall utilization efficiency. This highlights the importance of network planning in achieving effective bandwidth usage.
In enterprise environments, bandwidth monitoring is essential for capacity planning. Continuous observation of usage patterns allows administrators to identify trends, anticipate congestion points, and allocate resources accordingly. Without proper monitoring, networks may experience unexpected saturation, leading to performance degradation and reduced throughput.
Latency Behavior in Complex Network Environments
Latency in complex networks is not a fixed value but a dynamic metric influenced by multiple interacting components. In large-scale systems, latency can vary significantly depending on routing paths, congestion levels, and processing loads across intermediate devices. This variability makes latency one of the most challenging aspects of network performance to predict and optimize.
One of the primary contributors to latency variation is routing behavior. In modern networks, data packets may take different paths to reach the same destination depending on network conditions and routing protocols. Some paths may be shorter but more congested, while others may be longer but less congested. This dynamic routing results in fluctuating latency values even for identical communication sessions.
Queuing delay is another major contributor to latency variability. When network devices experience high traffic volumes, packets are temporarily stored in buffers before being processed. The length of these queues depends on current traffic conditions, making latency unpredictable during peak usage periods. In extreme cases, excessive queuing can lead to bufferbloat, where latency increases significantly due to overloaded buffers.
Processing delay within network devices also affects latency. Each packet must be analyzed, routed, and forwarded by intermediate devices, and this processing requires computational resources. Under high load conditions, device processing times may increase, contributing to higher overall latency. Even modern high-performance networking equipment can experience measurable delays under heavy traffic conditions.
Propagation delay remains a fundamental component of latency that cannot be eliminated. It is determined by the physical distance between endpoints and the speed at which signals travel through the transmission medium. While fiber optic systems provide extremely high transmission speeds, long-distance communication still introduces measurable delay due to physical constraints.
Latency also interacts closely with application-level behavior. Many applications rely on sequential communication patterns where each step depends on a response from the previous step. In such cases, even small increases in latency can compound over multiple interactions, resulting in noticeable performance degradation. This is particularly evident in systems that require frequent back-and-forth communication between client and server.
In distributed systems, latency becomes even more complex due to synchronization requirements. Data consistency across multiple nodes often requires coordination, which introduces additional communication delays. As systems scale across multiple geographic regions, latency differences between nodes can significantly impact overall system performance.
Interaction Between Network Layers and Performance Outcomes
Network performance is not determined by a single metric but by the interaction of multiple layers within the communication stack. Physical transmission, data link behavior, network routing, transport protocols, and application logic all contribute to the final observed performance. Each layer introduces its own constraints and optimization opportunities.
At the physical layer, transmission medium quality directly affects both bandwidth and latency. Copper-based systems are more susceptible to interference and signal degradation, while fiber optic systems provide higher stability and capacity. Wireless systems introduce additional variability due to environmental interference and signal attenuation.
At the network layer, routing decisions determine the path that data takes between endpoints. Efficient routing reduces latency and improves throughput by minimizing unnecessary hops and avoiding congested paths. Inefficient routing can significantly degrade performance even when the physical infrastructure is capable of higher speeds.
The transport layer plays a critical role in managing reliability and flow control. Protocols operating at this layer determine how data is segmented, transmitted, acknowledged, and retransmitted. These mechanisms directly influence throughput efficiency and latency behavior, particularly in high-latency or lossy environments.
Application-layer behavior ultimately defines how users perceive network performance. Applications that are optimized for network efficiency can reduce unnecessary data transfers, minimize latency sensitivity, and improve throughput utilization. Poorly optimized applications may generate excessive network traffic, increasing congestion and reducing overall efficiency.
Network Performance Bottlenecks and Their Impact on Throughput, Bandwidth, and Latency
Network bottlenecks represent points within a communication path where data flow is restricted, causing performance degradation across one or more key metrics such as throughput, latency, and effective bandwidth utilization. These bottlenecks are not always obvious because they may occur at different layers of the network stack or within intermediate devices that are not immediately visible during basic troubleshooting. Understanding bottlenecks requires a systemic view of how data travels through a network, from the source application through multiple infrastructure components to the final destination.
A common type of bottleneck occurs at the physical layer when transmission media cannot support the expected data rate. This may happen when outdated cabling, degraded fiber connections, or low-quality wireless signals limit the actual data-carrying capacity of a link. Even if higher-layer configurations support high-speed communication, physical limitations reduce effective throughput and create inconsistencies in performance. In such cases, bandwidth is effectively constrained by hardware limitations rather than configuration settings.
Another significant bottleneck arises at network devices such as routers, switches, and firewalls. These devices are responsible for processing, forwarding, and sometimes inspecting every packet that passes through them. When traffic load increases beyond processing capacity, queues begin to form, leading to increased latency and reduced throughput. In extreme cases, packet loss occurs when buffers overflow, forcing retransmissions and further reducing efficiency.
Processing bottlenecks are particularly relevant in environments where deep packet inspection, encryption, or traffic filtering is enabled. These functions require additional computational resources, and when hardware is not sufficiently powerful, they introduce measurable delays. As traffic volume increases, these delays compound, resulting in significant performance degradation even if the underlying network infrastructure has sufficient bandwidth capacity.
Application-layer bottlenecks also play a major role in limiting network performance. If an application is not optimized for efficient data handling, it may generate excessively small packets, inefficient request patterns, or unnecessary retransmissions. These behaviors consume bandwidth without contributing to meaningful data transfer, reducing overall throughput efficiency. Additionally, poorly designed applications may fail to fully utilize available bandwidth, resulting in underperformance even in high-capacity networks.
Congestion is another primary cause of bottlenecks in modern networks. When multiple data flows compete for limited resources, network devices must manage traffic distribution, often using queuing and prioritization mechanisms. While these systems help maintain fairness and stability, they can also introduce delays and reduce throughput for lower-priority traffic. During peak usage periods, congestion can significantly degrade user experience across multiple applications simultaneously.
Identifying bottlenecks requires careful analysis of performance metrics across different segments of the network. A high-bandwidth connection with low throughput often indicates congestion or processing limitations rather than capacity constraints. Similarly, high latency combined with low throughput may indicate routing inefficiencies or excessive queuing. Effective troubleshooting involves isolating each segment of the network path to determine where performance degradation occurs.
Advanced Factors Affecting Network Throughput Efficiency
Throughput efficiency in modern networks is influenced by a wide range of advanced technical factors that extend beyond basic bandwidth and latency considerations. These factors include protocol design, congestion control algorithms, error recovery mechanisms, and data transmission strategies. Each of these elements plays a role in determining how effectively available network resources are utilized.
One of the most important contributors to throughput efficiency is congestion control behavior within transport protocols. These mechanisms dynamically adjust transmission rates based on perceived network conditions. When congestion is detected, transmission speed is reduced to prevent packet loss and stabilize the network. While this ensures reliability and fairness across multiple users, it can also limit throughput, particularly in high-latency environments where feedback loops take longer to complete.
Error recovery mechanisms also influence throughput performance. When packets are lost or corrupted during transmission, they must be retransmitted. This process consumes additional bandwidth and increases overall transmission time. In environments with high error rates, such as wireless networks or long-distance connections, retransmissions can significantly reduce effective throughput. Even small error rates can have a large cumulative impact over time, especially in large data transfers.
Another factor affecting throughput efficiency is windowing behavior in connection-oriented protocols. These systems control how much data can be sent before an acknowledgment is required. Smaller window sizes reduce the amount of data in transit at any given time, limiting throughput, especially in high-latency networks. Larger window sizes improve throughput but require more buffer capacity and careful congestion management to prevent overload.
Data encapsulation overhead also reduces effective throughput. Each layer of network communication adds additional headers and control information to data packets. While this overhead is necessary for routing, error checking, and session management, it reduces the proportion of usable data transmitted per packet. In high-frequency communication systems, this overhead can accumulate and significantly impact overall efficiency.
Load-balancing mechanisms can both improve and reduce throughput depending on implementation. Properly designed load balancing distributes traffic evenly across multiple paths or servers, increasing overall capacity utilization. However, poorly configured load balancing may introduce routing inefficiencies, causing packets to take suboptimal paths and reducing throughput consistency.
Multipath communication strategies are increasingly used to improve throughput in modern networks. By distributing data across multiple simultaneous connections, systems can overcome limitations of single-path bandwidth constraints. However, these strategies require careful synchronization and coordination to prevent packet reordering and ensure data integrity.
Latency Sensitivity in Distributed and High-Scale Network Systems
Latency becomes increasingly significant in distributed systems where multiple nodes communicate across different geographic locations. In such environments, even small delays can have amplified effects due to the cumulative nature of multi-step communication processes. Each interaction between nodes introduces additional delay, and when systems require frequent synchronization, these delays can significantly impact overall performance.
One of the key challenges in distributed systems is maintaining consistency across nodes while minimizing latency. Data replication, synchronization protocols, and consensus mechanisms all require communication between multiple systems. As the number of nodes increases, the complexity of maintaining low-latency communication grows exponentially, making optimization more difficult.
Geographical distribution is a major contributor to latency variation in large-scale systems. Data traveling across continents must traverse multiple network segments, each introducing its own delay. Undersea cables, interconnection points, and regional routing policies all influence the total latency experienced by end users. Even highly optimized systems cannot eliminate physical distance constraints, making latency management a critical design consideration.
In cloud-based architectures, latency affects not only user experience but also system efficiency. Microservices architectures, for example, rely on frequent inter-service communication. If the latency between services is high, overall application performance degrades due to increased waiting times and reduced parallel processing efficiency. This makes network design a fundamental part of system architecture rather than a secondary consideration.
Caching strategies are often used to reduce latency in distributed systems. By storing frequently accessed data closer to the user or application, systems can reduce the need for repeated long-distance communication. While caching improves performance, it introduces challenges related to data consistency and synchronization, particularly in environments where data changes frequently.
Latency optimization also involves protocol selection and tuning. Some protocols are designed to minimize handshake requirements and reduce communication cycles, improving responsiveness in high-latency environments. Others prioritize reliability and error correction, which can increase latency but improve data integrity. Selecting the appropriate protocol depends on the specific requirements of the application.
Network Optimization Strategies for Improving Overall Performance
Optimizing network performance requires a multi-layered approach that addresses latency, bandwidth utilization, and throughput efficiency simultaneously. Since these metrics are interconnected, improving one often affects the others, making optimization a balancing act rather than a single-variable adjustment.
At the infrastructure level, upgrading physical components can significantly improve performance. High-quality cabling, modern network interface hardware, and optimized wireless configurations reduce signal degradation and increase stable data transfer rates. These improvements directly impact both bandwidth utilization and throughput consistency.
Routing optimization is another critical strategy. By ensuring that data takes the most efficient path between endpoints, networks can reduce unnecessary latency and improve throughput. Dynamic routing protocols are often used to automatically adjust paths based on real-time network conditions, improving overall efficiency.
Traffic prioritization techniques help manage network load by assigning different levels of importance to different types of traffic. Real-time applications may be prioritized over bulk data transfers, ensuring consistent performance for latency-sensitive services. While this improves user experience, it must be carefully managed to avoid starving lower-priority traffic.
Compression techniques can also improve throughput efficiency by reducing the amount of data transmitted over the network. By encoding data more efficiently, compression reduces bandwidth usage and allows more information to be transmitted within the same capacity limits. However, compression introduces processing overhead, which must be balanced against performance gains.
Parallelization strategies improve throughput by distributing data across multiple simultaneous streams. This approach reduces dependency on single-path limitations and allows better utilization of available bandwidth. However, it requires careful coordination to ensure data integrity and avoid reassembly issues at the destination.
Continuous monitoring and analysis are essential for maintaining optimal network performance. By tracking latency, bandwidth usage, and throughput trends over time, network administrators can identify emerging issues before they become critical problems. This proactive approach ensures long-term stability and efficiency in complex network environments.
Conclusion
Network performance is ultimately the result of multiple interacting factors rather than a single defining metric. Latency, bandwidth, and throughput each describe a different dimension of how data moves across a network, and understanding their distinctions is essential for accurate analysis of system behavior. While bandwidth defines the theoretical capacity of a connection, latency determines how quickly communication begins and responds, and throughput reflects the actual usable performance experienced under real-world conditions. When viewed together, these metrics provide a complete picture of network efficiency, revealing not only how fast a network can potentially operate, but also how well it performs under real operational stress.
In practical environments, one of the most common misconceptions is treating bandwidth as the sole indicator of performance. High bandwidth does not guarantee a high-speed experience if latency is elevated or if throughput is restricted by congestion, routing inefficiencies, or protocol limitations. A network link may be provisioned for extremely high speeds, yet users may still experience slow file transfers or delayed responses due to underlying inefficiencies. This mismatch between theoretical capacity and actual performance is why throughput is often considered the most meaningful metric from an end-user perspective. It reflects what is truly delivered after all overhead, delays, and losses are accounted for.
Latency plays a particularly critical role in shaping perceived responsiveness. Even small increases in delay can significantly affect interactive applications where timing is essential. Voice communication, video conferencing, remote desktop usage, and online gaming are all highly sensitive to latency variations. In these environments, delays accumulate across multiple communication cycles, leading to noticeable disruptions such as lag, echo, or synchronization issues. Unlike bandwidth, which is often stable within a configured link, latency can fluctuate dynamically based on routing paths, congestion levels, and processing delays across intermediate devices. This variability makes latency one of the most challenging performance factors to control in large-scale or geographically distributed networks.
Throughput, on the other hand, represents the combined outcome of all network conditions. It is shaped not only by available bandwidth but also by latency behavior, packet loss rates, retransmission frequency, congestion levels, and protocol efficiency. In ideal conditions, throughput may approach the maximum bandwidth of a connection, but in most real-world scenarios, it remains lower due to these compounding inefficiencies. This is why two networks with identical bandwidth specifications can deliver vastly different user experiences depending on their internal structure and external conditions.
Another important aspect of network performance is the relationship between stability and efficiency. A network that maintains consistent throughput with minimal variation is often more valuable than one that achieves higher peak speeds but fluctuates frequently. Stability ensures predictable performance, which is essential for enterprise systems, cloud infrastructure, and mission-critical applications. Variability in throughput or latency can introduce uncertainty, making it difficult to optimize applications or guarantee service quality. As a result, network design increasingly focuses on consistency rather than raw peak performance alone.
Modern networks also face challenges related to scale and complexity. As systems expand across multiple regions and integrate cloud-based architectures, the number of communication paths increases significantly. Each additional node or service introduces new potential points of delay or congestion. In such environments, maintaining optimal performance requires careful orchestration of routing policies, traffic distribution, and load balancing mechanisms. Even small inefficiencies at scale can result in substantial cumulative performance degradation, highlighting the importance of continuous monitoring and optimization.
Protocol behavior also remains a central factor in determining network efficiency. Reliable communication protocols introduce acknowledgment and retransmission mechanisms to ensure data integrity, but these mechanisms inherently introduce delay. In contrast, lightweight protocols may achieve higher throughput in certain scenarios but sacrifice reliability. The choice of protocol, therefore,e depends on the specific requirements of the application, balancing speed, accuracy, and resilience. This trade-off is especially important in environments where both high performance and data integrity are required simultaneously.
Infrastructure quality continues to be a foundational element in determining network performance outcomes. Physical media, hardware capabilities, and device configurations all contribute to the overall efficiency of data transmission. Even the most advanced software optimizations cannot fully compensate for limitations in physical infrastructure. Similarly, outdated or improperly configured hardware can introduce bottlenecks that significantly reduce throughput and increase latency. This reinforces the importance of maintaining modern, well-configured infrastructure as a baseline requirement for high-performance networking.
Another key consideration is the role of congestion in shaping performance behavior. Network congestion occurs when demand exceeds available capacity, leading to queuing delays, packet loss, and reduced throughput. Congestion is not limited to any single point in the network; it can occur at local access points, core routing systems, or external service providers. Its impact is often nonlinear, meaning that small increases in traffic can sometimes lead to disproportionately large decreases in performance. Effective congestion management strategies are therefore essential for maintaining stable network behavior under varying load conditions.
Optimization strategies in networking typically focus on improving the balance between latency, bandwidth utilization, and throughput efficiency. These strategies may include infrastructure upgrades, routing optimization, traffic prioritization, compression techniques, and parallel data transmission methods. However, optimization is rarely a one-time process. Network conditions evolve due to changing usage patterns, new application demands, and infrastructure expansion. As a result, continuous assessment and adjustment are necessary to maintain optimal performance.
Ultimately, understanding network performance requires a holistic perspective that considers all contributing factors together rather than in isolation. Latency, bandwidth, and throughput are deeply interconnected, and changes in one often influence the others in complex ways. Effective network analysis depends on recognizing these relationships and interpreting performance data within the broader context of system behavior. This integrated approach allows for more accurate diagnosis of issues, more efficient design of network systems, and more reliable delivery of digital services across diverse environments.