VMware ESXi is designed to operate as a bare-metal virtualization layer that abstracts physical hardware resources into multiple isolated virtual environments. One of its most critical capabilities is memory overcommitment, where the total configured memory assigned to virtual machines exceeds the actual physical RAM installed on the host. This approach is based on the observation that most workloads do not consistently consume their full allocated memory, allowing the hypervisor to safely optimize utilization without immediate resource exhaustion.
In a typical virtualized infrastructure, memory demand is highly dynamic. Virtual machines may experience spikes, idle periods, and fluctuating application behavior. ESXi continuously monitors this variability and applies a hierarchical memory management strategy to ensure that active workloads receive priority access to physical memory while maintaining system stability. The hypervisor does not treat memory as statically bound resources but instead as fluid allocations that can be adjusted in real time based on demand.
This dynamic model relies on a layered reclamation approach. Instead of immediately reducing performance or forcing disk-level operations, ESXi first attempts to recover unused memory through low-impact optimization techniques. Only when pressure intensifies does it escalate to more aggressive mechanisms. This ensures that memory overcommitment remains practical even in high-density environments.
Transparent Page Sharing and Memory Deduplication Mechanics
One of the earliest and least intrusive techniques in ESXi memory optimization is Transparent Page Sharing. This mechanism is based on identifying identical memory pages across one or more virtual machines and consolidating them into a single physical representation. Since many operating systems and applications load identical code segments and shared libraries, a significant portion of memory can often be duplicated unnecessarily across workloads.
The hypervisor performs memory page analysis by comparing page-level content and identifying matches. When identical pages are detected, ESXi maps multiple virtual references to a single physical page. Each virtual machine continues to operate as if it has its own dedicated memory, while the underlying physical resource is shared. This reduces overall memory consumption without modifying application behavior or guest operating system configuration.
This process operates continuously in the background and is largely transparent to workloads. It is particularly effective in environments where virtual machines are deployed from standardized templates or run identical operating systems. In such cases, the proportion of duplicate memory pages is significantly higher, allowing greater consolidation efficiency.
Transparent Page Sharing operates at two conceptual levels. The first is intra-virtual machine deduplication, where redundancy within a single virtual machine is eliminated. The second is inter-virtual machine deduplication, where identical memory pages across multiple virtual machines are consolidated. The latter provides greater savings but is more sensitive to system configuration and security considerations.
Security-Aware Adjustments in Cross-VM Memory Sharing
In modern virtualization environments, inter-virtual machine memory sharing has been restricted or disabled by default in many configurations due to security hardening practices. The primary concern is related to potential side-channel exposure, where memory deduplication could theoretically be used to infer information about co-resident workloads on the same physical host.
As a result, many deployments limit deduplication scope to intra-virtual machine optimization only. This ensures that memory efficiency is still achieved within individual workloads while preserving strict isolation boundaries between separate virtual machines. The balance between optimization and security has become a defining factor in how memory sharing is implemented in contemporary ESXi environments.
Even with these limitations, page sharing remains relevant in controlled infrastructures where workload similarity is high and security policies permit broader optimization. Its effectiveness is directly tied to workload homogeneity, memory stability, and system configuration policies.
Memory Abstraction and Physical-to-Virtual Mapping Model
ESXi does not allocate physical memory directly to virtual machines in a one-to-one static mapping. Instead, it uses a layered abstraction model where virtual memory is translated into machine pages managed by the hypervisor. Each virtual machine operates within its own isolated memory space, while the hypervisor dynamically maps these requests onto physical memory pages.
This abstraction allows ESXi to reposition, share, or reclaim memory without affecting the guest operating system. Virtual machines remain unaware of underlying changes, which enables advanced optimization techniques to function transparently. The memory scheduler continuously evaluates demand and adjusts mappings based on system pressure.
Memory allocation policies such as reservation, limit, and shares further influence how resources are distributed. Reservations guarantee minimum guaranteed memory, ensuring critical workloads maintain operational stability. Limits restrict maximum usage, preventing uncontrolled consumption. Shares define priority during contention scenarios, allowing the hypervisor to allocate resources based on importance when memory is scarce.
Behavior of Memory Under Initial Contention Conditions
When physical memory begins to approach saturation, ESXi first evaluates opportunities for reclaiming unused or redundant memory before reducing performance. At this stage, Transparent Page Sharing plays a foundational role by eliminating duplicate memory pages and reducing baseline consumption across the host.
This early-stage optimization helps delay the need for more intrusive memory reclamation techniques. By reducing redundancy first, ESXi increases the effective capacity of physical memory without impacting workload execution. However, this mechanism alone is insufficient when memory demand exceeds available capacity by a large margin.
As pressure continues to increase, the hypervisor transitions toward more active reclamation strategies that operate closer to workload execution layers. These later mechanisms are more intrusive and can introduce measurable performance changes, but they are only activated when necessary to maintain system stability.
Role of Page-Level Optimization in High-Density Environments
In environments with high virtual machine density, memory efficiency becomes a critical performance factor. Page-level optimization ensures that redundant data structures do not consume unnecessary physical resources. This is especially relevant in scenarios where multiple virtual machines run identical operating systems, middleware stacks, or application frameworks.
By reducing duplicated memory content, ESXi effectively increases the number of virtual machines that can be hosted on a single physical system. This improves hardware utilization and reduces infrastructure overhead while maintaining isolation between workloads. The impact of page-level optimization is most visible in standardized deployments where consistency across virtual machines is high.
However, the efficiency of this mechanism decreases in highly diverse workloads where memory content varies significantly between virtual machines. In such cases, the opportunity for deduplication is limited, and ESXi relies more heavily on other reclamation techniques to manage memory pressure.
Continuous Memory Optimization as a Background Process
Memory optimization in ESXi is not a reactive process but a continuous background activity. The hypervisor constantly evaluates memory usage patterns and applies optimization techniques even when the system is not under stress. This proactive approach ensures that memory efficiency is maintained at all times, reducing the likelihood of sudden performance degradation during peak demand periods.
Transparent Page Sharing operates within this continuous optimization framework by scanning memory pages and consolidating duplicates whenever possible. This ensures that memory footprint remains as compact as possible under stable conditions, allowing more headroom for dynamic workload fluctuations.
The combination of abstraction, deduplication, and hierarchical reclamation forms the foundation of ESXi memory management. It enables the platform to support high consolidation ratios while preserving isolation and stability across diverse virtual machine workloads.
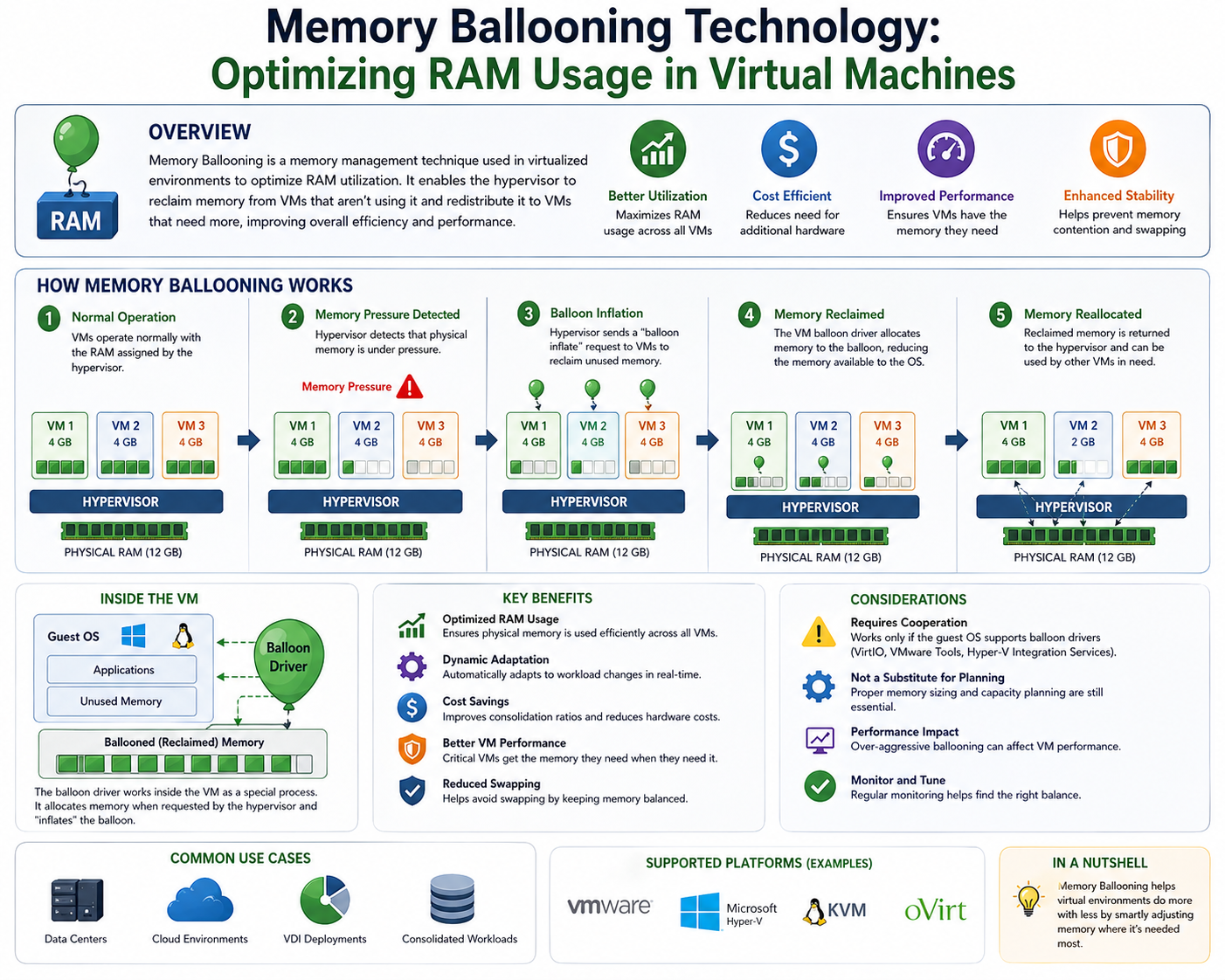
Introduction to Memory Ballooning in ESXi Architecture
Memory ballooning is one of the central mechanisms used by VMware ESXi to reclaim memory dynamically when physical RAM becomes constrained. Unlike static allocation models in traditional operating systems, ESXi operates in a highly dynamic environment where multiple virtual machines compete for the same finite physical memory pool. Ballooning acts as an intermediary control mechanism that allows the hypervisor to reclaim unused memory from virtual machines without immediately resorting to more disruptive techniques such as swapping.
The key design principle behind ballooning is controlled pressure redistribution. Instead of forcibly taking memory away from virtual machines at the hypervisor level, ESXi leverages a guest-level driver to negotiate memory release. This approach preserves performance stability while allowing the system to adapt to changing workload demands.
Ballooning becomes active only when the host experiences memory contention after initial optimization techniques such as page sharing have already been applied. It represents a mid-tier reclamation strategy in the ESXi memory hierarchy, balancing efficiency and minimal disruption.
VMware Tools Dependency and Balloon Driver Functionality
Memory ballooning is dependent on the presence of VMware Tools installed inside each virtual machine. VMware Tools includes a specialized kernel component known as the balloon driver. This driver acts as a communication bridge between the ESXi hypervisor and the guest operating system, enabling controlled memory reclamation from within the virtual machine itself.
When the ESXi host detects memory pressure, it signals the balloon driver to begin inflation. This process involves the driver allocating memory inside the guest operating system, effectively reserving memory pages at the guest level. As the guest OS experiences internal memory pressure due to this artificial allocation, it begins to release less critical or idle memory pages.
These released pages are then reclaimed by the hypervisor and reassigned to other virtual machines that require memory more urgently. The process is carefully orchestrated to ensure that memory is reclaimed from idle or low-priority areas within the guest rather than critical application segments.
The effectiveness of ballooning is directly tied to the presence and responsiveness of VMware Tools. Without the balloon driver, ESXi loses this intermediate reclamation layer and must rely on more aggressive techniques such as compression or swapping earlier in the memory pressure sequence.
Balloon Inflation Mechanism and Guest OS Interaction
The balloon driver operates by inflating within the virtual machine’s memory space. This inflation is achieved by allocating memory pages inside the guest operating system in a controlled manner. As the balloon grows, it forces the guest OS to re-evaluate its memory usage priorities.
Operating systems typically maintain internal memory management structures that classify pages as active, inactive, cached, or free. When ballooning occurs, the guest OS is compelled to free up less critical memory pages, such as file caches or background buffers, to accommodate the balloon driver’s allocations.
This process creates a feedback loop between the hypervisor and guest OS memory management systems. The hypervisor indirectly influences guest memory behavior without directly interfering with application-level memory allocation. This separation of control is what makes ballooning both effective and relatively non-disruptive under normal operating conditions.
However, ballooning efficiency depends heavily on available reclaimable memory within the guest OS. If applications inside the virtual machine are actively consuming all available memory, ballooning becomes less effective, as there are fewer idle pages available for reclamation.
Conditions That Trigger Ballooning Activation
Ballooning is not continuously active but is triggered under specific memory pressure conditions. ESXi evaluates host memory usage in real time and activates ballooning when free physical memory drops below a defined threshold. This threshold-based activation ensures that ballooning is only used when necessary and not as a constant background process.
The hypervisor follows a structured memory reclamation hierarchy. Before ballooning is triggered, ESXi attempts to optimize memory usage using techniques such as page sharing and internal optimization. If these methods are insufficient to relieve memory pressure, ballooning is initiated.
The activation of ballooning is also influenced by virtual machine priority settings, memory reservations, and shares. High-priority workloads with reserved memory allocations may experience reduced ballooning impact compared to lower-priority virtual machines that operate without strict memory guarantees.
This prioritization mechanism ensures that critical workloads remain stable even during periods of memory contention.
Performance Characteristics of Ballooning Under Normal Load
Under moderate memory pressure conditions, ballooning is generally considered a non-disruptive process. Since it primarily targets idle or low-usage memory pages within the guest operating system, application-level performance is typically unaffected in stable environments.
The inflation process is gradual and adaptive, meaning that memory is reclaimed incrementally rather than in large abrupt allocations. This allows the guest OS to adjust its internal memory structures without triggering significant performance degradation.
In well-balanced environments where memory overcommitment is carefully managed, ballooning may occur intermittently and remain largely invisible to application workloads. It functions as a safety mechanism that prevents the system from escalating to more aggressive reclamation strategies.
However, the non-disruptive nature of ballooning is contingent on proper infrastructure sizing. If memory overcommitment is excessive or sustained, ballooning may become continuous, indicating underlying resource imbalance.
Ballooning in Overcommitted and High-Density Environments
In heavily virtualized environments where memory overcommitment is aggressive, ballooning becomes a frequent operational mechanism. In such scenarios, the hypervisor continuously reallocates memory between virtual machines to maintain system stability.
While ballooning allows higher consolidation ratios, it also introduces complexity in memory behavior analysis. Administrators must interpret ballooning activity as a sign of memory contention rather than a performance issue in isolation.
High-density environments amplify the importance of understanding memory allocation patterns. Virtual machines with unpredictable workloads or memory spikes can trigger frequent ballooning cycles, which may indirectly affect overall system responsiveness.
In such cases, ballooning acts as a stabilizing mechanism, but it also signals the need for workload balancing or infrastructure scaling.
Limitations of Ballooning in Real-World Workloads
Despite its efficiency, ballooning has inherent limitations. One of the primary constraints is dependency on guest OS behavior. If the guest operating system is already utilizing all available memory for active processes, there is limited capacity for reclamation.
Certain application types, particularly memory-intensive databases and in-memory processing systems, may not release significant memory even under balloon pressure. In these cases, ballooning becomes ineffective, forcing ESXi to escalate to more aggressive reclamation techniques.
Another limitation arises from latency in memory redistribution. While ballooning is relatively fast compared to disk-based swapping, it still introduces a delay in memory adjustment that may not be suitable for highly latency-sensitive workloads.
Additionally, excessive ballooning activity can create internal fragmentation within guest memory management systems, potentially increasing CPU overhead as the operating system continuously reorganizes memory allocations.
Monitoring Ballooning Behavior in ESXi Environments
Ballooning activity is continuously monitored by ESXi through performance counters and host-level metrics. These metrics provide insight into how much memory is currently being reclaimed through ballooning across the host.
At a high level, ballooning metrics help administrators understand whether memory contention is temporary or systemic. Sporadic ballooning events typically indicate normal workload fluctuations, while sustained ballooning activity suggests chronic memory overcommitment.
Within the hypervisor’s monitoring framework, ballooning is categorized separately from other memory reclamation techniques such as compression and swapping. This separation allows precise analysis of memory pressure stages and helps identify when the system is transitioning between different reclamation levels.
Monitoring ballooning trends over time is essential for capacity planning. Increasing balloon activity may indicate the need for additional physical memory or workload redistribution across multiple hosts.
Ballooning as a Transitional Memory Control Layer
Ballooning occupies a transitional position within ESXi’s memory management hierarchy. It sits between passive optimization techniques like page sharing and more aggressive mechanisms such as compression and swapping.
Its primary role is to delay escalation to high-impact memory reclamation strategies. By reclaiming idle memory early, ballooning reduces the likelihood of performance degradation caused by disk-based memory operations.
This transitional nature makes ballooning a critical stabilizing component in ESXi architecture. It ensures that memory pressure is managed incrementally rather than abruptly, preserving workload continuity even under fluctuating demand.
Interaction Between Ballooning and Host Memory Scheduling
The ESXi memory scheduler coordinates ballooning activity across all running virtual machines. It evaluates memory demand distribution and determines which virtual machines are most suitable for memory reclamation.
This decision-making process is influenced by multiple factors, including memory shares, reservations, and current workload behavior. Virtual machines with lower priority or lower active memory usage are typically selected first for ballooning.
The scheduler continuously adapts its decisions based on real-time memory pressure conditions. This dynamic adjustment ensures that ballooning is applied efficiently without disproportionately affecting critical workloads.
The interaction between ballooning and scheduling demonstrates the deeply integrated nature of ESXi memory management, where multiple subsystems work in coordination to maintain stability.
Role of Ballooning in Preventing Immediate Swapping
One of the most important functions of ballooning is its role in delaying or preventing memory swapping. Swapping represents the most disruptive memory reclamation technique because it involves moving memory pages to disk, significantly increasing latency.
By reclaiming idle memory early, ballooning reduces the likelihood that ESXi will need to resort to swapping. This helps preserve application performance and prevents sudden degradation during memory pressure spikes.
In this sense, ballooning acts as a protective buffer between normal operation and high-impact reclamation scenarios. It absorbs memory pressure gradually, allowing the system to stabilize without triggering severe performance penalties.
Operational Implications of Sustained Ballooning Activity
When ballooning becomes persistent rather than occasional, it indicates structural imbalance in memory allocation. This may result from excessive overcommitment, insufficient physical memory provisioning, or inefficient workload distribution.
Sustained ballooning does not necessarily cause immediate failures, but it does signal reduced memory headroom across the host. Over time, this can lead to increased reliance on compression and swapping, which negatively impact performance.
From an operational perspective, persistent ballooning is often treated as an early warning indicator. It suggests that memory resources are operating close to their limits and that corrective actions may be required to maintain long-term stability.
Integration of Ballooning Within the ESXi Memory Hierarchy
Ballooning is part of a multi-layered memory management framework that includes page sharing, compression, and swapping. Each layer operates at a different level of aggressiveness and performance impact.
Ballooning’s position in this hierarchy ensures that it is used after passive optimization but before disruptive reclamation. This structured approach allows ESXi to maintain a balance between efficiency and performance stability.
The coordination between these layers ensures that memory is managed dynamically and adaptively based on real-time system conditions. Ballooning plays a central role in this adaptive model by providing a flexible and responsive reclamation mechanism that operates within guest operating systems while being controlled by the hypervisor.
Transition From Ballooning to High-Pressure Memory States
When VMware ESXi exhausts low-impact memory reclamation techniques such as Transparent Page Sharing and memory ballooning, the hypervisor transitions into higher-pressure memory management stages. This transition occurs when physical memory demand exceeds the ability of these earlier mechanisms to maintain stability across all running virtual machines.
At this stage, ESXi begins to implement more aggressive strategies that directly affect memory representation efficiency and storage behavior. Unlike ballooning, which relies on guest-level cooperation, these later mechanisms operate more directly at the hypervisor layer and have a higher probability of impacting performance.
The escalation is not immediate but follows a structured decision-making process within the ESXi memory scheduler. The scheduler continuously evaluates host memory availability, reclaim effectiveness, and workload priority before activating compression or swapping.
This layered approach ensures that performance degradation is introduced gradually rather than abruptly, preserving operational continuity as long as possible.
Memory Compression as a Latency-Optimized Reclamation Technique
Memory compression is introduced when ballooning is insufficient to free enough physical memory to satisfy active demand. Unlike swapping, which relies on disk storage, compression attempts to reduce the size of memory pages in RAM before considering disk-based operations.
The fundamental principle behind memory compression is data reduction through in-memory encoding. ESXi identifies memory pages that can be compressed and stores them in a compressed format within a designated memory cache. This allows more pages to fit within the same physical memory footprint, effectively increasing usable capacity without immediate reliance on slower storage systems.
Compression is applied selectively to memory pages that are deemed suitable for reduction. These typically include infrequently accessed pages or data structures with compressible patterns. Pages that are actively used or frequently modified are less likely to be compressed due to the overhead associated with repeated compression and decompression cycles.
The compression process introduces computational overhead, as CPU cycles are required to encode and decode memory pages. However, this trade-off is considered acceptable compared to the significantly higher latency cost of disk-based swapping.
Compressed Memory Cache and Page Lifecycle Management
When memory pages are compressed, they are stored in a specialized compressed cache managed by ESXi. This cache acts as an intermediate storage layer between active memory and swap space. The goal is to retain compressed pages in RAM for as long as possible to avoid disk access.
The lifecycle of a compressed memory page involves multiple states. Initially, a page resides in active memory in its uncompressed form. When compression is triggered, the page is encoded and moved into the compressed cache. If the page is accessed again, it must be decompressed before use, introducing a small latency penalty.
If memory pressure persists and the compressed cache becomes full, ESXi may be forced to evict compressed pages to swap storage. This marks a transition from memory-based optimization to disk-based reclamation, which significantly increases access latency.
The compressed cache therefore functions as a buffer zone that delays the onset of more disruptive memory management actions. Its effectiveness is highly dependent on workload access patterns and memory reuse frequency.
Performance Characteristics of Memory Compression Under Load
Memory compression is generally considered a moderate-impact technique. It introduces CPU overhead but avoids the severe latency penalties associated with disk access. In environments with sufficient CPU headroom, compression can significantly improve memory efficiency without noticeable performance degradation.
However, in CPU-constrained environments, compression can introduce contention between memory management operations and application workloads. This can lead to increased CPU scheduling pressure, indirectly affecting virtual machine performance.
The performance impact of compression is also influenced by the compressibility of memory pages. Highly structured or repetitive data benefits more from compression, while already optimized or random data yields lower compression ratios, reducing effectiveness.
As a result, compression is most effective in environments where memory pressure is moderate and CPU resources are available to support additional processing overhead.
Memory Swapping as a Last-Resort Reclamation Mechanism
When all previous memory reclamation techniques are exhausted, ESXi resorts to memory swapping. Swapping represents the most aggressive form of memory management and is used only when physical memory demand cannot be satisfied through any other means.
Swapping involves moving memory pages from physical RAM to disk-based storage. Each virtual machine maintains a dedicated swap file that is created at power-on time. This file serves as the storage location for pages that must be evicted from physical memory during extreme pressure conditions.
Unlike compression, swapping introduces significant latency because disk access speeds are orders of magnitude slower than RAM access. Even with modern high-performance storage systems, swap operations remain a performance bottleneck.
Swapping is therefore considered a degradation mechanism rather than an optimization technique. Its primary purpose is to prevent system instability or virtual machine crashes when memory exhaustion occurs.
Host-Level Swap File Architecture and Allocation Strategy
Each virtual machine in ESXi has an associated swap file that matches its configured memory size. This file is reserved on disk and used exclusively when the hypervisor needs to offload memory pages from physical RAM.
The swap file is not actively used during normal operation but remains available as a fallback storage mechanism. When swapping is triggered, ESXi selects memory pages based on usage patterns and priority levels, moving less frequently accessed pages into swap storage.
The selection process is influenced by multiple factors, including memory activity, workload priority, and recent access history. Pages that are idle or rarely accessed are typically prioritized for swapping to minimize performance impact.
However, even with intelligent selection, swapping introduces unavoidable latency. Accessing swapped pages requires disk I/O operations, which significantly slow down memory retrieval compared to in-memory access.
Distinction Between Hypervisor Swapping and Guest OS Swapping
It is important to distinguish between hypervisor-level swapping and guest operating system swapping. ESXi swapping occurs at the hypervisor layer and affects how physical memory is managed across virtual machines.
In contrast, guest OS swapping occurs within the virtual machine itself when the operating system manages its own internal memory pressure. These two mechanisms operate independently but can compound performance issues when both are active simultaneously.
Hypervisor swapping is generally more critical because it indicates host-level memory exhaustion. When both hypervisor and guest-level swapping occur, system performance degradation becomes significantly more severe.
Understanding this distinction is essential for diagnosing memory-related performance issues in virtualized environments.
Performance Impact of Memory Swapping in Production Workloads
Memory swapping has the most significant performance impact among all ESXi memory reclamation techniques. Because it relies on disk storage, it introduces latency that can severely affect application responsiveness.
Workloads that depend on real-time processing, high-frequency transactions, or low-latency computation are particularly sensitive to swapping. Even small amounts of swap activity can result in noticeable performance degradation in such environments.
Swapping can also lead to cascading performance issues. As memory pages are moved to disk, applications may experience delays, causing increased CPU wait times and further memory pressure. This feedback loop can amplify system instability under extreme conditions.
For this reason, swapping is considered a last-resort mechanism that should ideally be avoided through proper capacity planning and workload distribution.
Memory Pressure Escalation Hierarchy in ESXi
ESXi follows a strict hierarchical model when managing memory pressure. This hierarchy ensures that the least disruptive techniques are applied first, escalating only when necessary.
The sequence typically begins with Transparent Page Sharing, followed by ballooning, then compression, and finally swapping. Each stage represents an increase in both reclaim effectiveness and performance impact.
This structured escalation ensures that memory is managed efficiently while minimizing disruption to running workloads. It also provides administrators with predictable behavior patterns when diagnosing memory-related issues.
The hierarchy is dynamic and continuously evaluated based on real-time system conditions, allowing ESXi to adapt to changing workloads.
Role of CPU and Storage Subsystems in Memory Reclamation
Memory compression and swapping introduce dependencies on CPU and storage subsystems. Compression relies heavily on CPU availability, while swapping depends on storage latency and throughput.
In environments with high CPU utilization, compression efficiency may decrease due to resource contention. Similarly, in environments with slow or heavily loaded storage systems, swapping can become a critical performance bottleneck.
This interdependence highlights the importance of balanced infrastructure design. Memory performance cannot be evaluated in isolation but must be considered in relation to CPU and storage performance characteristics.
ESXi attempts to mitigate these dependencies through adaptive scheduling and prioritization mechanisms, but hardware limitations ultimately define the upper bounds of performance.
Impact of Sustained Compression and Swapping Activity
When compression and swapping occur continuously, it indicates a persistent imbalance between memory demand and physical capacity. This state is often referred to as memory pressure saturation.
Sustained compression leads to increased CPU utilization, while sustained swapping leads to increased disk I/O load. Together, these conditions can significantly degrade overall system performance.
Over time, prolonged memory pressure can affect not only individual virtual machines but also host-level responsiveness. This makes early detection and remediation critical in maintaining stable environments.
Typical remediation strategies include workload redistribution, increasing physical memory capacity, or adjusting virtual machine memory allocations to reduce overcommitment.
Interaction Between Compression, Swapping, and Ballooning
Compression and swapping do not operate independently but interact closely with ballooning. When ballooning is insufficient to relieve memory pressure, compression is triggered. If compression also fails to meet demand, swapping is activated.
This cascading interaction ensures that each technique is applied in sequence based on severity of memory pressure. Ballooning reduces guest-level memory usage, compression optimizes in-memory storage efficiency, and swapping provides a fallback mechanism for extreme conditions.
The coordination between these mechanisms is managed by the ESXi memory scheduler, which continuously evaluates system state and adjusts reclamation strategies accordingly.
System Stability Considerations Under Extreme Memory Load
Under extreme memory pressure, ESXi prioritizes system stability over performance. This means that even if swapping introduces latency, it is still preferred over potential system crashes or virtual machine termination.
The hypervisor is designed to maintain operational continuity even in degraded performance states. Memory reclamation techniques are therefore structured to ensure that the system remains functional under all conditions, even if performance is temporarily reduced.
This design philosophy reflects the core objective of virtualization platforms: maximizing resource utilization while maintaining isolation and stability.
Final Layer Behavior of ESXi Memory Management System
The final layer of ESXi memory management represents a fully saturated system where all optimization and reclamation techniques are active simultaneously. In this state, the hypervisor operates under maximum memory pressure and relies heavily on compression and swapping to maintain functionality.
While this condition is not ideal, it demonstrates the resilience of the ESXi architecture. The system is capable of adapting to extreme resource constraints while maintaining virtual machine execution.
However, sustained operation in this state is not recommended, as it indicates a fundamental mismatch between workload demand and physical infrastructure capacity.
The memory management system is therefore best understood as a continuously adaptive hierarchy that balances efficiency, performance, and stability across multiple layers of abstraction.
Conclusion
VMware ESXi memory management is best understood as a layered, adaptive control system rather than a single mechanism or isolated feature set. A consistent architectural pattern emerges: the hypervisor continuously evaluates memory demand, applies increasingly aggressive reclamation techniques only when necessary, and prioritizes system stability over raw performance preservation. This progressive escalation model is what allows high-density virtualization environments to function reliably even under sustained overcommitment conditions.
At the foundation of this system is the principle of memory abstraction. ESXi does not treat memory as a fixed allocation bound to each virtual machine. Instead, it operates a dynamic mapping layer that decouples virtual memory from physical hardware. This abstraction enables the hypervisor to redistribute, compress, deduplicate, or relocate memory pages without disrupting guest operating systems. The result is a flexible environment where memory becomes a shared and optimizable resource rather than a rigid hardware constraint.
Transparent Page Sharing represents the earliest optimization layer in this hierarchy. Its role is fundamentally structural rather than reactive. By identifying duplicate memory pages and consolidating them, ESXi reduces baseline memory consumption before any pressure conditions arise. This mechanism is particularly effective in environments with homogeneous workloads, where operating systems and application stacks share significant memory similarities. Even though modern security policies have reduced its scope in cross-virtual machine scenarios, its contribution to intra-workload efficiency remains relevant in controlled deployments.
As memory demand increases, the system transitions into ballooning, which introduces a cooperative reclaim model between hypervisor and guest operating system. This stage is critical because it shifts memory recovery from passive optimization to active negotiation. The balloon driver inside each virtual machine enables ESXi to indirectly influence guest memory behavior, reclaiming idle or low-priority memory pages without immediate performance degradation. Ballooning is especially important because it delays the need for more intrusive mechanisms, acting as a buffer layer between normal operation and high-pressure memory states.
However, ballooning is not a universal solution. Its effectiveness depends on workload characteristics, available idle memory within guest systems, and the responsiveness of applications to internal memory pressure. In environments where applications already consume nearly all allocated memory, ballooning loses efficiency, forcing the hypervisor to escalate further. This limitation highlights an important reality of virtualization design: no single mechanism can fully resolve memory contention under all conditions.
When both page sharing and ballooning are insufficient, ESXi introduces memory compression. This stage represents a shift from memory redistribution to memory transformation. Instead of reclaiming memory from workloads, the hypervisor attempts to reduce the physical footprint of active pages by compressing them in memory. Compression allows ESXi to extend usable capacity without immediately resorting to disk-based operations, making it a critical performance-preserving bridge layer.
Despite its advantages, compression introduces CPU overhead and is inherently limited by the compressibility of data. Workloads with highly random or already optimized memory structures yield lower compression efficiency, reducing its overall benefit. Nevertheless, in many real-world scenarios, compression provides enough additional headroom to prevent immediate escalation into swapping, which is significantly more disruptive.
Swapping represents the final and most aggressive stage of ESXi memory management. Unlike earlier techniques, swapping directly involves disk storage, moving memory pages from RAM to a dedicated swap file. This transition introduces substantial latency due to the inherent speed gap between memory and storage systems. While modern storage architectures have reduced the severity of this impact, swapping remains the least desirable state from a performance perspective.
The presence of swapping indicates that all previous optimization layers have been exhausted. At this point, ESXi prioritizes system continuity over responsiveness, ensuring that virtual machines remain operational even under extreme memory pressure. However, sustained swapping is a clear indicator of resource imbalance and often signals the need for infrastructure scaling or workload redistribution.
What makes ESXi memory management particularly effective is not any single technique, but the orchestration between all layers. Each mechanism is designed to activate at a specific threshold, ensuring a gradual degradation model rather than sudden performance collapse. This hierarchy allows administrators to operate with higher consolidation ratios while still maintaining predictable system behavior under stress.
Another critical aspect of this architecture is its continuous evaluation model. ESXi does not react only when memory exhaustion occurs. Instead, it constantly monitors usage patterns, page activity, and host-level pressure indicators. This continuous feedback loop ensures that optimization occurs proactively rather than reactively, improving overall efficiency even in stable conditions.
From an operational standpoint, understanding this hierarchy is essential for capacity planning. Memory overcommitment is not inherently problematic; it is a designed feature of virtualization platforms. However, its effectiveness depends on balancing physical resources with workload characteristics. Environments with predictable, low-variance workloads can safely achieve higher consolidation ratios, while environments with unpredictable or memory-intensive applications require more conservative configurations.
Monitoring plays a central role in maintaining this balance. Indicators such as balloon activity, compression rates, and swap usage provide insight into how far the system has progressed through the memory reclamation hierarchy. These signals are not isolated metrics but interconnected indicators of overall memory health. Rising balloon activity may suggest early pressure, while compression indicates moderate stress, and swapping signals critical saturation.
The broader implication of ESXi memory management is that virtualization efficiency is achieved through controlled complexity. Instead of relying on static allocation models, the hypervisor continuously reshapes memory distribution based on real-time demand. This dynamic behavior allows infrastructure to scale beyond traditional physical limitations while maintaining operational stability.
Ultimately, ESXi memory management reflects a design philosophy centered on adaptability. It assumes that workloads are dynamic, memory demand is unpredictable, and efficiency must be continuously optimized rather than statically defined. Through layered mechanisms such as page sharing, ballooning, compression, and swapping, ESXi constructs a resilient memory ecosystem capable of handling both stable and extreme conditions.
This adaptability is what enables modern virtualized infrastructures to support high-density deployments without proportional increases in physical hardware. It also underscores the importance of understanding memory behavior not as a single resource metric but as a continuously evolving system of interactions between hypervisor, guest operating systems, and underlying hardware.
In essence, ESXi does not simply manage memory; it orchestrates it across multiple layers of abstraction, ensuring that every available resource is utilized efficiently while preserving system integrity under all operating conditions.