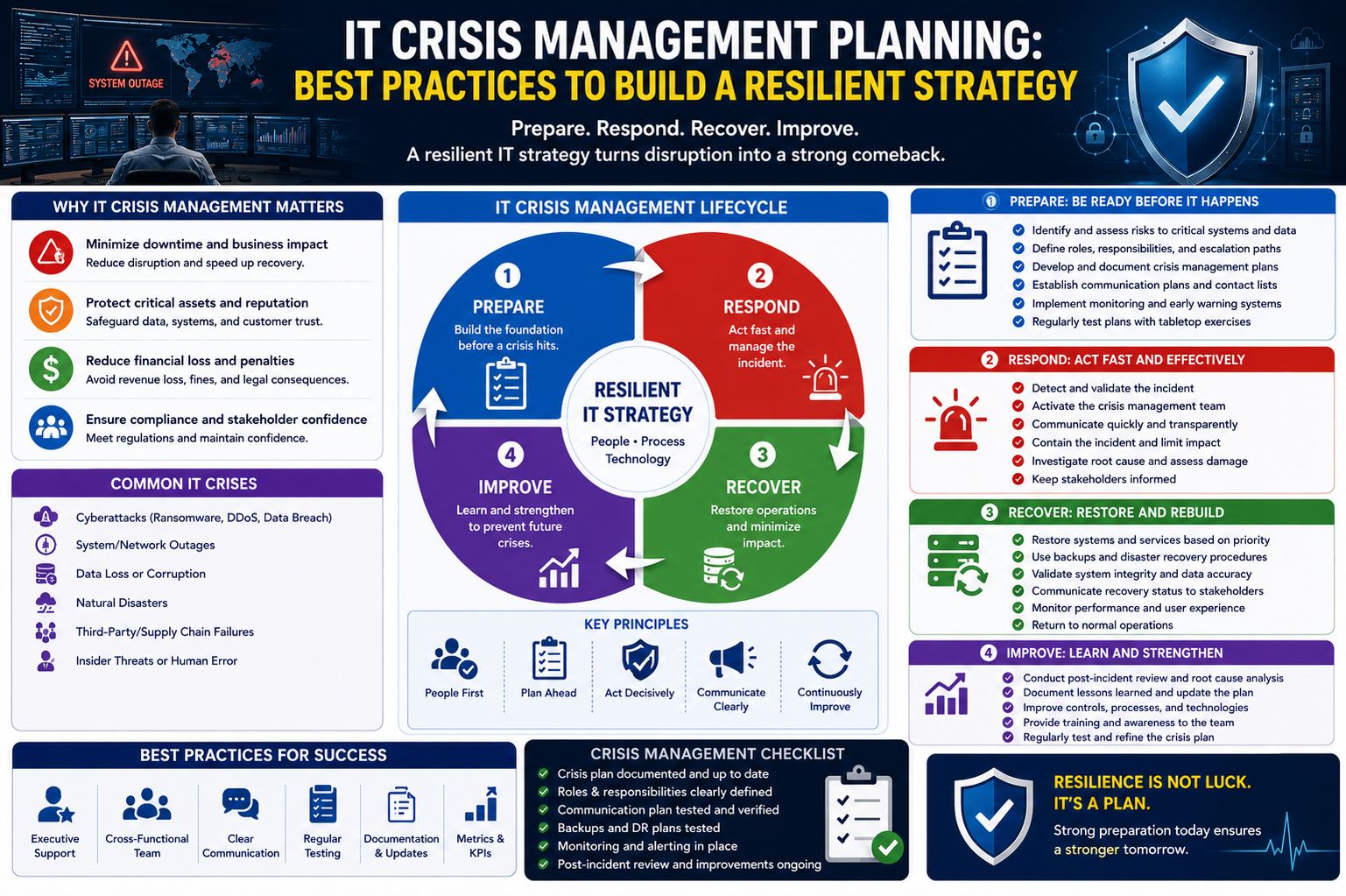
Modern organizations rely heavily on digital systems to maintain operations, store sensitive information, and support communication across teams. Because of this dependency, even a short disruption in IT services can have widespread consequences. Systems may go offline, data can become inaccessible, and business activities may slow down or stop entirely. These disruptions are not always predictable, which makes preparation essential rather than optional. An IT crisis management plan provides structure during uncertain situations and helps teams respond with clarity instead of confusion. Without such preparation, organizations often react in a fragmented way, which can increase damage and extend recovery time. Building a structured approach ensures that when unexpected events occur, teams are not improvising under pressure but following a tested and coordinated response.
What an IT Crisis Means in Practice
An IT crisis refers to any sudden event that significantly disrupts normal technology operations or compromises the integrity, availability, or confidentiality of systems and data. These events can vary widely in origin and severity. Cybersecurity incidents such as ransomware attacks or unauthorized access attempts can quickly escalate and lock critical systems. Infrastructure failures may occur when servers malfunction, storage devices fail, or network components stop responding. Environmental events such as floods, fires, or power failures can also interrupt data center operations. In many cases, human mistakes contribute to crises, such as accidental deletion of essential files, incorrect system configurations, or improper deployment of updates. Although the causes differ, the effects are often similar: interrupted services, financial losses, reduced productivity, and reputational damage. Recognizing these possibilities is the first step toward effective planning.
Building a Risk Awareness Foundation
A strong crisis management approach begins with understanding where weaknesses exist. Organizations must evaluate their systems, processes, and dependencies to identify points of vulnerability. This involves examining how data is stored, how systems are connected, and how recovery mechanisms are structured. Outdated backups, unpatched systems, or weak authentication practices often represent hidden risks that become critical during emergencies. Reviewing these areas regularly helps create a realistic picture of exposure. Scenario analysis is also useful, as it allows teams to imagine how different types of disruptions might unfold. By studying potential failure points in advance, organizations can prioritize improvements and reduce the likelihood of severe impact. Risk awareness is not a one-time activity but a continuous process that evolves alongside technology and operational changes.
Designing a Structured Response Framework
Once risks are identified, the next step is to establish a clear response structure. This framework defines how the organization reacts when a crisis occurs. It should outline responsibilities so that every team member knows their role during an incident. Leadership responsibilities must be clearly assigned to ensure decision-making is not delayed. Technical teams should understand which systems they are responsible for restoring, while communication teams handle updates to internal and external stakeholders. Step-by-step response procedures should be developed for different types of incidents, allowing teams to act quickly without confusion. For example, responses to data breaches will differ from responses to hardware failures, but both require predefined actions. The goal of this framework is to reduce uncertainty and ensure coordinated effort under pressure.
Establishing Clear Communication Channels
Communication plays a critical role during any IT disruption. When systems fail, uncertainty spreads quickly, and misinformation can make the situation worse. Internally, teams need a reliable way to share updates in real time so that everyone understands the current status of the incident. Externally, customers, partners, and stakeholders may require timely and accurate information to maintain trust. Establishing communication protocols in advance ensures that messages are consistent and controlled. It is also important to define who is authorized to communicate on behalf of the organization during a crisis. Pre-prepared message templates can help speed up communication while maintaining clarity. Effective communication reduces confusion, prevents panic, and supports coordinated recovery efforts.
Using Continuous Monitoring and Early Detection
Preventing escalation is often possible when issues are detected early. Continuous monitoring systems provide visibility into network activity, application performance, and system behavior. These tools help identify unusual patterns that may indicate emerging problems. Early detection allows teams to respond before a situation becomes critical. Automated alerts can notify relevant personnel when thresholds are exceeded or abnormal activity is detected. In more advanced environments, intelligent systems can analyze trends and predict potential failures. However, monitoring alone is not enough; it must be paired with a response process that ensures alerts are acted upon promptly. Early intervention significantly reduces downtime and limits the overall impact of disruptions.
Containing and Controlling Active Incidents
When a crisis occurs, immediate containment becomes the priority. The objective is to prevent the issue from spreading and affecting additional systems. This may involve isolating affected servers, restricting network access, or disabling compromised accounts. Quick containment helps limit damage while allowing technical teams to assess the situation. After containment, controlled remediation efforts can begin. This may include applying patches, restoring systems from backups, or reconfiguring affected components. Care must be taken during this stage to avoid introducing additional errors. A measured approach is more effective than rushed actions, as it ensures stability while addressing the root cause of the issue.
Ensuring Recovery and Operational Continuity
Once the immediate threat is under control, focus shifts to restoring normal operations. Recovery involves bringing systems back online in a structured and reliable manner. Reliable backups play a key role in this stage, but their effectiveness depends on regular testing and validation. Recovery plans should prioritize critical systems first to ensure essential business functions resume quickly. Gradual restoration helps prevent overload and reduces the risk of further disruptions. Continuity planning also involves preparing alternative ways to maintain operations if primary systems remain unavailable for an extended period. The goal is not only to recover but also to ensure stability throughout the process.
Training Teams for Real-World Preparedness
A well-designed plan is only effective if the people responsible for executing it are properly trained. Regular practice through simulated incidents helps teams understand their roles and responsibilities. These exercises should reflect realistic scenarios that challenge both technical and decision-making skills. Reviewing performance after each exercise helps identify gaps and areas for improvement. Collaboration between different departments is also essential, as IT crises often affect multiple areas of an organization. Legal, operational, and communication teams may all be involved in managing the response. Building familiarity across departments improves coordination and reduces delays during real incidents. A prepared team is more confident and capable when facing unexpected challenges.
Learning and Improving After an Incident
After a crisis has been resolved, it is important to analyze what occurred and how the response was handled. This review process helps identify strengths and weaknesses in the existing plan. Understanding the root cause of the incident allows organizations to prevent similar events in the future. It is equally important to evaluate how effectively the response procedures worked under pressure. Any delays, miscommunications, or technical issues should be documented and addressed. Based on these findings, response plans should be updated to reflect new insights. Continuous improvement ensures that each incident becomes an opportunity to strengthen overall resilience.
Best Practices for Long-Term Resilience
Maintaining effective crisis readiness requires ongoing attention. Documentation should always be kept up to date so that teams can quickly access necessary information during emergencies. This includes system details, recovery procedures, and contact information for key personnel. Flexibility is also important, as no two crises are identical. Teams should be encouraged to adapt based on the situation while still following established guidelines. Transparency during incidents helps build trust and reduces uncertainty among stakeholders. Additionally, maintaining strong collaboration across departments improves response efficiency. External expertise may also be useful in complex situations where specialized knowledge is required. These practices collectively strengthen an organization’s ability to handle disruptions effectively.
Conclusion
IT crises are an unavoidable aspect of modern digital operations, but their impact can be significantly reduced through preparation and structured response planning. Organizations that invest time in understanding risks, defining clear procedures, and training their teams are better equipped to handle unexpected disruptions. A strong crisis management approach does not eliminate problems, but it ensures they are managed in a controlled and efficient manner. Over time, continuous improvement and experience strengthen organizational resilience. The ability to respond calmly and effectively during disruption is what ultimately separates stable operations from vulnerable ones.