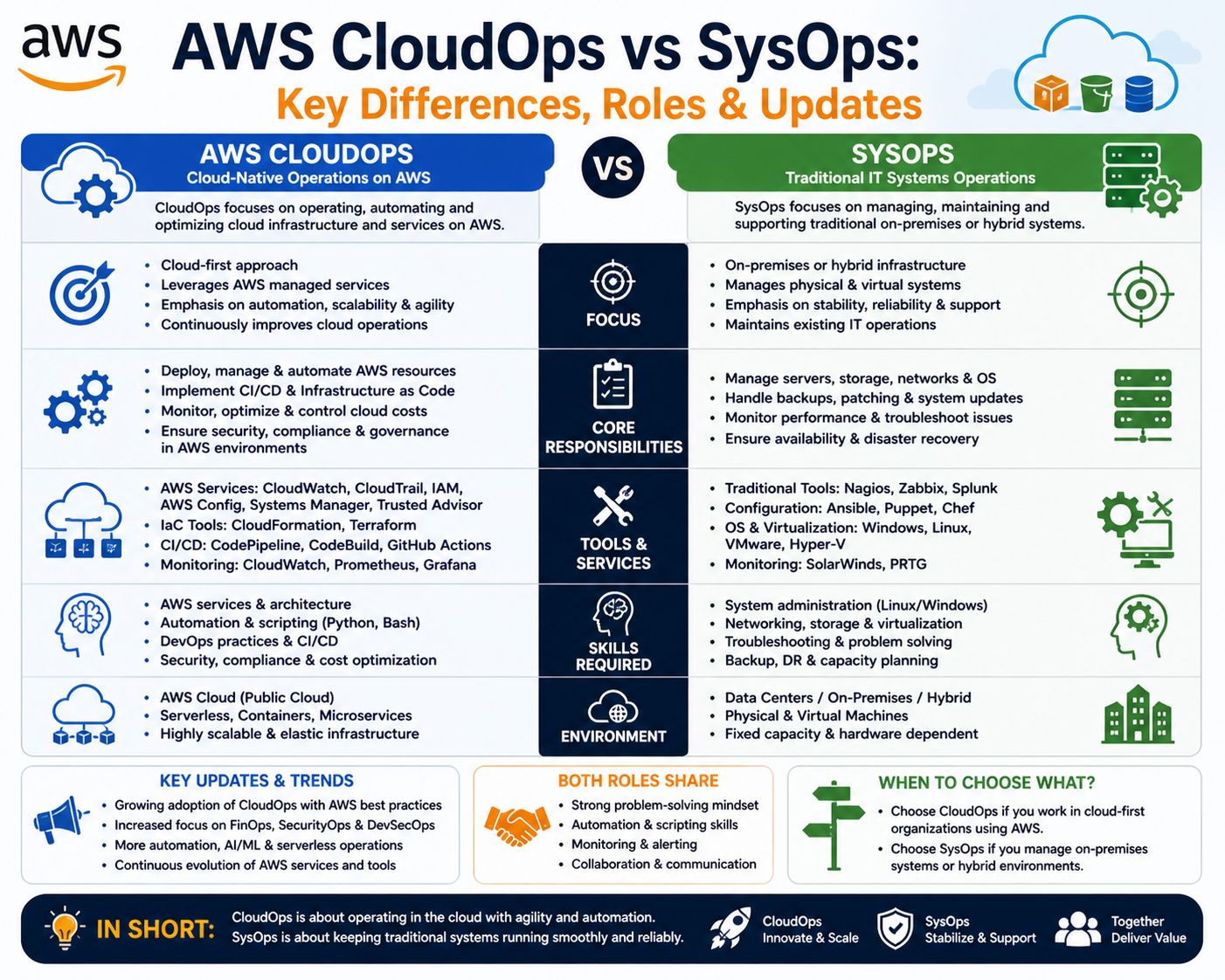
The transition from SysOps to CloudOps represents a deep structural transformation in IT operations rather than a simple terminology update. Traditional SysOps environments were designed around fixed physical infrastructure where system administrators directly controlled servers, storage devices, and network components inside on-premises data centers. Operational tasks were heavily manual and included hardware maintenance, system patching, configuration management, and uptime monitoring. These environments were stable, predictable, and built on the assumption that infrastructure changes were rare and carefully scheduled. Capacity planning followed long procurement cycles, and scaling required purchasing and installing new hardware, which often led to overprovisioning to handle peak demand. Change management processes were rigid, emphasizing caution and stability over speed, and deployments were typically infrequent due to the risks associated with modifying live systems.
With the rapid adoption of cloud computing, this model became insufficient. Infrastructure is now abstracted into virtual resources that can be created, modified, and destroyed on demand. Systems are distributed across multiple regions and availability zones, and scaling happens dynamically based on workload demand rather than manual intervention. This shift introduces a level of flexibility that was previously unattainable, allowing organizations to respond instantly to traffic fluctuations, business requirements, and global user demands. CloudOps emerged as a response to this transformation, introducing an operational mindset focused on automation, elasticity, observability, and continuous improvement. Instead of maintaining static systems, the focus is now on managing constantly evolving environments that behave like programmable ecosystems.
In this new paradigm, infrastructure is treated as code, enabling teams to define, deploy, and manage environments through version-controlled templates. This approach ensures consistency across environments and reduces the likelihood of configuration drift, which was a common issue in traditional setups. Automated pipelines replace manual processes, allowing infrastructure provisioning, application deployment, and updates to occur in a controlled and repeatable manner. As a result, organizations can achieve faster release cycles while maintaining high levels of reliability and stability.
Limitations of Traditional SysOps in Cloud Environments
SysOps methodologies were effective in traditional IT environments where systems followed predictable lifecycle patterns. However, cloud environments introduced a fundamentally different operational reality where infrastructure is highly dynamic and workloads can change within seconds. This creates a challenge for manual operational processes that depend on human intervention. In legacy environments, administrators could rely on scheduled maintenance windows, controlled deployments, and fixed system boundaries. In contrast, cloud systems operate continuously, often without downtime, requiring changes to be implemented in real time without disrupting service availability.
Modern cloud applications are built using distributed microservices architectures, where multiple independent services interact continuously. Each service may scale independently, fail independently, or deploy updates independently. This level of complexity makes traditional troubleshooting methods inefficient and often reactive rather than proactive. SysOps approaches struggle to manage real-time scaling, automated deployments, distributed logging, and cross-region redundancy. Additionally, dependency chains between services make it difficult to isolate failures quickly, as a single issue can cascade across multiple components. As systems become more interconnected and dynamic, the limitations of manual operational control become more apparent, requiring a shift toward automation-driven operational frameworks. Without automation, maintaining consistency, reliability, and performance at scale becomes nearly impossible.
Emergence of Cloud-Native Operational Systems
Cloud-native computing introduced a new architectural paradigm where applications are no longer tied to physical machines or static environments. Instead, workloads run in containers that are orchestrated across clusters capable of automatically handling scaling, failover, and resource allocation. This abstraction allows infrastructure to be treated as a flexible and programmable layer rather than a fixed asset. It also enables rapid deployment cycles, where applications can be updated frequently without impacting overall system stability.
Infrastructure as code plays a critical role in this model by allowing environments to be defined through declarative configurations. Entire systems can be recreated consistently across development, testing, and production environments. This improves reliability, reduces configuration drift, and ensures predictable deployment outcomes. CloudOps aligns with this paradigm by focusing on managing these dynamic systems through automation, orchestration, and continuous monitoring rather than manual configuration or intervention. Furthermore, cloud-native systems encourage modular design, enabling teams to develop, deploy, and scale individual components independently. This increases flexibility while also demanding more sophisticated operational strategies to maintain system coherence.
Automation as the Core of Cloud Operations
Automation is one of the defining pillars of CloudOps and fundamentally changes how IT systems are managed. Tasks that previously required manual execution—such as provisioning servers, configuring networks, deploying applications, applying security updates, and scaling infrastructure—are now handled through automated workflows and scripts. This shift significantly reduces the time required to deploy and maintain systems while improving accuracy and consistency.
Infrastructure as code enables organizations to define entire environments using reusable templates, ensuring consistency across deployments and reducing human error. Automation also extends into operational intelligence, where monitoring systems continuously analyze performance metrics, logs, and traces to detect anomalies. In advanced implementations, automated remediation systems can resolve incidents without human involvement, significantly reducing downtime and improving service reliability. This shift allows operations teams to focus on optimization, architecture, and system design rather than repetitive manual tasks. Over time, automation also enables organizations to build self-service capabilities, where development teams can deploy and manage resources independently within controlled boundaries.
Security and Compliance in Cloud Environments
Security in cloud environments operates on a fundamentally different model compared to traditional systems. Instead of relying on physical boundaries and isolated networks, cloud security is built around identity, access control, encryption, and continuous policy enforcement. Resources are distributed globally, which makes perimeter-based security insufficient for modern infrastructures. This requires a more granular and adaptive approach to protecting systems and data.
CloudOps integrates security directly into operational workflows through identity and access management systems that define granular permissions for users and services. Encryption is applied both at rest and in transit, while logging and monitoring systems continuously track access patterns and system behavior. Compliance is no longer a periodic activity but a continuous process, where systems are constantly evaluated against regulatory and organizational standards. This ensures that infrastructure remains secure and compliant even as it evolves dynamically through scaling, updates, or configuration changes. Additionally, automated compliance checks and policy enforcement mechanisms help organizations maintain governance without slowing down innovation, allowing them to scale securely while meeting strict regulatory requirements.
Changing Role of IT Operations Professionals
The role of IT operations professionals has undergone a significant transformation with the rise of CloudOps. Instead of focusing primarily on physical infrastructure management, professionals now operate in highly automated, distributed environments. Their responsibilities include managing cloud resources, optimizing system performance, and ensuring reliability across complex architectures.
Observability has become a core function of modern operations, where logs, metrics, and traces are continuously analyzed to understand system behavior in real time. Operators work closely with automation pipelines, improving deployment processes, refining infrastructure templates, and ensuring systems can scale efficiently under varying workloads. This shift requires a strong understanding of cloud architecture, distributed computing, and performance engineering, moving the role from reactive support to proactive system optimization and design.
Increasing Demand for Cloud-Focused Operational Skills
The widespread adoption of cloud-first strategies has significantly increased demand for professionals skilled in CloudOps principles. Organizations now prioritize expertise in automation, infrastructure as code, cloud security, observability, and cost optimization.
Modern IT environments require professionals who can bridge the gap between development and operations, ensuring seamless deployment pipelines and continuous delivery workflows. The industry is moving toward fully automated, scalable, and resilient infrastructures where operational efficiency is achieved through intelligent system design rather than manual intervention. CloudOps represents this evolution, defining the modern standard for IT operations in cloud-driven ecosystems.
Operational Architecture in CloudOps Environments
CloudOps environments are built on distributed operational architectures designed to support elasticity, resilience, and continuous change. Unlike traditional infrastructures that rely on fixed hardware and static network layouts, cloud-based systems are composed of modular services that interact through APIs, event streams, and managed orchestration layers. This architecture is inherently decentralized, meaning no single system or node is responsible for overall functionality. Instead, workloads are distributed across regions and availability zones, ensuring redundancy and fault tolerance by design.
At the core of CloudOps architecture is the principle of abstraction. Infrastructure components such as compute, storage, and networking are no longer directly managed at a hardware level. Instead, they are consumed as services that expose programmable interfaces. This allows operational teams to interact with infrastructure through declarative configurations rather than manual setup procedures. As a result, environments can be reproduced consistently, scaled dynamically, and modified without disrupting system stability. The architecture is intentionally designed to support continuous delivery and continuous improvement cycles.
Infrastructure as Code as a Foundational CloudOps Principle
Infrastructure as code is one of the most critical practices in CloudOps because it transforms infrastructure management into a software engineering discipline. Instead of manually configuring systems, environments are defined using machine-readable templates that describe compute resources, networking rules, storage configurations, and security policies.
This approach introduces version control into infrastructure management, allowing changes to be tracked, reviewed, and rolled back when necessary. It also enables consistent deployment across multiple environments, reducing configuration drift and eliminating discrepancies between development, staging, and production systems. Infrastructure definitions can be reused and parameterized, making large-scale deployments more efficient and predictable.
In CloudOps, infrastructure as code is not limited to provisioning resources. It extends into lifecycle management, where updates, scaling operations, and decommissioning are all controlled through automated pipelines. This reduces dependency on manual intervention and ensures that infrastructure changes follow standardized processes, improving both reliability and security.
Automation Pipelines and Continuous Operations
Automation pipelines form the operational backbone of CloudOps environments. These pipelines are designed to handle repetitive and complex tasks without human involvement, ensuring consistency and efficiency across all stages of system management.
A typical automation pipeline includes stages such as infrastructure provisioning, application deployment, configuration management, testing, validation, and monitoring integration. Each stage is defined through scripts or declarative templates that execute in a predefined sequence. This structured approach ensures that systems are deployed in a controlled and predictable manner.
Continuous operations extend beyond deployment pipelines and include ongoing system maintenance tasks such as patch management, scaling decisions, and performance optimization. Automation systems continuously evaluate infrastructure state and apply adjustments as needed. For example, compute resources can be automatically scaled up during high traffic periods and scaled down during low usage intervals, optimizing both performance and cost efficiency.
Observability as a Core Operational Capability
Observability is a critical concept in CloudOps that focuses on understanding system behavior through data generated by applications and infrastructure. It is built on three primary pillars: metrics, logs, and traces. Together, these data sources provide a comprehensive view of system performance and health.
Metrics represent quantitative measurements such as CPU utilization, memory consumption, request latency, and error rates. Logs provide detailed event-level information that helps diagnose issues and understand system behavior. Traces track the flow of requests across distributed services, allowing operators to identify bottlenecks and performance degradation points.
In CloudOps environments, observability is not a passive function but an active operational component. Systems are continuously monitored, and alerts are generated automatically when predefined thresholds are exceeded. Advanced observability systems use anomaly detection and pattern recognition to identify issues before they impact end users. This enables proactive incident management and reduces mean time to resolution significantly.
Incident Management and Automated Recovery Systems
Incident management in CloudOps is highly automated and driven by predefined response workflows. When system anomalies are detected, automated systems categorize the severity of the issue and initiate appropriate response actions. This may include scaling resources, restarting services, rerouting traffic, or triggering failover mechanisms.
Automated recovery systems are designed to restore normal operations without requiring manual intervention. These systems rely on predefined recovery strategies that are executed based on real-time system conditions. For example, if a service becomes unresponsive, the system may automatically restart the affected container or replace it with a healthy instance from another availability zone.
This approach significantly reduces downtime and ensures high availability in distributed environments. It also allows operational teams to focus on root cause analysis and long-term improvements rather than immediate firefighting.
Cloud Security Operations and Identity-Centric Models
Security operations in CloudOps are built around identity-based access control rather than traditional network boundaries. Every user, application, and service is assigned a unique identity with specific permissions that define what resources they can access and what actions they can perform.
This model ensures that access is tightly controlled and follows the principle of least privilege. Security policies are enforced programmatically, meaning they are embedded directly into infrastructure definitions and automation workflows. This reduces the risk of misconfiguration and unauthorized access.
Encryption is applied at multiple layers, including data at rest, data in transit, and sometimes even data in processing environments. Continuous security monitoring ensures that unusual activity patterns are detected early, allowing for rapid response to potential threats. CloudOps integrates security into every stage of the operational lifecycle rather than treating it as a separate function.
Scalability and Elastic Resource Management
Scalability is one of the defining advantages of CloudOps environments. Systems are designed to automatically adjust resource allocation based on demand, ensuring optimal performance under varying workloads. This elasticity eliminates the need for manual capacity planning and reduces infrastructure waste.
Horizontal scaling is commonly used in CloudOps architectures, where additional instances of a service are deployed to handle increased traffic. Load balancing systems distribute requests across these instances to ensure consistent performance. When demand decreases, unnecessary resources are automatically decommissioned to optimize cost efficiency.
This dynamic scaling capability is supported by monitoring systems that continuously evaluate performance metrics and trigger scaling actions based on predefined thresholds. As a result, systems remain responsive and efficient even under unpredictable load conditions.
Cost Optimization Through Operational Intelligence
Cost management is an integral part of CloudOps, as cloud environments operate on usage-based pricing models. Operational intelligence systems continuously analyze resource utilization to identify inefficiencies and optimize spending.
Unused or underutilized resources are automatically flagged for review or decommissioning. Workloads are optimized to run on the most cost-effective infrastructure configurations without compromising performance. Reserved capacity strategies and dynamic scaling policies are also used to balance performance requirements with budget constraints.
Cost optimization is not treated as a separate financial process but as an embedded operational function. This ensures that infrastructure decisions are always aligned with both technical and financial objectives.
Configuration Management and System Consistency
Configuration management ensures that all systems within a CloudOps environment remain consistent and aligned with defined standards. This is achieved through automated configuration tools that enforce predefined system states across all environments.
Configuration drift, which occurs when systems diverge from their intended state, is continuously monitored and corrected automatically. This ensures that environments remain stable and predictable even as they scale or evolve.
By integrating configuration management into automation pipelines, CloudOps ensures that system changes are controlled, traceable, and reversible. This improves reliability and reduces the risk of inconsistencies across distributed systems.
Operational Maturity and Continuous Improvement Cycles
CloudOps environments are designed around continuous improvement principles. Systems are constantly monitored, analyzed, and optimized based on performance data and operational feedback. This creates a feedback loop where insights from observability systems directly influence infrastructure and application improvements.
Operational maturity is achieved when organizations move from reactive management to predictive and automated operations. At this stage, systems are capable of self-healing, self-optimizing, and self-scaling with minimal human intervention. This represents the highest level of CloudOps maturity, where operational efficiency is achieved through intelligent system design rather than manual control.
Enterprise Scale CloudOps Architecture and Design Principles
At enterprise scale, CloudOps evolves from basic operational automation into a highly structured, policy-driven, and globally distributed system of governance and execution. Large organizations operate across multiple cloud regions, hybrid environments, and sometimes multiple cloud providers simultaneously. This introduces a level of complexity that requires standardized architectural principles to maintain consistency, security, and performance.
Enterprise CloudOps architecture is built around modular service domains, where each domain is responsible for a specific function such as compute management, data processing, networking, or security enforcement. These domains are connected through controlled interfaces and governed by centralized policies. This separation of concerns allows teams to operate independently while still adhering to organizational standards.
A key principle at this level is abstraction of control layers. Infrastructure is no longer managed directly but through higher-level orchestration systems that enforce governance rules automatically. This ensures that even as environments scale across thousands of resources, consistency and compliance remain intact. The architecture is designed to support resilience, fault isolation, and rapid recovery from failures without disrupting global operations.
Multi-Region and Multi-Cloud Operational Strategies
Modern enterprises often distribute workloads across multiple geographic regions to ensure high availability, disaster recovery, and performance optimization. CloudOps at this level involves managing systems that operate across these regions seamlessly.
Multi-region strategies are designed to reduce latency by placing workloads closer to end users while also ensuring redundancy in case of regional failures. Data replication mechanisms ensure that critical information remains synchronized across locations, although consistency models may vary depending on workload requirements.
Multi-cloud strategies add another layer of complexity by introducing multiple cloud providers into the operational ecosystem. This approach is often adopted to avoid vendor lock-in, optimize cost structures, or leverage specialized services from different platforms. CloudOps teams must therefore manage interoperability between different systems, standardize deployment processes, and ensure consistent security policies across heterogeneous environments.
To manage this complexity, abstraction layers and orchestration tools are used to unify operations across environments. This allows teams to interact with multiple infrastructures through a single operational framework rather than managing each platform separately.
Governance Models and Policy-Driven Operations
Governance in CloudOps refers to the set of rules, policies, and controls that define how resources are created, managed, and secured within cloud environments. At enterprise scale, governance becomes essential to maintain control over large and distributed infrastructures.
Policy-driven operations ensure that all system changes comply with organizational standards automatically. Policies define constraints such as resource limits, access permissions, encryption requirements, and deployment rules. These policies are enforced programmatically, meaning violations are prevented or corrected without manual intervention.
Governance frameworks also include auditability mechanisms that track all changes within the system. Every infrastructure modification, deployment, and configuration update is logged and traceable. This ensures accountability and supports regulatory compliance requirements.
By embedding governance directly into automation pipelines, organizations reduce the risk of human error and ensure that all operational activities align with business objectives and regulatory constraints.
Advanced Automation and Intelligent Operations
At an advanced level, CloudOps automation evolves into intelligent operations where systems not only execute predefined tasks but also make adaptive decisions based on real-time data. This includes predictive scaling, automated performance tuning, and self-healing infrastructure behaviors.
Predictive automation uses historical data and machine learning models to anticipate system demand and adjust resources proactively. Instead of reacting to traffic spikes, systems scale in advance based on predicted usage patterns.
Self-healing systems automatically detect failures and initiate recovery procedures without human intervention. This may include restarting services, rerouting traffic, or replacing unhealthy nodes. These mechanisms significantly improve system resilience and reduce operational overhead.
Intelligent automation also extends to cost optimization, where systems continuously analyze resource usage and adjust configurations to minimize waste while maintaining performance targets.
Advanced Observability and Distributed System Intelligence
In enterprise CloudOps environments, observability becomes significantly more complex due to the scale and distribution of systems. Traditional monitoring is replaced by advanced observability platforms that aggregate data from thousands of services across multiple regions.
These systems not only collect metrics, logs, and traces but also correlate them to provide deep insights into system behavior. Correlation engines identify relationships between different components, allowing operators to understand how issues in one part of the system affect others.
Distributed tracing becomes essential in microservices architectures, where a single user request may pass through dozens of services. Observability systems reconstruct these request paths to identify latency bottlenecks and failure points.
Advanced systems also incorporate anomaly detection algorithms that identify unusual patterns without predefined thresholds. This allows for early detection of issues that might not be visible through traditional monitoring approaches.
Cloud Security at Scale and Zero Trust Architecture
Security at enterprise scale is based on the Zero Trust model, which assumes that no system, user, or network segment is inherently trustworthy. Every access request must be verified, authenticated, and authorized regardless of its origin.
Zero Trust architecture enforces strict identity verification for all interactions within the system. This includes machine-to-machine communication, not just user access. Every request is evaluated based on identity, context, and policy before being allowed.
Security is also enforced through continuous verification processes that monitor system behavior in real time. Any deviation from expected behavior triggers automated responses such as access revocation or workload isolation.
Encryption is applied universally across all data flows, and secrets management systems ensure that sensitive credentials are never exposed in plaintext form. Security operations are deeply integrated into CloudOps workflows, making security an inherent part of system design rather than an external layer.
Performance Engineering and System Optimization at Scale
Performance engineering in CloudOps focuses on ensuring that systems operate efficiently under varying loads and conditions. At enterprise scale, even small inefficiencies can lead to significant performance degradation or cost increases.
Systems are continuously analyzed for latency, throughput, and resource utilization. Bottlenecks are identified through distributed tracing and performance profiling tools. Optimization strategies include caching, load balancing adjustments, query optimization, and resource reallocation.
Performance tuning is not a one-time activity but an ongoing process driven by real-time data. Automated systems often adjust configurations dynamically to maintain optimal performance levels. This ensures that applications remain responsive even under heavy or unpredictable workloads.
Disaster Recovery and Business Continuity Planning
Disaster recovery is a critical component of enterprise CloudOps. Systems must be designed to withstand failures at multiple levels, including hardware failures, regional outages, and network disruptions.
Business continuity strategies involve maintaining redundant systems across multiple regions so that workloads can be shifted seamlessly in case of failure. Data replication ensures that critical information is not lost, while automated failover mechanisms redirect traffic to healthy environments.
Recovery time objectives and recovery point objectives are defined to measure how quickly systems can be restored and how much data loss is acceptable. CloudOps automation ensures that recovery processes are executed quickly and consistently without manual intervention.
DevOps and CloudOps Integration in Modern Workflows
CloudOps and DevOps are closely interconnected, with CloudOps focusing on operational stability and DevOps focusing on continuous delivery and development velocity. In modern environments, these two disciplines work together to create seamless software delivery pipelines.
Continuous integration and continuous deployment systems are tightly integrated with CloudOps automation frameworks. This ensures that code changes are automatically tested, validated, and deployed into production environments with minimal friction.
Operational feedback is also fed back into development pipelines, allowing developers to improve application performance and reliability based on real-world system data. This creates a continuous feedback loop between development and operations teams.
Future Direction of CloudOps and Autonomous Infrastructure
The future of CloudOps is moving toward fully autonomous infrastructure systems that require minimal human intervention. These systems will be capable of self-managing, self-healing, and self-optimizing based on real-time data and predictive analytics.
Artificial intelligence and machine learning will play a significant role in future operational models, enabling systems to make intelligent decisions about scaling, security, and performance optimization. Infrastructure will become increasingly adaptive, responding dynamically to changing conditions without manual configuration.
As this evolution continues, CloudOps will shift from being a human-managed discipline to a partially autonomous ecosystem where humans focus primarily on strategy, architecture, and governance rather than day-to-day operations.
Conclusion
The evolution from SysOps to CloudOps represents far more than a certification update or a change in terminology. It reflects a structural transformation in how modern digital infrastructure is designed, operated, and continuously improved. Traditional system operations were rooted in physical infrastructure management, where administrators were responsible for maintaining servers, ensuring uptime, applying patches, and manually responding to system failures. This model worked effectively in environments where change was slow, predictable, and constrained within well-defined hardware boundaries. However, the rise of cloud computing fundamentally disrupted this operational model by introducing elasticity, abstraction, and global-scale distribution as standard features rather than optional enhancements. It also introduced a new expectation of speed, where systems must evolve continuously without downtime, forcing organizations to rethink not only their tools but also their operational philosophy.
In cloud environments, infrastructure is no longer a fixed asset but a dynamic, programmable resource. Systems scale automatically, services are distributed across multiple regions, and workloads fluctuate continuously based on user demand. This shift makes manual operational practices insufficient for modern requirements. CloudOps emerges as the operational discipline designed specifically for this environment, where automation, observability, and governance are not optional add-ons but core components of system design. It redefines operations as a continuous, data-driven process rather than a reactive support function. The emphasis is no longer on maintaining stability through control, but on enabling adaptability through intelligent system design and automated responses.
One of the most important outcomes of this shift is the increasing reliance on automation as a foundational principle. Automation is no longer limited to simple scripting tasks but extends into full lifecycle management of infrastructure and applications. From provisioning and deployment to scaling, monitoring, and recovery, automated systems now handle tasks that previously required significant human intervention. This reduces operational overhead while increasing consistency, reliability, and speed of execution. Infrastructure as code plays a central role in this transformation by enabling environments to be defined, versioned, and reproduced programmatically. This ensures that systems remain consistent across development, testing, and production stages, reducing configuration drift and minimizing human error. Over time, this also enables organizations to adopt repeatable patterns and standardized architectures that improve efficiency at scale.
Another critical dimension of CloudOps is observability, which has become essential in managing distributed systems. Unlike traditional monitoring, which focuses on predefined metrics and alerts, observability provides a deeper understanding of system behavior through logs, metrics, and traces. This allows operations teams to analyze not just what is happening within a system, but why it is happening. In complex microservices-based architectures, where a single request may pass through multiple services, observability becomes essential for identifying bottlenecks, diagnosing failures, and improving system performance. This level of insight enables proactive operations, where issues are identified and resolved before they escalate into critical failures. It also supports continuous optimization, allowing teams to refine system performance based on real-world usage patterns rather than assumptions.
Security also undergoes a major transformation in the CloudOps model. Traditional perimeter-based security approaches are no longer sufficient in environments where resources are distributed globally and accessed dynamically. Instead, security becomes identity-centric and policy-driven. Access is granted based on roles, permissions, and contextual rules rather than static network boundaries. Continuous verification, encryption, and automated compliance checks ensure that systems remain secure throughout their lifecycle. Security is no longer treated as a separate domain but is deeply integrated into operational workflows, making it an inherent part of system design and management. This integration ensures that security scales alongside infrastructure, rather than becoming a bottleneck or afterthought.
From an organizational perspective, the shift to CloudOps changes the structure and responsibilities of IT teams. Operational roles are no longer limited to maintaining infrastructure but now involve designing automation pipelines, optimizing cloud resources, managing distributed systems, and ensuring service reliability at scale. Professionals are expected to understand cloud architecture, scripting, infrastructure automation, and performance engineering. The focus moves from reactive problem-solving to proactive system optimization, where the goal is to continuously improve efficiency, scalability, and resilience. This also encourages a culture of shared responsibility, where teams collaborate more closely and align around common performance and reliability goals.
This transformation also has a direct impact on how organizations approach cost management. In cloud environments, resources are consumed on a usage-based model, meaning inefficiencies can quickly translate into unnecessary expenses. CloudOps introduces cost optimization as an operational discipline, where systems are continuously analyzed to identify underutilized resources, optimize workloads, and improve efficiency. Automated scaling, resource scheduling, and intelligent workload distribution help ensure that infrastructure is used effectively without compromising performance. Over time, this leads to more predictable spending patterns and better alignment between technical decisions and business objectives.
At an enterprise level, CloudOps becomes even more critical due to the complexity of managing large-scale, distributed systems across multiple regions and sometimes multiple cloud providers. Governance frameworks are introduced to enforce consistency, compliance, and control across all environments. These frameworks ensure that infrastructure changes adhere to predefined policies and regulatory requirements. Automation is used not only for deployment and scaling but also for enforcing governance rules, ensuring that systems remain compliant and secure without manual oversight. This level of control is essential for maintaining trust, especially in industries with strict regulatory standards.
Another important aspect of CloudOps is its integration with modern software delivery practices. Development and operations are no longer separate silos but interconnected functions that work together to deliver applications continuously. Continuous integration and continuous deployment pipelines are tightly coupled with operational automation systems, allowing code changes to move from development to production rapidly and reliably. Operational feedback loops also feed directly into development processes, enabling teams to improve application performance based on real-world system behavior. This creates a continuous cycle of improvement where both development and operations contribute to system excellence.
Looking forward, the trajectory of CloudOps is moving toward increasingly autonomous systems. Artificial intelligence and machine learning are being integrated into operational workflows to enable predictive scaling, intelligent incident detection, and automated remediation. Instead of reacting to system changes, future cloud environments will anticipate them and adjust proactively. This represents a shift toward self-healing and self-optimizing infrastructure, where human intervention is required primarily for strategic decision-making rather than day-to-day operations. These advancements will further reduce operational complexity while increasing system reliability and efficiency.
In this evolving landscape, the distinction between SysOps and CloudOps becomes more than just historical terminology. It represents a fundamental change in how technology infrastructure is understood and managed. SysOps belongs to an era of static systems and manual control, while CloudOps defines a future of dynamic, automated, and intelligent environments. For IT professionals and organizations alike, adapting to this shift is not optional but necessary for long-term relevance and competitiveness. Those who embrace this transformation gain the ability to innovate faster, scale more efficiently, and respond to challenges with greater agility.
Ultimately, CloudOps is not just an operational framework but a mindset shift. It emphasizes adaptability, automation, and continuous improvement as core principles of modern IT systems. As cloud technologies continue to evolve, the role of CloudOps will expand further, shaping how digital systems are built, maintained, and optimized in the years ahead. It sets the foundation for a future where infrastructure is not only managed but intelligently orchestrated, enabling organizations to operate with unprecedented speed, efficiency, and resilience in an increasingly digital world.