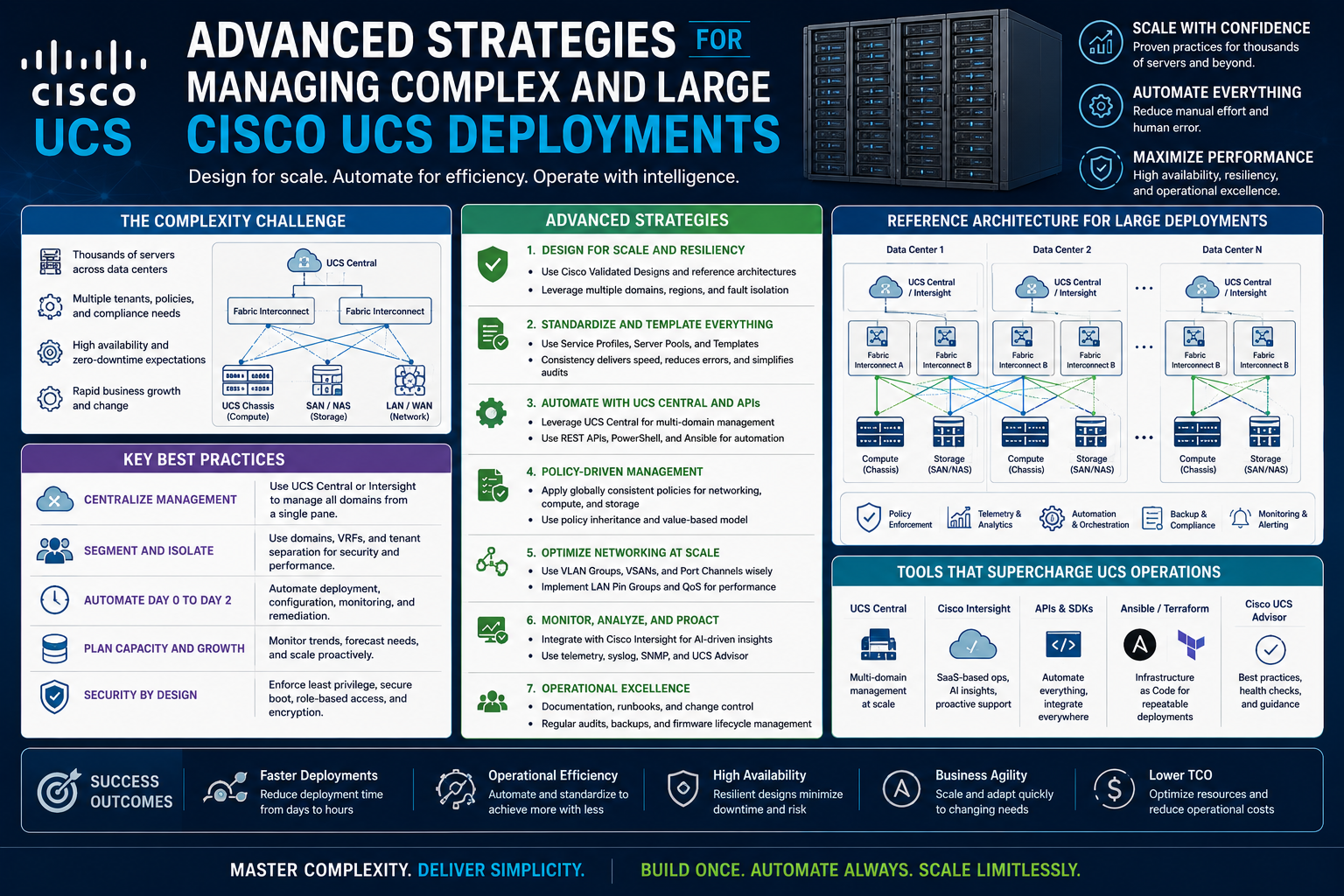
Managing a large Cisco Unified Computing System environment requires a structured approach, especially when dealing with hundreds of blade and rack servers across multiple domains. In environments that exceed 250 servers, complexity increases due to the number of configuration options, interdependencies between compute, network, and storage, and the operational demands of maintaining consistency. Cisco UCS is designed to unify these components into a single architecture, but effective management still depends heavily on disciplined administration practices, standardization, and automation.
Overview of Cisco UCS Architecture
Cisco Unified Computing System is an integrated infrastructure platform that combines compute, networking, and storage connectivity into a cohesive system. At its core, UCS uses a pair of Fabric Interconnects that act as the central management and communication layer for all connected resources. These interconnects connect to blade chassis and rack servers, enabling centralized control and reducing the need for traditional point-to-point server cabling.
Blade servers reside in chassis that share power, cooling, and network connectivity through internal modules. Rack servers connect directly to the Fabric Interconnects. This architecture reduces physical complexity while increasing scalability. The system is designed to support both Ethernet and Fibre Channel connectivity, allowing organizations to integrate with existing data center infrastructure.
Understanding the UCS Domain Concept
A UCS domain is the fundamental management boundary within the system. It consists of a pair of Fabric Interconnects and the compute resources attached to them, including blade chassis and rack servers. All configuration, monitoring, and management tasks for the domain are performed through a centralized interface.
Although a single domain can support a large number of servers, there are practical limits based on design and performance considerations. As environments grow, administrators must consider how many servers, chassis, and workloads can be efficiently managed within a single domain. The goal is not only to fit within system limits but also to maintain operational simplicity and reduce risk during maintenance activities.
Centralized Management Through UCS Manager
Cisco UCS Manager provides a web-based interface for managing an entire domain. It operates through a virtual IP address that floats between the paired Fabric Interconnects to ensure high availability. This interface allows administrators to configure hardware, define policies, and monitor system health from a single point.
One of the most powerful aspects of UCS Manager is its policy-driven architecture. Instead of configuring each server individually, administrators define reusable policies for networking, storage access, firmware versions, and boot behavior. These policies are grouped into service profiles, which define the identity and configuration of each server.
Service profiles allow hardware to become stateless. This means a server can be replaced or reassigned without manual reconfiguration. Once a new blade is inserted into the chassis, the assigned service profile automatically applies the correct settings, ensuring consistency across the environment.
Using Pools and Service Profiles for Efficiency
In large environments, resource pools are essential for scalability. Pools can include MAC addresses, WWPN identifiers for storage, and IP addresses. These pools ensure that resources are allocated consistently without duplication or manual tracking.
Service profile templates further streamline operations. Instead of creating individual profiles from scratch, administrators build a template that defines standard configurations. New service profiles are then generated from this template, ensuring uniformity across all servers. Any updates to the template can propagate to linked profiles, reducing configuration drift and administrative overhead.
This approach is especially useful in environments where many servers perform identical roles. It eliminates repetitive configuration tasks and reduces the likelihood of human error during deployment.
Managing Blade and Rack Server Environments
Large UCS environments often include a mix of blade and rack servers. Blade servers are housed in chassis that provide shared infrastructure, while rack servers operate independently but still integrate into the same management framework.
Understanding hardware placement, chassis organization, and server identity is important for troubleshooting and capacity planning. Even when administrators do not physically interact with hardware, having visibility into rack locations, chassis slots, and server identifiers helps during maintenance and incident response.
In environments with hundreds of servers, maintaining accurate inventory records becomes essential. Many organizations integrate UCS data with configuration management systems to ensure hardware information remains consistent across operational tools.
Scaling Considerations in Large Deployments
As UCS environments grow, scaling becomes a key architectural concern. While a single domain can support a significant number of servers, larger organizations often distribute workloads across multiple domains. This approach improves resilience and reduces the impact of maintenance activities.
Firmware upgrades are one of the primary reasons for splitting environments into multiple domains. Since upgrades often require sequential restarts of system components, limiting the number of servers affected at one time reduces operational risk. In multi-domain designs, workloads can be migrated between domains during maintenance, allowing systems to remain available.
Virtualized environments benefit particularly from this model. When workloads run on virtualization platforms, compute resources can be shifted dynamically, enabling administrators to evacuate an entire domain without service interruption. This level of flexibility is critical in enterprise environments with strict uptime requirements.
Managing Multiple UCS Domains
While each UCS domain operates independently, managing multiple domains introduces additional complexity. Administrators must log into each domain separately when using native management tools, which can become inefficient at scale.
To address this, centralized management platforms have been developed. These tools provide visibility across multiple domains and help standardize configuration policies. Although they do not replace domain-level management, they serve as an aggregation layer for monitoring and coordination.
Cloud-based management platforms have also become increasingly relevant. They provide unified dashboards, lifecycle management capabilities, and integration with broader infrastructure ecosystems. This allows administrators to manage distributed environments without relying solely on local interfaces.
Automation and Scripting in UCS Management
Automation plays a critical role in managing large UCS environments. Scripting tools allow administrators to retrieve configuration data, apply changes, and correlate information across systems.
PowerShell-based modules designed for UCS environments enable interaction with management APIs. These tools can query hardware status, extract configuration details, and automate repetitive tasks. When combined with virtualization management tools, they provide a powerful way to correlate physical infrastructure with virtual workloads.
In large deployments, automation scripts are often used to generate inventory reports that combine data from multiple sources. This includes server identity, hardware configuration, virtualization host mapping, and network configuration. Exporting this data into structured formats allows for easier analysis and troubleshooting.
Operational Challenges in Large Environments
As environments scale, operational challenges become more pronounced. Configuration consistency, firmware management, and hardware tracking all require strict control mechanisms. Without standardized processes, environments can quickly become difficult to manage.
Another challenge is coordinating maintenance activities. Reboots, firmware upgrades, and hardware replacements must be carefully scheduled to avoid disrupting workloads. In environments with multiple domains, planning becomes even more important, as changes in one domain may require workload migration strategies across others.
Monitoring also becomes more complex. Large environments generate significant telemetry data, and administrators must ensure that monitoring tools are properly configured to detect anomalies without overwhelming operational teams with alerts.
Role of Infrastructure Design in Stability
Proper design is essential for maintaining stability in large UCS environments. Redundancy in Fabric Interconnects, network paths, and storage connections ensures that no single component becomes a point of failure.
Logical separation of workloads across chassis and domains also improves resilience. By distributing critical workloads, organizations reduce the risk of simultaneous failure. This design philosophy is particularly important in mission-critical environments where downtime has significant consequences.
Planning for growth is another key consideration. As new servers are added, administrators must ensure that resource pools, network configurations, and storage mappings are expanded accordingly. Failure to plan for scale can result in resource exhaustion or configuration conflicts.
Conclusion
Managing a large Cisco UCS environment requires more than technical knowledge of individual components. It demands a structured approach that combines centralized management, policy-based configuration, automation, and thoughtful architectural design. As environments grow beyond a few hundred servers, challenges shift from simple configuration tasks to broader operational concerns such as scalability, consistency, and lifecycle management. By leveraging service profiles, resource pools, multi-domain strategies, and automation tools, administrators can maintain control over complex infrastructures while ensuring reliability and operational efficiency.