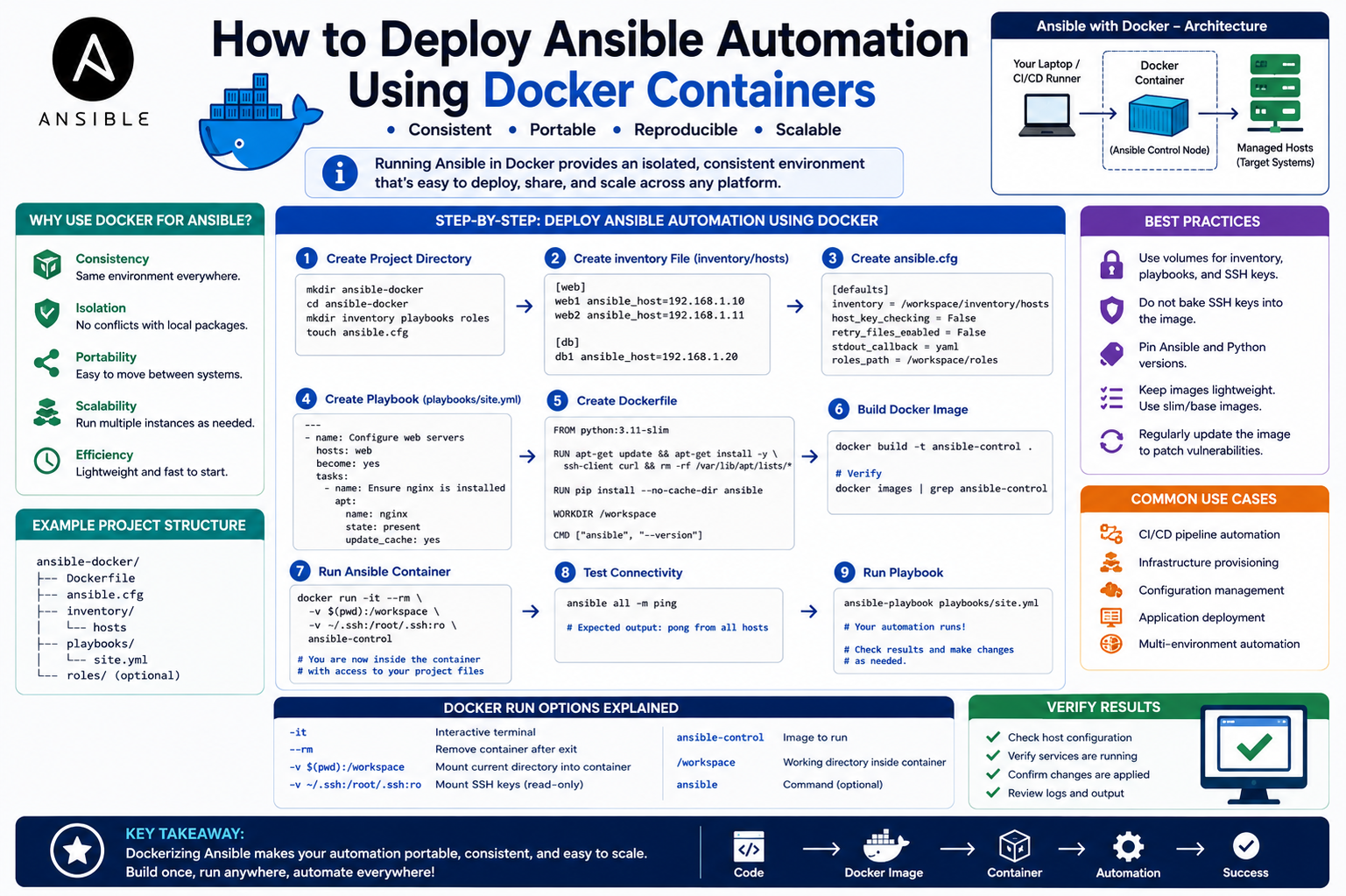
Container-based automation has become a practical way to standardize how infrastructure automation is executed across different environments. By combining a configuration management tool with container technology, teams can ensure consistency, portability, and isolation of automation workflows. In this approach, a full automation project is packaged into a container image and executed as a self-contained unit. This method removes dependency issues that often arise when running automation directly on host machines and provides a repeatable execution environment. The following sections explain how an automation project can be structured, packaged into a container image, and executed using container runtime behavior to manage infrastructure tasks efficiently.
Understanding the Automation Project Structure
An automation project designed for container execution typically follows a structured layout that separates configuration, inventory, variables, and reusable automation logic. At the core of the project is a main orchestration file that defines which groups of systems should be targeted and which roles should be applied. Roles represent modular automation units that encapsulate a specific configuration or operational task. This modular approach allows reuse of automation logic across multiple environments and simplifies maintenance. In a typical setup, a single role may handle a configuration task such as system logging, network parameter configuration, or service management. The orchestration file then references these roles and ensures they are executed in the correct order against the defined infrastructure targets.
Dependency Management in the Automation Environment
Automation projects often rely on external Python packages and collection libraries to extend functionality. These dependencies are usually defined in a dedicated file that lists required Python modules and their versions. This ensures that the automation behaves consistently regardless of where it is executed. Alongside Python dependencies, automation tools may also require additional collections that provide prebuilt modules for interacting with specific systems or platforms. These collections are defined separately and installed before execution. This separation of dependencies ensures clarity between runtime libraries and automation-specific extensions, allowing the environment to be rebuilt reliably whenever needed.
Inventory and Configuration Handling
Infrastructure targets are defined through an inventory structure that organizes systems into logical groups. Each group may represent a category such as network devices, servers, or application nodes. Individual systems are defined within these groups and can have associated connection parameters such as IP addresses, authentication details, and protocol-specific settings. This structure allows automation to scale efficiently across large environments without manually defining each execution target.
Configuration settings for the automation tool itself are stored in a central configuration file. This file controls behavior such as host verification rules, connection handling, and execution defaults. In many automated environments, host verification is disabled to allow seamless connections, especially in dynamic or lab-based systems. While this simplifies execution, it is typically used in controlled environments where trust boundaries are already defined.
Variable Organization and Scope
Automation projects use variable files to manage dynamic values applied to different levels of infrastructure. These variables are often separated into group-level and host-level definitions. Group-level variables apply to all systems within a category, while host-level variables apply only to a specific system. This layered approach allows administrators to define shared configurations while still maintaining system-specific customization. For example, authentication credentials or connection methods may be shared across a group, while individual system addresses or transport parameters may vary per host. This structure ensures flexibility while keeping configuration organized and scalable.
Role-Based Automation Design
Roles are the foundation of reusable automation logic. Each role contains a defined set of tasks that accomplish a specific objective. These tasks are executed in sequence and can include configuration changes, validation steps, or system updates. By encapsulating logic within roles, automation becomes modular and easier to manage across different projects. A role typically contains a main execution file that defines the task sequence. In this scenario, a role might focus on configuring system logging parameters on network devices, ensuring consistent operational logging across all targeted systems. This modular structure allows roles to be reused across multiple automation workflows without modification.
Containerizing the Automation Environment
To ensure portability and consistency, the entire automation project is packaged into a container image. A container image defines the runtime environment, dependencies, and execution instructions required to run the automation. This is achieved through a build definition file that describes how the environment should be assembled. The process begins with a base runtime environment that includes a programming language interpreter. From there, system packages and automation dependencies are installed to prepare the environment for execution.
The build process also includes installing necessary system utilities required for secure connections and communication with managed systems. After system dependencies are installed, Python packages and automation libraries are added to the environment. This ensures that all required modules are available at runtime without relying on external installations. Once the core dependencies are in place, automation collections are installed to extend functionality for specific infrastructure platforms.
Incorporating Project Files into the Container
After setting up dependencies, the automation project files are copied into the container environment. This includes the inventory structure, variable definitions, configuration settings, roles, and the main orchestration file. Each component is placed in a standardized location within the container so that the automation tool can locate and execute them without additional configuration. This structured placement ensures that the container behaves like a fully configured automation environment immediately upon startup.
The orchestration file acts as the entry point for execution. It defines which systems will be targeted and which roles will be executed. When the container starts, this file is automatically triggered, initiating the automation workflow without requiring manual intervention. This design enables fully automated execution from container startup to completion of tasks.
Executing the Container Build Process
Once the build definition is complete, the container image is created using a build command that reads the instructions and assembles the environment step by step. During this process, each instruction is executed sequentially, and intermediate layers are created to optimize reuse and caching. This layered approach allows future builds to reuse unchanged components, significantly reducing build time when only small modifications are made to the automation project.
After the build process completes successfully, the resulting image is stored locally and can be verified using standard image inspection commands. The image contains everything required to run the automation, including dependencies, configuration files, and execution logic. This ensures that the environment is fully portable and can be executed on any system that supports container runtime execution.
Running the Automation Container
Execution begins by launching a container instance from the previously built image. When the container starts, it automatically triggers the orchestration process defined in the main automation file. The automation tool then connects to the defined infrastructure targets using the parameters specified in the inventory and variable files. Once connectivity is established, the defined roles are executed in sequence.
During execution, each task within a role is processed and applied to the targeted systems. The automation engine gathers system information, applies configuration changes, and validates the results. Output is displayed in real time, showing the status of each task and whether changes were applied successfully. If a system is already in the desired state, the automation tool recognizes this and avoids unnecessary modifications, ensuring idempotent behavior.
Observing Execution Results and Behavior
After execution completes, a summary is generated showing the status of each targeted system. This includes whether tasks succeeded, whether changes were made, and whether any errors occurred. In a successful run, the output indicates that all systems reached the desired configuration state without failures. This provides confidence that the automation logic is functioning correctly and that the containerized environment is executing as intended.
The use of containers also ensures that execution behavior remains consistent across different systems. Since the environment is fully encapsulated, there are no external dependencies that could alter execution results. This makes troubleshooting easier and improves reliability when deploying automation at scale.
Conclusion
Packaging automation workflows into container environments provides a reliable and repeatable method for executing infrastructure tasks. By combining structured project design, dependency management, modular roles, and containerization, automation becomes portable and consistent across different environments. This approach reduces configuration drift, simplifies deployment, and ensures that automation behaves the same way regardless of where it is executed. The result is a streamlined execution model where complex automation workflows can be packaged, transported, and run with minimal operational overhead, improving efficiency in managing modern infrastructure systems.