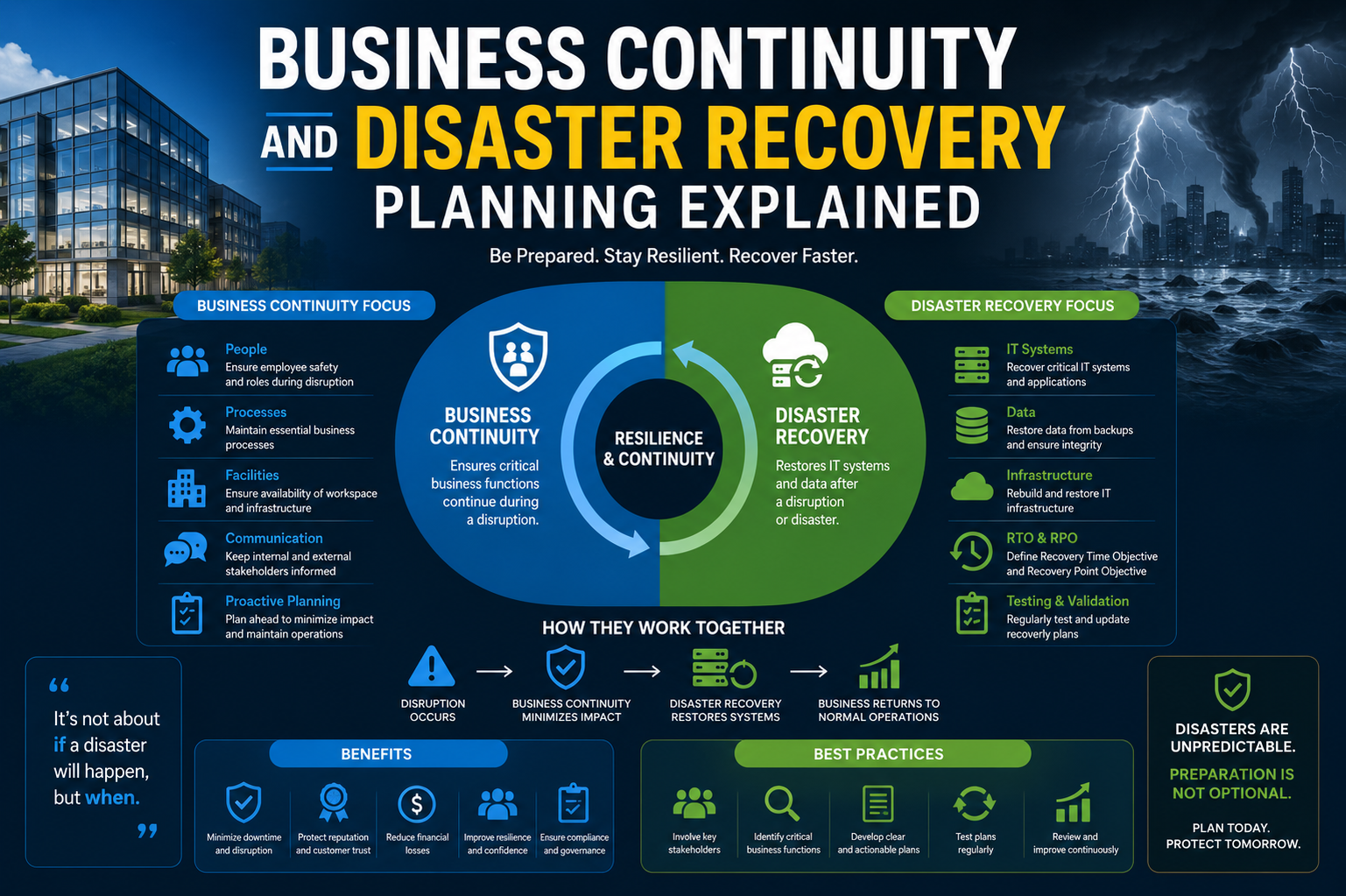
Business Continuity and Disaster Recovery (BC/DR) Planning refers to a structured approach that organizations use to ensure critical systems, services, and operations can continue or be quickly restored when unexpected disruptions occur. These disruptions may include system failures, cyber incidents, power outages, hardware damage, or large-scale operational breakdowns. The main idea behind BC/DR planning is not just to react to problems but to prepare in advance so that recovery is fast, controlled, and predictable. Instead of improvising during a crisis, organizations rely on clearly defined procedures that guide technical teams and decision-makers step by step.
In a modern IT environment, almost every business function depends on technology. From communication systems to databases and customer-facing platforms, even a short interruption can affect productivity, revenue, and trust. BC/DR planning ensures that when such interruptions happen, there is a structured way to minimize downtime and reduce damage. It is not a single document but a combination of policies, procedures, recovery strategies, and responsibilities designed to keep operations stable under pressure.
Importance of Prepared Recovery in IT Environments
In an IT-driven organization, service disruptions can escalate quickly if there is no predefined response plan. Systems may fail due to technical issues, external attacks, or unexpected environmental conditions. Without a BC/DR strategy, teams often waste critical time deciding what to do, which increases downtime and business impact. A well-prepared recovery approach ensures that actions are already defined before an incident occurs, allowing technical staff to focus on execution instead of decision-making during emergencies.
This preparation is similar to emergency response systems in other industries, where responders follow established procedures instead of improvising under stress. In IT operations, the same principle applies: structured recovery instructions help teams restore systems efficiently while reducing confusion. The goal is to ensure that essential services return to normal operation within acceptable time limits while protecting data integrity and minimizing losses.
Assigning Ownership in BC/DR Planning
One of the foundational steps in BC/DR planning is assigning clear ownership. This means identifying individuals or roles responsible for leading the entire planning process and making final decisions during disruptions. Without defined ownership, responsibility becomes unclear, which can delay recovery actions and create confusion during critical situations.
Ownership ensures accountability, meaning that someone is always responsible for maintaining the plan, updating procedures, and coordinating responses during incidents. This role often involves collaboration across different departments, as BC/DR planning is not limited to IT alone. Business leaders, system administrators, and operational managers all contribute, but a designated owner ensures that all efforts remain aligned and organized.
Clear ownership also improves consistency. When a single authority oversees the process, decisions are made more efficiently, and conflicting instructions are avoided. This structure helps maintain discipline in emergency scenarios where time and accuracy are essential.
Establishing BC/DR Policies for Structure and Control
BC/DR policies define the rules and boundaries of the entire planning framework. These policies explain why the BC/DR plan exists, what systems and processes it covers, and who has the authority to make decisions during disruptions. They serve as a governance layer that keeps the planning process structured and prevents unnecessary expansion or confusion.
Without clear policies, recovery planning can become inconsistent, with different teams applying different approaches. Policies ensure that all stakeholders follow the same direction, especially during high-pressure situations. They also define the scope of recovery efforts, clarifying which systems are critical and which can tolerate delays.
In addition, BC/DR policies help align technical recovery strategies with business objectives. This ensures that recovery efforts focus on what matters most to the organization rather than treating all systems equally. By establishing rules early, organizations reduce ambiguity and improve coordination during actual incidents.
Understanding Business Impact Analysis in BC/DR
Business Impact Analysis (BIA) is a key step that helps organizations understand how different processes affect overall operations. It involves identifying all critical business functions and evaluating how their failure would impact productivity, revenue, customer service, and compliance. The goal is to prioritize systems based on their importance to business continuity.
During this analysis, each process is reviewed to determine its role within the organization. Some systems may be essential for daily operations, while others may support secondary functions. By ranking these processes, organizations can focus recovery efforts on the most critical areas first.
BIA also helps in understanding dependencies between systems. For example, if one system fails, it may affect several others. Recognizing these relationships allows better planning and ensures that recovery strategies address root dependencies rather than isolated components. This structured understanding is essential for building effective recovery priorities.
Evaluating Risk Through Critical Analysis
Critical analysis in BC/DR planning involves assessing the risks associated with each business process. Once processes are identified through Business Impact Analysis, they are evaluated based on two key factors: the likelihood of failure and the potential impact of that failure.
Each process is assigned a risk level that reflects how vulnerable it is to disruption. Systems that are more likely to fail or cause significant damage when they fail receive higher priority. This scoring approach helps organizations make informed decisions about where to allocate resources for protection and recovery planning.
The combination of likelihood and impact creates a clear risk profile for each system. This structured evaluation allows decision-makers to prioritize recovery planning efforts based on objective data rather than assumptions. It ensures that the most critical risks are addressed first, improving overall resilience.
Connecting Risk Scores to Recovery Priorities
Once risk levels are determined, they are used to define recovery priorities. Systems with higher risk scores require more detailed recovery plans, faster restoration targets, and greater resource allocation. Lower-risk systems may have more flexible recovery timelines.
This prioritization is essential because organizations typically cannot allocate unlimited resources to every system. Time, budget, and technical capacity are always limited, so focusing on the most critical systems ensures efficient use of available resources.
By linking risk analysis directly to recovery planning, BC/DR frameworks create a structured decision-making process. This ensures that recovery efforts are not random but guided by clearly defined business priorities and measurable risk assessments.
Establishing BC/DR Recovery Goals, Strategies, and Plans
Once an organization understands which business processes are most critical and how they are affected by potential disruptions, the next stage of Business Continuity and Disaster Recovery (BC/DR) planning focuses on defining recovery goals, strategies, and detailed response plans. This stage transforms analysis into action by outlining how systems will be restored, in what order, and under what conditions. It bridges the gap between identifying risks and actually preparing structured responses that can be executed during real incidents.
At this stage, organizations begin translating business priorities into technical recovery requirements. This means deciding what must be restored first, what can wait, and what level of service is acceptable during recovery. These decisions ensure that technical teams are not guessing during outages but instead following a predefined roadmap designed to restore operations in the most efficient way possible.
Defining Maximum Tolerable Downtime and Outage Limits
A critical part of building recovery strategies involves defining acceptable limits for downtime and outages. Maximum tolerable downtime refers to how long a business function or system can remain unavailable before it causes unacceptable damage. This threshold varies depending on the importance of the system and its role in daily operations.
Closely related is the concept of maximum tolerable outage, which focuses on how long the entire business can continue operating under a specific disruption scenario. While downtime focuses on individual systems, outage tolerance considers broader business survival under failure conditions. These two measurements help organizations understand urgency levels and set realistic recovery expectations.
By establishing these limits, organizations create clear boundaries that guide recovery planning. Systems with very low tolerance for downtime require faster recovery methods and more robust infrastructure, while systems with higher tolerance may rely on simpler, slower restoration approaches.
RTO=Maximum acceptable time a service can be down before recovery must be completedRTO = \text{Maximum acceptable time a service can be down before recovery must be completed}RTO=Maximum acceptable time a service can be down before recovery must be completed
How Recovery Objectives Shape Business Priorities
Recovery objectives play a central role in shaping how organizations allocate time, money, and technical resources. When systems are categorized based on how quickly they must be restored, businesses can prioritize investments accordingly. Systems that require near-immediate recovery often demand advanced redundancy, backup infrastructure, and rapid failover mechanisms.
On the other hand, systems that can tolerate longer downtime may rely on traditional backup and restore methods, which are slower but more cost-effective. This balance between speed and cost is a key consideration in BC/DR planning, as organizations rarely have unlimited resources to protect every system equally.
These recovery objectives also help organizations make informed decisions during system design. Critical systems are often built with higher resilience in mind, while less critical systems may be designed with simpler architectures to reduce cost and complexity.
RPO=Maximum acceptable data loss measured in time between backupsRPO = \text{Maximum acceptable data loss measured in time between backups}RPO=Maximum acceptable data loss measured in time between backups
Designing BC/DR Recovery Strategies
Recovery strategies define the technical and operational methods used to restore systems after a disruption. These strategies vary depending on system importance, available resources, and acceptable recovery timeframes. They may include backup restoration, system replication, cloud failover, or alternate infrastructure usage.
The choice of strategy is directly influenced by recovery objectives. Systems requiring fast restoration often use real-time replication or high-availability setups, while less critical systems may rely on scheduled backups. The goal is to ensure that each system has a recovery method that matches its importance and risk level.
Recovery strategies also consider scalability and flexibility. As organizations grow, systems may become more complex, requiring more advanced recovery approaches. Therefore, strategies must be adaptable and regularly updated to reflect changes in infrastructure and business needs.
Building Structured Recovery Plans
Once strategies are defined, they are documented into structured recovery plans. These plans act as step-by-step instructions for restoring services during disruptions. They include detailed procedures for system restoration, data recovery, communication, and validation of services after recovery.
A well-structured recovery plan ensures that technical teams can act quickly without confusion. It removes uncertainty by providing clear instructions on what actions to take, in what order, and using which resources. This level of structure is especially important during high-pressure situations where delays can significantly increase business impact.
Recovery plans also define roles and responsibilities during incidents. This ensures that every team member understands their specific duties, reducing overlap and improving coordination during recovery efforts.
Balancing Budget and Recovery Requirements
One of the most important realities in BC/DR planning is that recovery solutions must align with budget constraints. Organizations cannot invest unlimited resources into protecting every system equally, so trade-offs must be made between cost and recovery speed.
Systems that require extremely fast recovery typically demand higher investment in infrastructure, redundancy, and monitoring. These systems are often business-critical and justify the cost due to their importance. In contrast, less critical systems may use slower, more affordable recovery methods that still ensure eventual restoration but with longer downtime.
This balance ensures that organizations maintain financial efficiency while still achieving acceptable levels of resilience. BC/DR planning helps decision-makers allocate resources intelligently based on risk, impact, and recovery requirements.
Maintaining and Testing Recovery Strategies
Once recovery plans and strategies are established, they must be continuously tested and maintained. Testing ensures that recovery procedures actually work when needed and that teams are familiar with the steps involved. Without regular testing, even well-designed plans can fail during real incidents.
Maintenance is equally important because IT environments constantly evolve. Systems are upgraded, replaced, or reconfigured, which can make existing recovery plans outdated. Regular updates ensure that plans remain accurate and aligned with current infrastructure.
Testing and maintenance are ongoing processes rather than one-time tasks. They ensure that BC/DR plans remain reliable, practical, and effective in real-world conditions.
Continuous Improvement of BC/DR Plans
Business Continuity and Disaster Recovery (BC/DR) planning does not end once recovery strategies and procedures are documented. In reality, it is an ongoing process that must evolve alongside changes in technology, infrastructure, and business operations. Continuous improvement ensures that recovery plans remain relevant, effective, and capable of handling new types of risks as they emerge. Without regular refinement, even well-designed BC/DR frameworks can become outdated and unreliable over time.
Organizations improve BC/DR plans by reviewing past incidents, analyzing test results, and updating procedures based on lessons learned. This cycle of evaluation and adjustment strengthens resilience and ensures that recovery processes reflect current operational realities. Continuous improvement also helps identify gaps in existing plans, allowing organizations to address weaknesses before they lead to real-world failures.
Importance of Regular Testing in BC/DR Planning
Testing is one of the most critical components of maintaining an effective BC/DR strategy. It validates whether recovery procedures actually work under simulated conditions and whether teams can execute them correctly during emergencies. Without testing, organizations may assume their plans are effective, only to discover failures during real incidents when it is too late to correct them.
Different types of testing can be performed depending on the level of risk and system criticality. Some tests focus on individual components, while others simulate full-scale disaster scenarios to evaluate end-to-end recovery performance. These exercises help identify technical issues, procedural gaps, and communication breakdowns that may not be visible during normal operations.
Testing also improves team readiness. When staff regularly practice recovery procedures, they become more confident and efficient during real disruptions. This reduces response time and minimizes confusion, which is essential when systems must be restored quickly.
Maintaining BC/DR Documentation and Accuracy
BC/DR documentation must remain accurate and up to date to be effective. As systems evolve, infrastructure changes, and new technologies are introduced, recovery procedures must be revised to reflect these updates. Outdated documentation can lead to incorrect recovery steps, delays, or even complete failure during an incident.
Maintenance involves regularly reviewing all BC/DR materials, including recovery procedures, system dependencies, contact lists, and escalation paths. These updates ensure that every component of the plan aligns with the current IT environment. Even small changes in infrastructure can have significant effects on recovery processes, making regular reviews essential.
Accurate documentation also supports consistency across teams. When everyone follows the same updated instructions, recovery efforts become more coordinated and efficient, reducing the risk of miscommunication during critical events.
Role of Communication in Disaster Recovery
Effective communication is a key factor in successful disaster recovery operations. During an incident, multiple teams often work simultaneously on different aspects of recovery. Clear communication ensures that everyone understands the situation, their responsibilities, and the current status of recovery efforts.
BC/DR plans typically include predefined communication protocols that outline how information should be shared, who should be informed, and what escalation procedures must be followed. These protocols help maintain order during high-pressure situations and prevent misinformation or delays in decision-making.
Communication is not limited to technical teams. It also extends to management, stakeholders, and sometimes customers, depending on the severity of the disruption. Keeping all relevant parties informed helps maintain trust and ensures transparency during recovery operations.
Coordination Between Teams During Recovery
Disaster recovery often involves multiple teams working together, including IT operations, security, network management, and business units. Effective coordination between these groups is essential to ensure that recovery efforts are aligned and efficient. Without coordination, teams may duplicate efforts, overlook critical tasks, or work toward conflicting objectives.
BC/DR planning establishes clear roles and responsibilities to prevent confusion during incidents. Each team understands its specific tasks and how it contributes to the overall recovery process. This structured approach improves efficiency and reduces delays caused by uncertainty or miscommunication.
Coordination also involves prioritizing tasks based on recovery objectives. Critical systems are restored first, followed by secondary systems, ensuring that business operations resume in the most efficient sequence possible.
Adapting BC/DR Plans to Changing Environments
Technology environments are constantly changing, and BC/DR plans must adapt accordingly. New applications, system upgrades, cloud migrations, and infrastructure changes all affect how recovery processes should be designed. A plan that works today may not be effective tomorrow if it does not account for these changes.
Adaptation involves reviewing BC/DR strategies whenever significant changes occur in the IT environment. This ensures that recovery procedures remain aligned with current system architecture and business needs. It also helps identify new risks introduced by technological changes, allowing organizations to adjust their strategies proactively.
Flexible BC/DR planning ensures long-term resilience. Instead of relying on static procedures, organizations build adaptive frameworks that can evolve with their environment, maintaining effectiveness over time.
Ensuring Long-Term Resilience Through BC/DR Practices
The ultimate goal of BC/DR planning is to ensure long-term resilience, allowing organizations to continue operating even under unexpected disruptions. This resilience is achieved through careful planning, regular testing, continuous improvement, and strong coordination between teams.
Long-term resilience is not just about recovering from failures but also about reducing the likelihood and impact of future disruptions. By analyzing past incidents and continuously refining strategies, organizations strengthen their ability to respond to new challenges.
This proactive approach helps businesses maintain stability, protect critical data, and ensure consistent service delivery even in uncertain conditions. BC/DR planning becomes a foundational part of operational strategy rather than just an emergency response mechanism.
Advanced Disaster Recovery Site Architectures
As organizations mature their Business Continuity and Disaster Recovery (BC/DR) capabilities, they often move toward more advanced infrastructure designs to improve resilience and reduce recovery time. One of the key areas of focus is the use of dedicated disaster recovery site architectures. These structures define where backup systems and replicated environments are hosted and how quickly operations can be restored when primary systems fail.
Common approaches include cold, warm, and hot site strategies. A cold site provides minimal infrastructure and requires significant time to restore systems, making it suitable for less critical workloads. A warm site offers partially prepared environments that can be activated more quickly, balancing cost and recovery speed. A hot site maintains a near-real-time replica of production systems, allowing for rapid failover with minimal downtime.
Each architecture is selected based on business needs, risk tolerance, and budget availability. Critical systems that require near-instant recovery often rely on highly redundant environments, while less essential systems use simpler and more cost-effective setups.
Data Backup Strategies in BC/DR Planning
Data backup strategies are a core component of any disaster recovery framework. They ensure that information can be restored in case of corruption, deletion, cyber incidents, or system failure. A strong backup strategy defines what data is backed up, how frequently backups occur, where they are stored, and how quickly they can be restored when needed.
Different backup methods exist to support various recovery needs. Full backups capture complete datasets, while incremental backups store only changes since the last backup, improving efficiency. Differential backups provide a middle ground by capturing changes since the last full backup. Each method offers a trade-off between speed, storage usage, and recovery time.
A well-designed backup strategy ensures that data loss is minimized and that recovery can be performed within acceptable time limits defined by business requirements. Without reliable backups, even the most advanced recovery infrastructure cannot restore lost information effectively.
Cloud-Based Disaster Recovery Approaches
Cloud computing has significantly transformed BC/DR planning by offering flexible, scalable, and cost-efficient recovery solutions. Cloud-based disaster recovery allows organizations to replicate systems and data in remote environments without maintaining fully physical secondary data centers. This approach improves accessibility and reduces infrastructure costs while increasing resilience.
One of the key advantages of cloud-based recovery is scalability. Organizations can quickly expand or reduce recovery resources based on demand, ensuring that systems are only using necessary resources during normal operations. During a disaster event, cloud environments can rapidly scale to support full production workloads.
Cloud solutions also enhance geographic redundancy, allowing data and applications to be stored in multiple regions. This reduces the risk of localized failures impacting overall business continuity. However, cloud-based strategies still require careful planning to ensure security, compliance, and proper configuration.
Automation in Disaster Recovery Processes
Automation plays an increasingly important role in modern BC/DR strategies. Automated recovery processes reduce the need for manual intervention during emergencies, allowing systems to be restored faster and with fewer errors. Automation tools can initiate backups, trigger failover systems, and restore services based on predefined conditions.
By reducing human dependency, automation minimizes the risk of mistakes that can occur during high-pressure situations. It also ensures consistency, as automated processes follow exact predefined steps every time they are executed. This predictability is critical for maintaining reliability during disaster recovery operations.
Automation also improves efficiency by enabling faster detection and response to system failures. Instead of waiting for manual action, systems can automatically begin recovery procedures as soon as a failure is detected. This significantly reduces downtime and improves overall resilience.
Security Considerations in BC/DR Planning
Security is a critical aspect of any BC/DR strategy because recovery systems must remain protected from unauthorized access, corruption, and cyber threats. During disaster recovery, systems are often in a vulnerable state, making them attractive targets for malicious activity.
To address this, BC/DR plans include strict security controls such as encryption, access management, and authentication mechanisms. These controls ensure that only authorized personnel can access recovery environments and sensitive data. Security policies must be consistently applied across both primary and backup systems to maintain integrity.
Additionally, recovery environments must be regularly tested for vulnerabilities. Security checks ensure that backup systems are not only functional but also protected against potential threats. This integrated approach ensures that recovery efforts do not compromise overall system security.
Compliance and Regulatory Requirements in BC/DR
Many industries operate under strict regulatory frameworks that require organizations to maintain effective BC/DR capabilities. These regulations often define minimum recovery standards, data protection requirements, and audit expectations. Compliance ensures that organizations can demonstrate their ability to recover from disruptions while protecting sensitive information.
BC/DR planning must therefore align with legal and regulatory obligations. This includes maintaining documentation, performing regular testing, and ensuring that recovery procedures meet defined standards. Failure to comply can result in penalties, legal consequences, and reputational damage.
Compliance also encourages consistency in recovery practices. By following established standards, organizations ensure that their BC/DR plans are robust, repeatable, and aligned with industry best practices.
Dependency Mapping and System Interconnections
Modern IT environments are highly interconnected, meaning that systems often depend on one another to function correctly. Dependency mapping is the process of identifying and documenting these relationships to ensure that recovery efforts follow the correct sequence.
Without understanding dependencies, restoring systems in the wrong order can lead to incomplete recovery or further system failures. For example, restoring an application without restoring its database or authentication system may result in functional errors.
By mapping dependencies, organizations can design recovery workflows that restore critical infrastructure in a logical and efficient sequence. This ensures that services become fully operational rather than partially functional during recovery.
Role of Risk Management in BC/DR Strategy
Risk management is deeply integrated into BC/DR planning. It involves identifying potential threats, evaluating their likelihood, and assessing their impact on business operations. This process helps organizations prioritize which risks require the most attention and resources.
Risks may include hardware failures, cyberattacks, natural disasters, or human error. Each risk is analyzed to determine how it could affect critical systems and how quickly recovery must occur to minimize damage. This structured evaluation helps guide recovery planning decisions.
By continuously managing risk, organizations can adapt their BC/DR strategies to address new threats as they emerge. This ensures that recovery plans remain relevant in a constantly changing technological and threat landscape.
Business Alignment and Strategic Recovery Planning
BC/DR planning is not purely a technical function; it must align with overall business goals and priorities. Recovery strategies should reflect what the organization values most, whether that is customer service continuity, financial stability, or operational efficiency.
This alignment ensures that recovery efforts support business objectives rather than functioning as isolated technical procedures. It also helps leadership understand the importance of investing in resilience and infrastructure improvements.
When BC/DR planning is closely aligned with business strategy, organizations are better prepared to maintain continuity during disruptions while minimizing long-term impact.
Resilience Through Continuous Adaptation
The strength of any BC/DR framework lies in its ability to adapt continuously to new conditions. As technology evolves and business needs change, recovery strategies must be updated to reflect these developments. Static plans quickly become ineffective in dynamic environments.
Continuous adaptation ensures that organizations remain resilient in the face of new challenges. By regularly reviewing systems, updating procedures, and improving recovery capabilities, businesses strengthen their ability to withstand disruptions.
This ongoing improvement cycle ensures that BC/DR planning remains a living process rather than a fixed document, supporting long-term operational stability and reliability.
BC/DR Plan Activation and Emergency Response Execution
When a real disruption occurs, Business Continuity and Disaster Recovery (BC/DR) planning moves from documentation into full execution. This stage is where prepared strategies are activated to restore services and stabilize operations. The activation process is not random; it follows predefined triggers that determine when an incident is severe enough to initiate recovery procedures. These triggers help ensure that the response is timely, controlled, and appropriate to the level of impact.
Once activation begins, emergency response teams take immediate control of the situation. Their first priority is to assess the scope of the disruption, identify affected systems, and confirm the severity of the outage. This initial assessment helps determine which recovery path should be followed and what resources are required. Speed is critical at this stage, but accuracy is equally important to avoid unnecessary actions that could worsen the situation.
Clear escalation procedures are also part of activation. As the incident progresses, it may require involvement from higher-level decision-makers or specialized technical teams. These escalation paths ensure that the right people are engaged at the right time, preventing delays and confusion during critical recovery operations.
Incident Assessment and Damage Evaluation
After activation, the next step in BC/DR execution is detailed incident assessment. This involves understanding exactly what has failed, why it failed, and how it is impacting business operations. Technical teams perform diagnostics to identify root causes, whether they are hardware failures, software issues, security breaches, or external disruptions.
Damage evaluation goes beyond technical systems and includes business impact. Organizations assess which services are unavailable, how customers are affected, and what financial or operational losses may occur. This combined analysis of technical and business impact helps prioritize recovery actions effectively.
Accurate assessment is essential because incorrect assumptions can lead to wasted effort or misdirected recovery attempts. The goal is to ensure that all actions are based on verified information, allowing teams to focus on restoring the most critical systems first.
Prioritization During Recovery Operations
Once the situation is fully understood, recovery teams must prioritize restoration efforts. Not all systems can be recovered simultaneously, so decisions must be made about which services are most important to restore first. This prioritization is based on predefined recovery objectives and business impact analysis conducted during planning stages.
Critical systems that directly affect business operations, customer access, or revenue generation are typically restored first. Secondary systems follow once core services are stabilized. This structured approach ensures that the organization can resume essential functions as quickly as possible, even if full recovery takes longer.
Prioritization also helps manage limited resources effectively. Technical teams, infrastructure capacity, and time are all constrained during emergencies, so focusing on high-impact systems ensures maximum business continuity with available resources.
MTD=Maximum tolerable downtime allowed before severe business impact occursMTD = \text{Maximum tolerable downtime allowed before severe business impact occurs}MTD=Maximum tolerable downtime allowed before severe business impact occurs
Communication Flow During Active Recovery
During active disaster recovery, communication becomes one of the most important operational components. Clear, structured communication ensures that all stakeholders remain informed about the situation, recovery progress, and expected timelines. Without proper communication, confusion can spread quickly, leading to delays and misaligned actions.
Communication flows are typically predefined in BC/DR plans. These include internal updates between technical teams, management briefings for decision-makers, and external communication for customers or partners if necessary. Each communication channel serves a specific purpose and ensures that the right information reaches the right audience.
Regular updates are critical during recovery operations. Even if there is no major progress, maintaining communication helps manage expectations and reduces uncertainty. This transparency is essential for maintaining trust during disruptive events.
Restoration of IT Systems and Services
System restoration is the core technical activity in disaster recovery execution. This involves bringing failed systems back online using predefined recovery methods such as backups, replicas, or failover environments. The exact approach depends on the recovery strategy designed during planning stages.
Technical teams follow step-by-step procedures to restore services in the correct order. This often includes restoring infrastructure components first, followed by applications, and finally user-facing services. Proper sequencing ensures that dependencies are satisfied and systems function correctly after restoration.
Verification is also an important part of restoration. Once systems are recovered, they must be tested to ensure they are operating correctly and meeting performance expectations. This validation step ensures that recovery efforts are successful and that services are stable before being fully handed back to users.
RTO=Target time within which systems must be restored after disruptionRTO = \text{Target time within which systems must be restored after disruption}RTO=Target time within which systems must be restored after disruption
Handling Partial Recovery and Service Degradation
In many real-world scenarios, full recovery may not be immediately possible. Instead, organizations may achieve partial recovery, where some systems are restored while others remain unavailable. In such cases, BC/DR planning allows for controlled service degradation to maintain essential operations.
Partial recovery strategies ensure that critical business functions continue running even if full system capacity is not yet restored. This may involve temporary workarounds, reduced service levels, or simplified system functionality. The goal is to maintain operational continuity while full recovery is still in progress.
Managing degraded services requires careful coordination to ensure users are aware of limitations and internal teams understand operational constraints. This helps maintain stability while recovery efforts continue in the background.
Post-Recovery Validation and Stability Checks
After systems are restored, they must undergo thorough validation to confirm stability and functionality. This includes testing system performance, verifying data integrity, and ensuring that all dependencies are functioning correctly. Without this step, hidden issues may remain undetected and cause further disruptions later.
Stability checks ensure that systems can handle normal operational loads without failure. They also confirm that no data corruption or loss occurred during recovery. This phase is essential for ensuring that recovery efforts are not only complete but also reliable.
Once validation is successful, systems are gradually transitioned back into normal production use. This controlled transition ensures that any remaining issues can be identified and resolved without causing additional disruptions.
Transition Back to Normal Operations
The final stage of recovery execution involves transitioning from emergency mode back to normal business operations. This transition is carefully managed to ensure stability and avoid reintroducing issues. Systems are monitored closely during this phase to confirm that they remain stable under regular workloads.
Teams also conduct final reviews to ensure all recovery objectives have been met. This includes confirming that downtime targets were achieved, data integrity is intact, and all critical systems are functioning as expected.
Once normal operations resume, the organization begins documenting the incident, analyzing performance, and identifying improvements for future BC/DR planning. This marks the completion of the active recovery cycle and feeds directly into continuous improvement processes.
Post-Incident Review and Lessons Learned Process
After a disaster recovery event is resolved and systems are fully restored, the next essential phase in Business Continuity and Disaster Recovery (BC/DR) planning is the post-incident review. This stage focuses on analyzing what happened, how effectively the response was handled, and what improvements can be made to prevent similar issues in the future. It is a structured reflection process that transforms a real incident into valuable learning for the organization.
During this review, teams gather all relevant information about the incident timeline, system behavior, response actions, and communication flow. The goal is to reconstruct the entire event from detection to recovery. This helps identify strengths in the response process as well as areas where delays, confusion, or inefficiencies occurred.
The lessons learned process is not about assigning blame but about improving resilience. Every incident provides insight into system weaknesses, procedural gaps, or communication challenges. By documenting these findings, organizations strengthen future BC/DR readiness and reduce the likelihood of repeated failures.
Root Cause Analysis in Disaster Events
A critical part of post-incident evaluation is root cause analysis. This process goes beyond surface-level symptoms and investigates the underlying reason why the disruption occurred. Whether the issue was a system failure, configuration error, cyber incident, or external dependency failure, identifying the root cause is essential for long-term stability.
Root cause analysis involves reviewing logs, system behavior, infrastructure changes, and operational actions that led to the incident. Technical teams work to trace the sequence of events that triggered the failure. This detailed investigation helps ensure that solutions address the actual problem rather than just the visible symptoms.
Once the root cause is identified, corrective actions are developed. These may include system redesigns, configuration changes, improved monitoring, or updated recovery procedures. The goal is to eliminate or reduce the risk of the same failure occurring again in the future.
Performance Evaluation of Recovery Teams
Another important aspect of BC/DR improvement is evaluating how effectively recovery teams performed during the incident. This evaluation focuses on response time, decision-making accuracy, communication efficiency, and adherence to predefined recovery procedures.
Teams are assessed based on how quickly they identified the issue, how effectively they followed recovery plans, and how well they coordinated with other groups. This helps determine whether training, documentation, or communication processes need improvement.
Performance evaluation also highlights strengths in the recovery process. Identifying what worked well is just as important as identifying weaknesses, as it helps reinforce successful strategies and ensure they are maintained in future incidents.
Updating BC/DR Documentation After Incidents
Once lessons are identified and performance is reviewed, BC/DR documentation must be updated to reflect new insights. This ensures that recovery plans remain accurate and effective for future incidents. Outdated procedures can lead to confusion or delays, so continuous documentation updates are essential.
Updates may include revised recovery steps, updated contact information, improved escalation procedures, or changes in system priorities. These adjustments ensure that future responses are faster, more accurate, and better aligned with real-world conditions.
Documentation updates also help standardize improvements across the organization. By incorporating lessons learned into official procedures, all teams benefit from improved guidance during future disruptions.
Strengthening System Resilience After Recovery
After an incident, organizations often take additional steps to strengthen system resilience. This involves improving infrastructure, enhancing redundancy, and implementing stronger monitoring systems to detect issues earlier. The goal is to reduce the likelihood of future disruptions and improve recovery speed when issues do occur.
Resilience improvements may include upgrading hardware, improving network design, increasing backup frequency, or implementing more advanced failover mechanisms. These enhancements ensure that systems are better prepared to handle similar or more severe incidents in the future.
Strengthening resilience is a continuous process that evolves based on real-world experience. Each incident provides new insights that help improve system reliability and operational stability.
Improving Monitoring and Early Detection Systems
Monitoring plays a critical role in preventing disasters or reducing their impact. After an incident, organizations often review and improve their monitoring systems to ensure earlier detection of potential failures. Early detection allows teams to respond before issues escalate into major disruptions.
Monitoring improvements may include better alert configurations, more detailed logging, or advanced analytics tools that detect anomalies in system behavior. These enhancements help reduce detection time and improve overall response efficiency.
Effective monitoring also supports proactive maintenance. By identifying warning signs early, organizations can resolve issues before they impact business operations, reducing downtime and improving service reliability.
MTTR=Mean Time to Recover or Restore a failed systemMTTR = \text{Mean Time to Recover or Restore a failed system}MTTR=Mean Time to Recover or Restore a failed system
Training and Skill Development for BC/DR Teams
Continuous training is essential for maintaining an effective BC/DR capability. After incidents, organizations often identify skill gaps or procedural misunderstandings that need to be addressed. Training ensures that all team members are prepared to respond effectively in future events.
Training programs may include simulation exercises, hands-on recovery drills, and scenario-based learning. These activities help teams become familiar with recovery procedures and improve their ability to perform under pressure.
Skill development also ensures that teams stay updated with evolving technologies and recovery tools. As systems change, training helps maintain alignment between technical capabilities and recovery requirements.
Organizational Learning and Process Maturity
Each incident contributes to the overall maturity of an organization’s BC/DR framework. Over time, repeated learning cycles lead to more refined processes, faster recovery times, and stronger system resilience. This maturity reflects how well an organization can adapt to disruptions and maintain continuity under pressure.
Organizational learning ensures that BC/DR planning becomes more proactive rather than reactive. Instead of only responding to failures, organizations begin anticipating risks and strengthening systems before problems occur.
This continuous improvement cycle transforms BC/DR planning into a strategic capability that supports long-term business stability and operational excellence.
Conclusion
Business Continuity and Disaster Recovery (BC/DR) planning is a structured approach that ensures an organization can maintain essential operations and quickly restore services when unexpected disruptions occur. It is not limited to technical recovery alone but represents a complete framework that connects business priorities, risk management, system design, and operational response into one coordinated strategy.
Through careful planning, organizations define how critical systems should be protected, how long downtime can be tolerated, and what steps must be taken to restore services efficiently. These decisions are based on business impact, risk evaluation, and recovery objectives that guide how resources are allocated during both normal operations and crisis situations.
BC/DR planning also emphasizes preparation before incidents occur. Assigning ownership, defining policies, conducting business impact analysis, and establishing recovery strategies all ensure that organizations are not reacting blindly during emergencies. Instead, they follow a structured roadmap that improves speed, accuracy, and coordination.
During actual disruptions, BC/DR processes come to life through incident response, system restoration, communication, and recovery execution. Each step is carefully designed to reduce downtime, protect data, and restore essential services in the correct order. Once recovery is complete, post-incident reviews and continuous improvement cycles help strengthen future readiness by identifying weaknesses and refining procedures.
Ultimately, BC/DR planning is not a one-time task but an ongoing discipline. It evolves with technology, business growth, and emerging risks. Organizations that invest in strong BC/DR frameworks are better positioned to handle uncertainty, maintain operational stability, and ensure long-term resilience in an increasingly dependent digital environment.