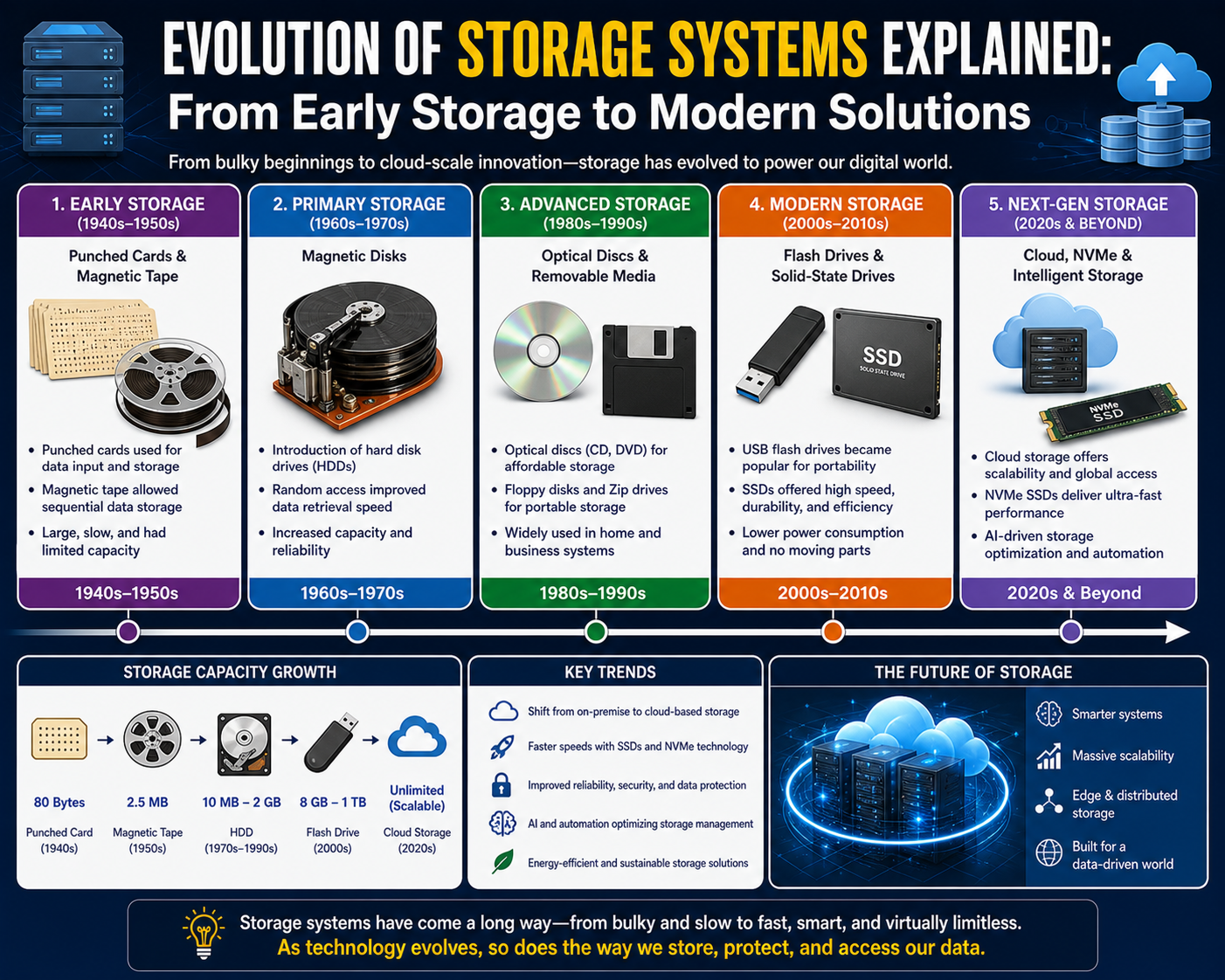
The evolution of storage systems in enterprise computing reflects a long-term shift in how organisations store, access, and manage data at scale. As digital workloads expanded, storage moved from being a simple hardware component inside individual machines to becoming a centralised, highly distributed, and software-driven resource. This transformation was not sudden but occurred through multiple architectural generations, each designed to solve specific limitations in performance, scalability, and operational efficiency.
In modern IT environments, storage is no longer treated as an isolated function. It is deeply integrated with compute resources, networking layers, and virtualisation systems. However, this level of integration is the result of decades of incremental improvements. Each stage in the evolution of storage systems introduced new design philosophies that shaped how data is delivered to applications today. These stages include server-local storage, centralised storage networks, and software-defined hyper-converged systems.
Understanding this evolution is essential because it explains why modern infrastructures are designed the way they are. It also clarifies why older models, although simpler, became insufficient as enterprise demands increased.
Early Server-Centric Storage Architecture and Direct-Attached Storage
In the earliest phase of enterprise computing, storage was physically embedded within servers. This model is known as direct-attached storage, where hard drives or storage devices are directly connected to a single system without being shared across a network. Each server operated as an independent unit with its own compute power and local storage capacity.
This architecture was straightforward and efficient for early workloads. Applications were typically monolithic, meaning they ran entirely on one machine and stored all necessary data locally. File servers, database systems, and basic application servers could function effectively in this environment because data access patterns were relatively simple and predictable.
A major advantage of this model was low latency. Since storage was directly connected to the server’s internal bus, data retrieval was fast and did not depend on external network communication. This made performance consistent for single-server workloads.
However, as organisations scaled, several structural limitations became apparent. One of the most significant issues was resource isolation. Each server had its own fixed storage capacity, and there was no mechanism to dynamically share unused space between systems. If one server ran out of storage while another had excess capacity, the resources could not be redistributed. This led to inefficient utilisation across the infrastructure.
Another challenge was operational fragmentation. IT teams had to manage storage independently on each server, including configuration, monitoring, and maintenance. As the number of servers increased, this approach became increasingly difficult to sustain. Consistency in storage policies also became harder to enforce, especially in larger enterprise environments where multiple administrators were involved.
Storage Constraints in Early Distributed Workloads
As computing environments evolved beyond single-server applications, workloads began to spread across multiple systems. This introduced new challenges for direct-attached storage architectures. Applications increasingly required access to shared datasets, but isolated storage prevented seamless data sharing between servers.
For example, a web application running on multiple servers needed access to the same database files. In a direct-attached model, this required complex replication strategies or manual synchronisation processes. These methods introduced delays, inconsistencies, and increased the risk of data corruption.
Storage planning also became a major operational burden. Since each server had a fixed capacity, administrators had to forecast storage requirements far in advance. Underestimating storage led to performance degradation or service interruptions, while overestimating resulted in wasted hardware resources.
Backup and recovery processes added another layer of complexity. Data protection strategies often require copying information from multiple independent systems into centralised backup locations. This increased storage overhead and made recovery operations more time-consuming.
As data volumes continued to grow, these limitations highlighted the need for a more flexible and centralised storage model that could decouple storage resources from individual servers.
Emergence of Centralised Storage Systems and SAN Architecture
The next major stage in storage evolution introduced centralised storage systems, commonly implemented through storage area networks. In this model, storage devices were removed from individual servers and consolidated into a dedicated storage infrastructure. Servers accessed storage over a high-speed network rather than relying on internal disks.
This architectural shift fundamentally changed how storage was managed. Instead of each server maintaining its own isolated storage pool, multiple servers could now access shared storage resources simultaneously. This enabled better utilisation of capacity and simplified storage provisioning across the enterprise.
Centralised storage systems also introduced more advanced data management capabilities. Storage arrays could implement features such as redundancy, caching, and optimised data placement strategies. This improved reliability and performance compared to earlier server-based models.
Network design became a critical factor in this architecture. Storage access depended heavily on the performance of the underlying network infrastructure. Technologies such as fibre-based networking and high-speed Ethernet connections were commonly used to ensure low-latency data transfer between servers and storage arrays.
However, this model also introduced new layers of complexity. Storage systems became separate specialized infrastructures requiring dedicated administration. Organisations needed to manage not only compute servers but also complex storage arrays, networking configurations, and compatibility between components.
Despite these challenges, centralised storage significantly improved scalability. Storage capacity could now be expanded independently of compute resources, allowing organisations to grow infrastructure more efficiently based on demand.
Storage Area Networks and Enterprise Scalability
Storage area networks played a critical role in enabling enterprise-grade storage scalability. By separating storage from compute, organisations could build large shared storage pools accessible by multiple servers. This architecture supported workloads that required high availability, redundancy, and centralised data management.
One of the key advantages of storage area networks was improved resource utilisation. Instead of having fragmented storage across multiple servers, organisations could aggregate storage into unified systems. This allowed for more efficient allocation of capacity based on actual workload needs.
Data redundancy mechanisms also became more sophisticated in this model. Storage systems could implement advanced protection techniques, ensuring that data remained available even in the event of hardware failures. This improved system reliability and reduced the risk of data loss.
However, storage area networks also introduced dependency on specialised hardware and configuration expertise. Managing these systems required knowledge of storage protocols, network topologies, and performance tuning. As environments grew larger, this complexity became a limiting factor for some organisations.
Even with these challenges, centralised storage remained the dominant enterprise model for many years due to its scalability and reliability advantages compared to direct-attached storage systems.
Transition Toward Virtualisation and Resource Abstraction
As enterprise computing continued to evolve, virtualisation technologies began to reshape how resources were used. Virtual machines allowed multiple operating systems to run on a single physical server, increasing hardware efficiency and flexibility.
This shift had a direct impact on storage architecture. Virtualised environments required storage systems that could support dynamic provisioning, rapid scaling, and shared access across multiple virtual instances. Traditional storage models struggled to keep up with these demands due to their rigid structure.
Storage abstraction became increasingly important during this phase. Instead of treating storage as a fixed hardware resource, it began to be managed as a flexible pool that could be allocated dynamically. This concept laid the groundwork for software-defined storage models that would later emerge in hyper-converged systems.
At the same time, performance requirements increased significantly. Virtualised workloads often run multiple applications simultaneously, placing higher demands on storage throughput and latency. This forced continued innovation in caching mechanisms, data optimisation techniques, and storage networking performance.
Early Steps Toward Distributed and Software-Defined Storage Thinking
As centralised storage systems matured, limitations in scalability and management complexity became more visible. Organisations began exploring distributed approaches that could reduce reliance on fixed hardware architectures.
This led to the early development of software-defined storage concepts, where storage resources could be managed through software layers rather than physical configuration. The idea was to decouple storage intelligence from hardware devices and create a unified control layer capable of managing diverse storage resources.
Distributed storage thinking also emphasised resilience. By spreading data across multiple systems, organisations could improve fault tolerance and ensure higher availability. This approach reduced the impact of hardware failures and supported more robust enterprise environments.
These developments marked a significant transition point in storage evolution. The focus shifted from simply centralising storage to making it more intelligent, flexible, and adaptable to changing workload requirements. This foundation would eventually lead to hyper-converged infrastructure, where storage and compute are integrated into a unified software-driven system.
The Rise of Converged Infrastructure in Enterprise IT
As enterprise computing demands continued to grow, organisations began searching for ways to simplify infrastructure management while improving scalability and performance. The traditional model of separate compute servers and external storage systems created operational overhead that became increasingly difficult to manage at scale. This led to the emergence of converged infrastructure, an architectural approach that aimed to bundle compute, storage, and networking components into a more unified and standardised system.
Converged infrastructure represented a major shift in how IT resources were deployed and maintained. Instead of assembling hardware components individually, organisations could adopt pre-integrated systems designed to work together as a cohesive unit. This reduced the complexity of system design and allowed for more predictable performance outcomes.
In this model, storage was removed from individual servers and placed into centralised storage systems, typically storage area networks. Compute resources remained in server clusters, while networking connected everything together. Although the components were still physically separate, they were packaged and managed as a single infrastructure solution.
The primary goal of converged infrastructure was operational simplification. By standardising hardware configurations and integration patterns, organisations could reduce deployment time and minimise compatibility issues between components. This approach also improved supportability, as vendors could provide unified management tools and troubleshooting frameworks for the entire system.
However, while converged infrastructure improved manageability, it did not fundamentally change the underlying architecture of storage systems. Storage still existed as a separate layer, and compute resources still depended on external access to data through networked storage arrays.
Centralised Storage in Converged Systems and Its Operational Impact
In converged infrastructure environments, storage systems were typically implemented through centralised storage arrays. These systems aggregated storage capacity from multiple disks and presented it as shared resources accessible by multiple servers. This architecture improved resource utilisation compared to isolated server-based storage, but it also introduced new operational dependencies.
One of the key benefits of centralised storage in converged systems was simplified management. Instead of configuring storage on each server, administrators could manage storage pools through a single interface. This allowed for more consistent policy enforcement and reduced administrative overhead.
Centralised storage also enabled more efficient capacity planning. Storage could be allocated dynamically across different workloads, reducing the risk of underutilised or stranded storage resources. This pooling of resources allowed organisations to scale storage independently from compute infrastructure, which improved flexibility in enterprise environments.
Despite these advantages, centralised storage introduced performance considerations that required careful planning. Since all storage requests flowed through a shared system, storage arrays became critical points of infrastructure dependency. Network bandwidth, latency, and storage controller performance all played a role in determining application responsiveness.
As workloads became more diverse and data-intensive, these centralised systems often required significant tuning to maintain optimal performance. High-performance applications, such as transactional databases or real-time analytics platforms, placed increasing pressure on storage infrastructure.
Storage Area Networks as the Backbone of Converged Architecture
Storage area networks served as the foundation for converged infrastructure storage design. These networks provided dedicated high-speed communication channels between compute servers and centralised storage arrays. Unlike traditional network-attached storage systems, storage area networks were optimised for block-level data access, enabling faster and more efficient data transfers.
The separation of storage traffic from general network traffic improved performance consistency. By isolating storage communication onto dedicated networks, organisations could reduce congestion and ensure predictable latency for critical workloads.
Storage area networks also enabled advanced storage features such as replication, snapshots, and tiered storage management. These capabilities allowed organisations to improve data protection strategies and optimise storage utilisation based on workload requirements.
However, managing storage area networks required specialised knowledge and infrastructure planning. Administrators needed to understand storage protocols, zoning configurations, and performance tuning techniques to ensure optimal system behaviour. This added complexity made storage management more specialised within IT teams.
Even with these challenges, storage area networks remained a dominant architecture in enterprise environments due to their scalability and reliability advantages compared to earlier storage models.
Operational Challenges of Converged Infrastructure Models
While converged infrastructure simplified certain aspects of deployment, it also introduced new operational constraints. One of the primary challenges was the rigid coupling of hardware components within predefined systems. Although compute, storage, and networking were packaged together, they still operated as distinct layers with limited flexibility between them.
Scaling infrastructure often requires purchasing additional pre-configured systems rather than scaling individual components independently. This approach could lead to inefficiencies when workloads require more storage but not additional compute resources, or vice versa.
Another challenge was infrastructure complexity hidden beneath simplified management interfaces. While converged systems provided unified dashboards, the underlying architecture still consisted of multiple interconnected subsystems. Troubleshooting performance issues often requires deep knowledge of storage networks, compute clusters, and hardware interactions.
Additionally, converged systems introduced vendor dependency. Since components were tightly integrated and often pre-validated by manufacturers, organisations were typically locked into specific hardware ecosystems. This reduced flexibility in selecting best-of-breed components across different infrastructure layers.
Despite these limitations, converged infrastructure played an important role in bridging the gap between traditional server-based storage and more modern software-defined architectures.
Growth of Virtualisation and Its Influence on Storage Design
The rise of virtualisation significantly influenced the evolution of storage systems within converged infrastructure environments. Virtual machines allowed multiple workloads to run on shared physical hardware, increasing resource utilisation and flexibility.
However, virtualisation also introduced new storage challenges. Virtualised environments required storage systems that could support rapid provisioning, high IOPS performance, and simultaneous access from multiple virtual machines. Traditional storage architectures often struggled to meet these demands efficiently.
As a result, storage systems began incorporating features specifically designed for virtualised workloads. These included thin provisioning, deduplication, and automated tiering. These enhancements improved storage efficiency and reduced waste in virtualised environments.
Storage performance also became more critical in virtualisation-heavy environments. Since multiple virtual machines could be competing for the same underlying storage resources, performance bottlenecks in storage systems could impact multiple workloads simultaneously.
This led to increased focus on storage optimisation techniques, including caching mechanisms, faster storage media, and improved data placement strategies within storage arrays.
Increasing Complexity of Data Growth and Storage Demands
As digital transformation accelerated across industries, data volumes began to grow exponentially. Organisations were no longer dealing with static datasets but with continuous streams of structured and unstructured data. This growth placed additional strain on existing storage architectures.
Converged infrastructure systems, while more efficient than earlier models, still relied heavily on centralised storage management. As data demands increased, these systems began to encounter scalability limitations. Expanding storage capacity often requires significant hardware upgrades and careful integration planning.
The diversity of data types also created new challenges. Traditional storage systems were optimised for structured data, but modern applications increasingly rely on unstructured formats such as multimedia content, sensor data, and machine-generated logs.
This shift forced organisations to rethink how storage systems were designed and managed. Flexibility, scalability, and automation became increasingly important factors in infrastructure planning.
Early Movement Toward Software-Defined Infrastructure Principles
To address growing complexity, the industry began moving toward software-defined infrastructure models. This approach separated control logic from physical hardware, allowing storage and compute resources to be managed through software layers rather than hardware configurations.
In storage systems, this meant abstracting physical disks into logical storage pools that could be dynamically allocated and managed. This abstraction enabled greater flexibility in how storage resources were consumed and distributed across workloads.
Software-defined principles also improved automation capabilities. Storage provisioning, scaling, and optimisation could be handled through policy-driven systems rather than manual configuration. This reduced operational overhead and improved consistency across infrastructure environments.
These early software-defined concepts laid the foundation for more advanced architectures where storage and compute would eventually be fully integrated under a unified management framework.
Limitations of Hybrid Infrastructure Models in Scaling Environments
Although converged infrastructure improved upon earlier models, it still represented a hybrid approach that maintained separation between compute and storage layers. This separation created inefficiencies in environments where workloads required rapid scaling and dynamic resource allocation.
As organisations adopted cloud-like operating models, the limitations of rigid infrastructure boundaries became more apparent. Workloads needed to scale horizontally, move between systems, and adapt to changing performance demands without manual intervention.
Converged systems were not fully optimised for this level of dynamism. While they provided improved integration compared to earlier architectures, they still relied on predefined hardware relationships and centralised storage control mechanisms.
These constraints drove further innovation in infrastructure design, ultimately leading toward hyper-converged systems where storage and compute would be fully integrated and managed through unified software platforms.
The Emergence of Hyper-Converged Infrastructure in Modern IT
Hyper-converged infrastructure represents the most significant shift in the evolution of enterprise storage systems. It moves beyond the separation of compute and storage found in traditional and converged models by integrating both into a single software-defined architecture. In this model, storage is no longer treated as an external system or a separate appliance. Instead, it is embedded directly into the compute layer and managed entirely through software.
This approach was developed in response to growing infrastructure complexity and the limitations of centralised storage systems. As organisations adopted virtualisation at scale, managing separate compute clusters and storage arrays became increasingly inefficient. Hyper-converged infrastructure addresses this by collapsing multiple infrastructure layers into unified building blocks, often referred to as nodes.
Each node in a hyper-converged system typically contains compute resources, local storage drives, and networking components. However, unlike early server-centric models, storage is not isolated within each node. Instead, software aggregates all storage across nodes into a single shared pool that can be dynamically allocated to workloads.
This architecture fundamentally changes how infrastructure is designed, deployed, and managed. It eliminates the need for separate storage networks and reduces dependency on specialised storage hardware. Instead, everything is controlled through a unified software layer that abstracts physical resources into logical services.
Software-Defined Storage as the Core of Hyper-Converged Systems
At the heart of hyper-converged infrastructure lies software-defined storage. This concept separates storage intelligence from physical hardware and places it into a software layer responsible for managing data distribution, redundancy, and performance optimisation.
In traditional storage architectures, hardware controllers determine how data is stored and retrieved. In hyper-converged systems, this responsibility is shifted to software running across multiple nodes. This allows storage behaviour to be dynamically adjusted based on workload requirements rather than fixed hardware configurations.
Software-defined storage enables several key capabilities. It allows storage capacity from multiple nodes to be combined into a single logical pool. It also enables data to be automatically replicated across nodes for redundancy and fault tolerance. If one node fails, data remains accessible through other nodes in the cluster.
Another important feature is data distribution optimisation. Instead of relying on a central storage array, data is spread across multiple nodes in a way that balances performance and capacity utilisation. This reduces bottlenecks and improves overall system efficiency.
This software-centric approach also simplifies management. Administrators no longer need to configure individual storage devices or manage complex storage area networks. Instead, they interact with a unified management interface that handles resource allocation automatically based on defined policies.
Integration of Compute and Storage Resources in Unified Nodes
One of the defining characteristics of hyper-converged infrastructure is the tight integration of compute and storage within the same physical node. Each node functions as a self-contained unit capable of contributing both processing power and storage capacity to the overall system.
This integration eliminates the traditional boundary between compute servers and storage arrays. Instead of treating storage as an external dependency, it becomes an intrinsic part of the compute environment. This design significantly reduces latency because data does not need to travel across separate storage networks.
When multiple nodes are combined into a cluster, their resources are pooled together. From the perspective of applications running on the system, there is no distinction between local and remote storage. Everything appears as part of a unified storage fabric managed by software.
This model also improves scalability. Organisations can expand infrastructure by simply adding more nodes to the cluster. Each new node contributes additional compute and storage resources, allowing the system to scale horizontally without requiring major architectural changes.
The modular nature of hyper-converged infrastructure simplifies deployment as well. New nodes can be integrated into existing clusters with minimal configuration, enabling faster expansion compared to traditional storage systems.
Elimination of Traditional Storage Area Networks
Hyper-converged infrastructure removes the need for traditional storage area networks. In earlier architectures, storage area networks were responsible for connecting servers to centralised storage arrays using high-speed networking protocols. While effective, this approach introduced complexity and required specialised networking configurations.
In hyper-converged systems, storage traffic is handled through standard network connections between nodes. Since storage is distributed across all nodes, there is no need for a dedicated storage network. This reduces infrastructure complexity and lowers hardware requirements.
By eliminating storage area networks, organisations can simplify network design and reduce operational overhead. There is no need for separate zoning, specialised storage switches, or dedicated storage controllers. Instead, standard networking hardware can be used to support both compute and storage communication.
This simplification also improves fault tolerance. Since data is distributed across multiple nodes, the system does not rely on a single centralised storage point. Even if one node or network path fails, data remains accessible through other parts of the cluster.
However, this model places greater emphasis on network performance within the cluster. Since all storage operations occur over the same network used for compute communication, ensuring sufficient bandwidth and low latency becomes critical for maintaining system performance.
Data Distribution, Redundancy, and Resilience in HCI Systems
Hyper-converged infrastructure systems are designed with built-in resilience mechanisms that ensure data availability even in the presence of hardware failures. One of the key methods used to achieve this is data replication across multiple nodes.
When data is written to the system, it is automatically copied to multiple locations within the cluster. This ensures that if one node fails, the data can still be accessed from another node without interruption. The level of replication can be configured based on performance and redundancy requirements.
In addition to replication, some systems use erasure coding techniques to optimise storage efficiency while maintaining fault tolerance. These methods break data into fragments and distribute them across multiple nodes, allowing the system to reconstruct data even if parts of the storage infrastructure become unavailable.
Another important aspect of resilience is self-healing capability. Hyper-converged systems continuously monitor the health of nodes and storage components. If a failure is detected, the system automatically redistributes data and workloads to maintain operational continuity.
This automated approach reduces the need for manual intervention and improves recovery times compared to traditional storage systems. It also enhances overall system reliability, making hyper-converged infrastructure suitable for mission-critical applications.
Performance Optimisation in Distributed Storage Environments
Performance in hyper-converged infrastructure is achieved through a combination of distributed architecture and software optimisation techniques. Since storage is spread across multiple nodes, workloads can access data from the nearest or least congested resources.
Caching plays a critical role in improving performance. Frequently accessed data is stored in faster memory layers, reducing the need to retrieve information from slower storage devices. This improves response times for applications and reduces overall system latency.
Load balancing is another important factor. Hyper-converged systems distribute storage and compute workloads evenly across all available nodes. This prevents any single node from becoming a performance bottleneck and ensures consistent resource utilisation.
The use of modern storage media such as solid-state drives further enhances performance. These drives provide significantly faster read and write speeds compared to traditional spinning disks, making them well-suited for high-performance workloads.
Together, these optimisation techniques allow hyper-converged systems to deliver predictable performance even under heavy and variable workloads.
Operational Simplicity and Unified Management Models
One of the most significant advantages of hyper-converged infrastructure is operational simplicity. Traditional environments required separate teams or skill sets to manage compute, storage, and networking components. Hyper-converged systems consolidate these responsibilities into a single management framework.
Administrators interact with a unified interface that provides visibility into all infrastructure components. This includes compute usage, storage capacity, network performance, and system health metrics. Policies can be defined at a high level and automatically applied across the entire infrastructure.
Automation is a key feature of this model. Tasks such as provisioning storage, balancing workloads, and managing data redundancy are handled automatically by the system. This reduces manual workload and minimises the risk of configuration errors.
The unified management approach also improves consistency. Since all resources are controlled through the same software layer, policies are applied uniformly across the infrastructure. This ensures predictable behaviour and simplifies compliance with organisational standards.
Scalability and Cloud-Ready Infrastructure Design
Hyper-converged infrastructure is designed to scale horizontally, making it well-suited for cloud-like environments. Instead of upgrading individual components within a system, organisations can scale by adding additional nodes.
This modular approach allows infrastructure to grow incrementally based on demand. Each new node increases both compute and storage capacity, enabling balanced scaling without overprovisioning specific resources.
This scalability aligns closely with modern cloud computing principles. Workloads can be distributed dynamically across the cluster, and resources can be allocated based on real-time demand. This flexibility supports a wide range of applications, from enterprise databases to virtual desktop environments.
The cloud-ready nature of hyper-converged systems also makes them suitable for hybrid environments where on-premises infrastructure integrates with cloud-based services.
The Continuing Evolution of Storage Systems Beyond Hyper-Convergence
While hyper-converged infrastructure represents a major milestone in storage evolution, it is not the final stage. The continued growth of data-intensive applications, artificial intelligence workloads, and edge computing environments is driving further innovation.
Future storage systems are expected to become even more distributed, intelligent, and automated. Storage will likely continue to move closer to applications, with greater emphasis on real-time data processing and decentralised architectures.
The evolution of storage systems demonstrates a consistent trend toward abstraction, automation, and integration. From isolated server storage to fully software-defined infrastructure, each stage has reduced complexity while increasing scalability and flexibility in enterprise environments.
Conclusion
The evolution of storage systems reflects one of the most important architectural transformations in enterprise computing, driven by continuous changes in how data is created, accessed, and processed. What began as simple, self-contained storage inside individual servers has gradually evolved into highly distributed, software-defined environments capable of supporting massive global workloads. Each stage in this progression—direct-attached storage, centralised storage networks, converged infrastructure, and hyper-converged systems—emerged to solve the inefficiencies of the previous model while introducing new capabilities that reshaped how organisations design and manage IT infrastructure.
In the earliest phase, storage was tightly bound to individual servers, creating a straightforward but limited model. Each machine managed its own data locally, which worked well when applications were simple and data volumes were relatively small. However, this approach quickly became inefficient as organisations scaled. Storage resources were locked within specific machines, making it impossible to share unused capacity or dynamically redistribute resources. This led to fragmentation, wasted capacity, and significant administrative overhead. IT teams had to manage each server individually, which became increasingly complex as environments expanded.
The introduction of centralised storage systems marked a major turning point. By separating storage from compute and placing it into dedicated systems, organisations gained the ability to pool resources and improve utilisation. Storage area networks allowed multiple servers to access shared data, enabling greater flexibility and scalability. This shift also improved data management practices by centralising control and introducing more advanced features such as redundancy, snapshots, and performance optimisation techniques. However, this model also introduced new dependencies on network performance and specialised infrastructure components, increasing overall system complexity.
As enterprises continued to grow and adopt virtualisation technologies, converged infrastructure emerged as a way to simplify deployment and management. By packaging compute, storage, and networking into integrated systems, organisations could reduce configuration effort and improve consistency across environments. Although storage was still externalised in centralised systems, the overall infrastructure became easier to deploy and maintain. Converged systems helped standardise enterprise architectures, but they still relied on separate storage layers, which limited flexibility in rapidly changing environments.
The limitations of converged infrastructure became more apparent as workloads became more dynamic and data volumes increased exponentially. Organisations needed infrastructure that could scale more efficiently, reduce operational complexity, and adapt to cloud-like usage patterns. This demand led to the development of hyper-converged infrastructure, which fundamentally redefined how storage is implemented. Instead of treating storage as a separate layer, hyper-converged systems integrate storage directly into compute nodes and manage it entirely through software. This eliminates traditional boundaries between infrastructure components and allows resources to be pooled and managed as a unified system.
Hyper-converged infrastructure represents a shift from hardware-centric design to software-defined architecture. Storage is no longer tied to physical devices or centralised arrays. Instead, it is abstracted into a shared resource pool distributed across all nodes in a cluster. This allows data to be dynamically allocated, replicated, and optimised based on workload requirements. The result is a highly flexible system that can scale horizontally by simply adding new nodes, each contributing additional compute and storage capacity.
One of the most significant advantages of this model is operational simplicity. Traditional storage architectures required specialised teams to manage storage arrays, networking equipment, and compute servers separately. Hyper-converged systems unify these responsibilities under a single management interface. Administrators can define policies that automatically control how data is stored, replicated, and distributed across the infrastructure. This reduces manual intervention, minimises configuration errors, and improves consistency across environments.
Another important benefit is improved resilience. Since data is distributed across multiple nodes, the system can tolerate hardware failures without service disruption. If one node fails, data remains accessible from other nodes in the cluster. This built-in redundancy eliminates the need for complex external backup systems in many scenarios and enhances overall system reliability. Additionally, automated recovery mechanisms ensure that the system can self-heal by redistributing workloads and restoring redundancy levels without manual intervention.
Performance optimisation is also a key strength of hyper-converged systems. By distributing storage across multiple nodes, data access can be balanced to reduce bottlenecks. Frequently accessed data can be cached closer to compute resources, improving response times and reducing latency. Modern storage media, such as solid-state drives, further enhance performance by providing faster read and write capabilities. Combined with intelligent load balancing, these features allow hyper-converged systems to deliver consistent performance even under heavy workloads.
Despite these advantages, the evolution toward hyper-converged infrastructure also introduces new considerations. Network performance within clusters becomes critical because all storage and compute communication occurs over shared infrastructure. Ensuring sufficient bandwidth and low latency is essential for maintaining system stability and application responsiveness. Additionally, while management is simplified, the underlying architecture is still complex, requiring careful design to ensure optimal performance and scalability.
Looking at the broader evolution, a clear pattern emerges. Each generation of storage systems moves toward greater abstraction, automation, and integration. Direct-attached storage represented physical simplicity but lacked scalability. Centralised storage introduced sharing and control, but added network dependency. Converged infrastructure improved deployment efficiency but maintained architectural separation. Hyper-converged infrastructure finally unifies these layers into a software-defined system that aligns with modern cloud computing principles.
This progression reflects a deeper trend in enterprise computing: the shift from hardware-defined systems to software-defined infrastructure. As data continues to grow and workloads become more distributed, organisations increasingly rely on software to manage complexity, optimise performance, and ensure scalability. Storage is no longer just a physical resource; it is now an intelligent, distributed service that adapts dynamically to application needs.
The future of storage systems is likely to continue along this path. Emerging technologies such as edge computing, artificial intelligence workloads, and globally distributed applications will require even more flexible and decentralised storage architectures. Systems will need to operate closer to data sources, process information in real time, and integrate seamlessly across hybrid environments that span on-premises infrastructure and cloud platforms.
Ultimately, the evolution of storage systems is not just a technical progression but a reflection of how modern computing has changed. Data has become the central driver of digital systems, and storage architectures have evolved to keep pace with this reality. From isolated disks inside servers to fully integrated, software-defined clusters, each stage has contributed to building the scalable, resilient, and intelligent infrastructure that powers today’s digital world.