Containerization has fundamentally reshaped how software is built, shipped, and run across infrastructure. Instead of treating applications as tightly bound to a specific server or operating system environment, containerization packages everything an application needs—code, runtime, system tools, libraries, and dependencies—into a single lightweight unit called a container.
This approach eliminates one of the most persistent problems in traditional software deployment: environment inconsistency. In earlier architectures, applications often behaved differently across development, testing, and production environments due to subtle differences in configuration or installed dependencies. Containerization resolves this by ensuring that the application runs identically regardless of where it is deployed.
Containers achieve this through operating system-level virtualization. Unlike virtual machines, which include a full guest operating system, containers share the host OS kernel while remaining isolated from one another. This makes them significantly more efficient in terms of memory usage, startup time, and overall resource consumption.
Because of this efficiency, organizations can run a high density of containers on a single physical or virtual machine. This leads to better resource utilization and lower infrastructure costs. However, this increased density also introduces new operational challenges, particularly around coordination, scaling, and reliability.
As applications evolved into distributed microservices architectures, the number of containers required to support production systems increased dramatically. Managing these containers manually quickly became impractical. This is where orchestration platforms emerged as a critical layer in modern infrastructure.
Container orchestration is the automated management of container lifecycles. It involves scheduling containers onto machines, ensuring high availability, handling failures, managing networking, and scaling workloads based on demand. Without orchestration, maintaining modern distributed systems would require excessive manual effort and would be prone to errors.
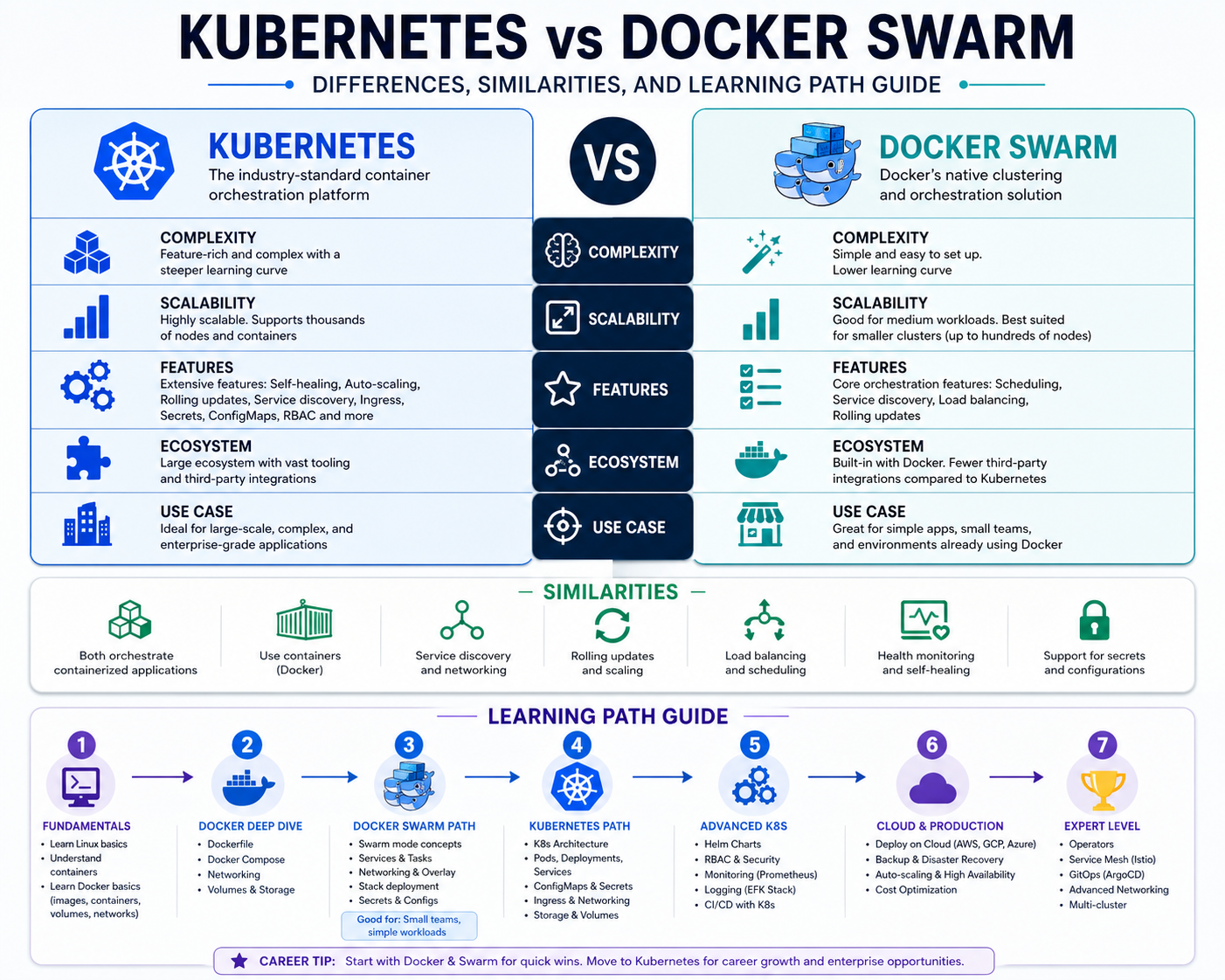
Two dominant technologies emerged to solve this problem: Kubernetes and Docker Swarm. Both aim to simplify container orchestration, but they differ significantly in design philosophy, complexity, and scalability.
The Rise of Orchestration in Cloud-Native Architecture
As organizations shifted toward cloud-native development, application architectures became more distributed and dynamic. Instead of monolithic applications running on a single server, systems evolved into collections of loosely coupled services that communicate over networks.
This shift introduced several operational challenges. Services needed to scale independently, recover from failures automatically, and maintain consistent communication across distributed environments. Traditional deployment methods were not designed to handle this level of complexity.
Orchestration platforms were introduced to address these challenges. They act as control systems that continuously monitor the state of applications and infrastructure, making adjustments as needed to maintain stability and performance.
At a high level, orchestration systems perform several key functions. They decide where containers should run, monitor their health, restart failed instances, distribute traffic, and ensure that applications meet predefined operational requirements.
These requirements are typically defined as a desired state. The system continuously compares the current state of the infrastructure with the desired state and takes corrective action whenever discrepancies are detected.
This model represents a shift from imperative management, where administrators manually issue commands, to declarative management, where users define what they want, and the system determines how to achieve it.
Kubernetes and Docker Swarm both implement this concept of desired state management, but they do so in different ways and with different levels of complexity and control.
What Kubernetes Is and Why It Became the Industry Standard
Kubernetes is an open-source container orchestration platform originally developed to manage large-scale distributed systems. It was designed to automate the deployment, scaling, and operations of application containers across clusters of machines.
Its architecture is built around a cluster model. A cluster consists of a control plane and multiple worker nodes. The control plane is responsible for managing the overall state of the system, while worker nodes run the actual application workloads.
The control plane includes several key components that work together. The API server acts as the central interface for communication. The scheduler determines where workloads should be placed based on resource availability and constraints. Controller components continuously monitor the system to ensure that the desired state is maintained.
Worker nodes contain the container runtime, which is responsible for running containers. They also include agents that communicate with the control plane and report status information.
At the core of Kubernetes is the concept of a pod. A pod is the smallest deployable unit in the system and can contain one or more containers. Containers within a pod share networking and storage resources, allowing them to operate closely together.
Pods are designed to be ephemeral. If a pod fails, it is not restarted. Instead, Kubernetes creates a new pod to replace it. This approach aligns with the philosophy of treating infrastructure as disposable rather than persistent.
To manage scaling and reliability, Kubernetes uses higher-level abstractions such as replica sets and deployments. A replica set ensures that a specified number of identical pods are always running. If a pod fails, the replica set automatically creates a replacement.
Deployments build on replica sets by adding support for versioned updates. They allow applications to be updated incrementally, enabling rolling updates and rollbacks in case of failures.
This mechanism ensures that applications remain highly available even during updates or infrastructure disruptions.
The Declarative Model and Desired State Management in Kubernetes
One of the most powerful concepts in Kubernetes is its declarative configuration model. Instead of manually instructing the system to perform each action, users define the desired state of the system using configuration files.
These configuration files typically describe how many replicas of an application should run, what resources they require, how they should be exposed to network traffic, and what policies should govern their behavior.
Once the desired state is defined, Kubernetes continuously works to ensure that the actual state of the system matches it. This process is known as reconciliation.
For example, if a configuration specifies that five replicas of a service should be running, Kubernetes will constantly monitor the system. If one replica fails, the system will automatically create a new one to replace it. If additional replicas are added or removed manually, Kubernetes will correct the discrepancy.
This self-healing capability is one of the reasons Kubernetes is widely adopted in production environments. It reduces the need for manual intervention and improves system resilience.
However, this level of automation also introduces complexity. Understanding how different components interact requires knowledge of multiple layers of abstraction, including pods, nodes, services, controllers, and networking layers.
Networking, Services, and Communication in Kubernetes
Networking in Kubernetes is designed to provide seamless communication between distributed components. Each pod receives its own IP address, allowing containers to communicate directly with one another without requiring complex port mapping.
Services act as stable endpoints for accessing groups of pods. Since pods can be created and destroyed dynamically, their IP addresses are not reliable for long-term communication. Services solve this by providing a consistent interface that automatically routes traffic to healthy pods.
There are different types of services, each designed for specific use cases. Some expose applications internally within the cluster, while others allow external access from outside the system.
Load balancing is integrated into the service layer, distributing traffic evenly across available pods. This ensures that no single instance becomes overwhelmed and helps maintain performance under varying loads.
Kubernetes also supports advanced networking configurations, including network policies that control traffic flow between pods. These policies enable fine-grained security controls within the cluster.
Storage Abstraction and Data Persistence in Kubernetes
While containers are inherently ephemeral, many applications require persistent storage. Kubernetes addresses this challenge through a flexible storage abstraction system.
Persistent volumes represent storage resources that exist independently of the lifecycle of individual pods. These volumes can be dynamically provisioned and attached to pods as needed.
This separation between compute and storage allows applications to maintain data even when containers are restarted or rescheduled across nodes.
Storage classes define different types of storage with varying performance characteristics. This allows administrators to optimize storage usage based on application requirements.
Persistent volume claims are used by applications to request storage resources without needing to know the underlying infrastructure details.
This abstraction simplifies storage management while maintaining flexibility and scalability.
Complexity and Operational Overhead in Kubernetes Environments
Despite its powerful capabilities, Kubernetes introduces a significant level of operational complexity. The system consists of many interconnected components, each requiring proper configuration and management.
Setting up a Kubernetes cluster involves configuring networking, authentication, storage, scheduling policies, and monitoring systems. Even small misconfigurations can lead to system instability or performance issues.
Debugging issues in Kubernetes environments can also be challenging. Because applications are distributed across multiple nodes and containers, identifying the root cause of a problem often requires analyzing logs from multiple sources.
Additionally, the learning curve for Kubernetes is steep. Understanding its architecture requires familiarity with distributed systems, networking concepts, and container lifecycle management.
However, this complexity is often justified in large-scale environments where flexibility, scalability, and resilience are critical requirements.
Introduction to Docker Swarm as a Simpler Alternative
Docker Swarm represents a different approach to container orchestration, focusing on simplicity and tight integration with the Docker ecosystem. Unlike Kubernetes, which operates as a separate platform, Swarm is built directly into Docker and can be managed using familiar Docker commands.
A Swarm cluster consists of multiple nodes, which can be classified as managers or workers. Manager nodes are responsible for orchestration decisions, while worker nodes execute application workloads.
Services are the primary abstraction in Swarm. A service defines how many container instances should run and how they should behave. Swarm ensures that the desired number of instances is always maintained.
One of the key advantages of Swarm is its simplicity. Setting up a cluster requires minimal configuration, making it accessible to users who may not have deep experience with distributed systems.
Swarm also includes built-in load balancing and service discovery, allowing containers to communicate easily within the cluster.
Unlike Kubernetes, Swarm does not require users to learn a new command-line interface. It integrates directly with Docker CLI commands, reducing the learning curve significantly.
Core Architecture and Operational Model of Docker Swarm
Docker Swarm operates using a manager-worker architecture. Manager nodes handle orchestration tasks such as scheduling and maintaining the desired state, while worker nodes execute containers.
When a service is deployed, Swarm automatically distributes containers across available nodes based on resource availability. If a node fails, Swarm redistributes workloads to maintain availability.
This ensures a level of fault tolerance without requiring complex configuration.
Swarm also supports rolling updates, allowing services to be updated gradually without downtime. If an update fails, the system can revert to a previous stable state.
Networking in Swarm is designed to be straightforward. It uses an overlay network that allows containers across different nodes to communicate as if they were on the same machine.
Security features are built into the system, including encrypted communication between nodes and automatic certificate management.
Where Docker Swarm Fits in Modern Infrastructure
Docker Swarm is particularly well-suited for smaller applications or environments where simplicity is a priority. Its lightweight architecture makes it easy to deploy and manage without requiring extensive operational expertise.
For development environments, testing setups, or small production systems, Swarm provides sufficient orchestration capabilities without the overhead of more complex platforms.
However, its simplicity also limits its flexibility. It lacks many of the advanced features found in more sophisticated orchestration systems, particularly in areas such as fine-grained scaling, advanced networking policies, and extensibility.
As applications grow in complexity, these limitations may become more significant, influencing the choice of orchestration platform based on long-term requirements.
Kubernetes Architecture Deep Dive: Control Plane, Nodes, and Cluster Intelligence
Kubernetes is fundamentally a distributed system designed to coordinate workloads across multiple machines with high reliability. Its architecture is intentionally modular, allowing each component to perform a specialized role while contributing to a unified orchestration system.
At the center of Kubernetes is the control plane, which acts as the decision-making layer. It does not run application workloads directly; instead, it manages the entire lifecycle of workloads running across worker nodes. The control plane continuously evaluates the state of the cluster and ensures alignment with the declared desired state.
The control plane is composed of several tightly integrated services. The API server functions as the entry point for all operations. Every request—whether from a user, automation script, or internal component—passes through this interface. It validates requests, processes them, and updates the cluster state stored in a persistent backend.
The scheduler is responsible for assigning workloads to worker nodes. It evaluates available resources, node conditions, affinity rules, and constraints before making placement decisions. This ensures that workloads are distributed efficiently and that no single node becomes overloaded.
Controller managers operate continuously in loops, reconciling actual system state with desired state definitions. Each controller is responsible for a specific domain, such as node health, replication, or endpoint management. If discrepancies are detected, controllers take corrective action automatically.
Worker nodes form the execution layer of Kubernetes. Each node runs a container runtime, such as containerd, which is responsible for pulling images and running containers. Nodes also run a kubelet agent, which communicates with the control plane and ensures that assigned workloads are running correctly.
Networking components on each node handle communication between pods, services, and external systems. Kubernetes relies on a flat networking model where every pod receives its own IP address, eliminating the need for NAT within the cluster.
This architecture allows Kubernetes to scale horizontally across large infrastructures. However, the complexity of coordinating these components introduces significant operational overhead, especially in large environments.
Pods, Replica Sets, and Deployments: The Execution Layer of Kubernetes
The smallest operational unit in Kubernetes is the pod. A pod represents one or more containers that share the same network namespace and storage resources. This design allows tightly coupled application components to run together efficiently.
Pods are not designed to be permanent entities. Instead, they are treated as ephemeral workloads. If a pod fails or becomes unhealthy, it is terminated and replaced by a new instance. This stateless approach aligns with modern cloud-native principles.
Replica sets are responsible for maintaining a consistent number of pod replicas. They ensure that a specified number of identical pods are always running. If a pod is deleted or crashes, the replica set automatically creates a replacement.
This mechanism provides resilience and fault tolerance at the application level. It ensures that services remain available even if individual components fail.
Deployments build on replica sets by adding version control and update management capabilities. They allow applications to be updated incrementally using rolling updates. This means new versions of an application are gradually introduced while old versions are phased out.
If a deployment fails or introduces instability, Kubernetes can roll back to a previous version. This rollback capability provides operational safety in production environments.
These abstractions form the execution layer of Kubernetes, enabling it to manage complex applications without requiring manual intervention for every change.
Kubernetes Networking Model and Service Discovery Mechanisms
Networking in Kubernetes is one of its most powerful yet complex components. Unlike traditional infrastructure, where network communication is tightly controlled by physical or virtual network configurations, Kubernetes abstracts networking at the application layer.
Each pod receives a unique IP address. This design ensures that pods can communicate directly with each other across nodes without requiring port mapping or address translation. This flat networking model simplifies service-to-service communication.
However, because pods are ephemeral and can be created or destroyed at any time, their IP addresses are not stable. To solve this issue, Kubernetes introduces the concept of services.
A service acts as a stable network endpoint that abstracts a group of pods. Instead of connecting directly to a pod, applications connect to a service, which then routes traffic to healthy backend pods.
This abstraction decouples service consumers from service providers. Even if underlying pods change, the service endpoint remains consistent.
Kubernetes supports different types of services. ClusterIP services are used for internal communication within the cluster. NodePort services expose applications on specific ports across nodes. LoadBalancer services integrate with external load balancers to provide internet-facing access.
Service discovery is handled automatically through internal DNS systems. Applications can reference services by name rather than IP address, simplifying configuration and reducing operational complexity.
Network policies provide additional control over traffic flow. They define rules for which pods can communicate with each other, enabling segmentation and security enforcement within the cluster.
This combination of service abstraction and policy enforcement creates a highly flexible networking environment, but it also requires careful planning to avoid misconfigurations.
Storage Management and Persistent Data Handling in Kubernetes
While containers are inherently stateless, most real-world applications require persistent storage. Kubernetes addresses this requirement through a layered storage abstraction model.
Persistent volumes represent physical or virtual storage resources that exist independently of pods. These volumes are provisioned either statically or dynamically based on demand.
Persistent volume claims act as requests for storage resources. Applications declare their storage needs using these claims, and Kubernetes binds them to appropriate volumes based on availability and configuration.
This separation between storage definition and consumption allows for greater flexibility. Applications do not need to know the underlying storage infrastructure, making them more portable across environments.
Storage classes define different types of storage with varying performance and cost characteristics. For example, high-performance storage may be used for databases, while slower storage may be used for archival purposes.
This abstraction enables dynamic provisioning, where storage is automatically created when needed. It reduces manual intervention and simplifies infrastructure management.
Data persistence is maintained even when pods are deleted or rescheduled. This ensures that applications can recover from failures without data loss.
However, storage management in Kubernetes requires careful configuration. Incorrect setups can lead to data inconsistency, performance degradation, or resource inefficiencies.
Security Architecture and Access Control in Kubernetes
Security in Kubernetes is implemented through multiple layers, including authentication, authorization, and network-level controls.
Authentication determines who can access the cluster. This can include users, service accounts, or external identity providers. Kubernetes supports multiple authentication methods, including certificates, tokens, and integration with external identity systems.
Authorization controls what authenticated users can do. Role-based access control is commonly used to define permissions at a granular level. Roles define specific actions, while role bindings assign those roles to users or service accounts.
This model allows organizations to enforce least privilege access, ensuring that components only have the permissions they need to function.
Secrets management is another critical aspect of security. Sensitive information such as passwords, tokens, and keys can be stored securely within the cluster. These secrets are encrypted and can be mounted into pods as needed.
Network policies add another layer of protection by controlling communication between pods. They ensure that only authorized traffic is allowed within the cluster.
Despite these built-in mechanisms, Kubernetes security requires careful configuration and ongoing monitoring. Misconfigured permissions or exposed services can lead to vulnerabilities.
Operational Complexity and Real-World Challenges in Kubernetes
Kubernetes is powerful, but its complexity introduces operational challenges that must be carefully managed. One of the primary challenges is the learning curve associated with its architecture.
Understanding how components such as pods, services, controllers, and nodes interact requires a deep understanding of distributed systems principles. This complexity can slow down onboarding and increase the risk of misconfiguration.
Debugging issues in Kubernetes environments can also be difficult. Because applications are distributed across multiple nodes, logs and metrics are scattered across different layers of the system. Diagnosing failures often requires correlating information from multiple sources.
Resource management is another challenge. Improper configuration of CPU and memory limits can lead to resource contention or underutilization. Without careful tuning, clusters may become inefficient or unstable.
Networking issues can also be complex. Misconfigured services or network policies can result in connectivity failures that are difficult to trace.
Despite these challenges, Kubernetes remains widely adopted due to its ability to handle large-scale, mission-critical workloads. Its complexity is often justified in environments where reliability, scalability, and flexibility are essential.
Docker Swarm Architecture and Simplicity-Driven Design Philosophy
Docker Swarm takes a fundamentally different approach to orchestration by prioritizing simplicity and tight integration with the Docker ecosystem. Instead of introducing a separate management system, Swarm extends Docker’s native capabilities.
A Swarm cluster is composed of multiple nodes that can be designated as either managers or workers. Manager nodes are responsible for orchestration decisions, while worker nodes execute container workloads.
This architecture reduces complexity by minimizing the number of moving parts. Unlike Kubernetes, which requires multiple control plane components, Swarm consolidates orchestration into a more streamlined system.
Services are the primary abstraction in Swarm. A service defines how many container replicas should run and how they should behave. Swarm ensures that the desired number of replicas is always maintained.
If a container fails, Swarm automatically replaces it to maintain service availability. This self-healing behavior is similar to Kubernetes but implemented more simply.
Swarm also handles scheduling automatically. It distributes containers across nodes based on resource availability and constraints. While less sophisticated than Kubernetes scheduling, it is sufficient for many use cases.
Networking is handled through overlay networks, which allow containers on different nodes to communicate as if they were on the same host. This simplifies cross-node communication significantly.
Swarm includes built-in load balancing and service discovery. Containers can locate and communicate with each other without requiring external configuration.
Security is integrated into the system through mutual TLS encryption between nodes. This ensures that communication within the cluster remains secure by default.
Service Management and Scaling Behavior in Docker Swarm
In Docker Swarm, scaling applications is a straightforward process. Users simply adjust the number of replicas defined in a service configuration, and Swarm automatically adjusts the cluster state.
This simplicity makes Swarm highly accessible for teams that do not require advanced orchestration capabilities. There is no need to define complex deployment strategies or manage multiple layers of abstraction.
Rolling updates are supported, allowing services to be updated incrementally. If an update fails, Swarm can revert to a previous version, ensuring stability.
Unlike Kubernetes, Swarm does not introduce a large number of abstractions. This reduces cognitive overhead and makes system behavior easier to predict.
However, this simplicity also limits flexibility. Swarm does not offer advanced scheduling policies, extensive extensibility, or fine-grained control over networking and storage.
Despite these limitations, Swarm remains useful in environments where operational simplicity is more important than advanced orchestration features.
Kubernetes vs Docker Swarm: Architectural Differences That Shape Real-World Decisions
When comparing Kubernetes and Docker Swarm, the most important distinction is not feature count but architectural philosophy. Kubernetes is built as a full distributed systems control platform, while Docker Swarm is designed as a lightweight extension of the Docker engine that enables basic orchestration with minimal operational overhead.
Kubernetes relies on a multi-component control plane that coordinates scheduling, state reconciliation, and system health across a cluster. This architecture is intentionally modular, allowing each component to scale independently. However, this modularity introduces operational complexity, as each service must be configured, secured, and maintained.
Docker Swarm, by contrast, consolidates orchestration responsibilities into a simpler manager-worker model. Manager nodes handle scheduling and state management, while worker nodes execute containers. This reduces system complexity but also limits extensibility and fine-grained control.
In Kubernetes, the separation between control plane and worker nodes is strict and highly structured. The control plane includes multiple services that communicate continuously to maintain system state consistency. In Swarm, orchestration logic is embedded more directly into the Docker ecosystem, reducing abstraction layers.
This difference in architecture directly impacts how each system behaves under load, how it scales, and how it is operated in production environments.
Kubernetes is designed for environments where scale, resilience, and flexibility are primary requirements. Swarm is designed for environments where simplicity, speed of deployment, and ease of management are more important than advanced control mechanisms.
Scheduling, Resource Allocation, and Workload Distribution
Scheduling is one of the most critical functions in any orchestration system. It determines how workloads are distributed across available infrastructure.
Kubernetes uses a sophisticated scheduler that evaluates multiple factors before placing a pod on a node. These factors include CPU and memory availability, node affinity rules, taints and tolerations, and custom scheduling policies.
This allows Kubernetes to make highly optimized placement decisions. Workloads can be distributed not only based on resource availability but also based on topology, performance requirements, and business logic constraints.
For example, workloads can be restricted to specific geographic regions, hardware types, or isolated environments. This level of control is essential in large-scale enterprise systems.
Docker Swarm uses a simpler scheduling mechanism. It primarily considers resource availability and node constraints when placing containers. While this approach is efficient for smaller systems, it lacks the advanced decision-making capabilities of Kubernetes.
Swarm does not provide the same level of customization for workload placement. There are fewer scheduling policies, and decisions are generally more deterministic and less configurable.
In practice, this means Kubernetes is better suited for heterogeneous environments where workloads have different requirements, while Swarm is more suited for homogeneous environments where workloads are relatively uniform.
Scaling Models and Elasticity Behavior in Both Systems
Scaling is a core function of container orchestration. It determines how systems respond to changes in demand.
Kubernetes supports both manual and automatic scaling. Horizontal Pod Autoscalers can adjust the number of running pods based on metrics such as CPU usage, memory consumption, or custom application metrics.
This enables dynamic elasticity, where applications scale up during peak demand and scale down during low usage periods. This helps optimize resource utilization and reduce operational costs.
Cluster autoscaling extends this concept further by adding or removing nodes based on workload demands. This ensures that the underlying infrastructure adapts dynamically to application needs.
Docker Swarm supports manual scaling through service configuration. Users can specify the number of replicas for a service, and Swarm ensures that this number is maintained.
While Swarm does support scaling operations, it does not offer the same level of automation or metric-driven scaling as Kubernetes. Scaling decisions are typically static or manually adjusted.
This difference reflects the broader design philosophy of each system. Kubernetes is designed for dynamic, self-adjusting environments, while Swarm prioritizes simplicity and predictability.
Fault Tolerance and System Recovery Mechanisms
Fault tolerance is a critical requirement for distributed systems. Both Kubernetes and Docker Swarm provide mechanisms to handle failures, but they differ in sophistication and implementation.
Kubernetes continuously monitors the health of pods, nodes, and services. If a pod fails, it is automatically replaced. If a node becomes unreachable, workloads are rescheduled to healthy nodes.
This self-healing behavior is driven by controllers that constantly reconcile actual system state with desired state definitions. This ensures that the system remains stable even in the presence of failures.
Kubernetes also supports advanced disruption handling mechanisms, such as pod disruption budgets. These allow administrators to define how many instances of a service can be unavailable during maintenance or scaling events.
Docker Swarm also provides fault tolerance through automatic rescheduling of failed containers. If a node goes offline, Swarm redistributes workloads to remaining nodes.
However, Swarm’s recovery mechanisms are less granular compared to Kubernetes. It focuses on maintaining service availability rather than enforcing detailed operational constraints.
In smaller environments, this simpler approach is often sufficient. In larger, more complex environments, Kubernetes provides stronger guarantees and more control over failure scenarios.
Networking Complexity and Communication Models
Networking is one of the most significant differences between Kubernetes and Docker Swarm.
Kubernetes uses a flat networking model where every pod receives its own IP address. This eliminates the need for port mapping and simplifies inter-pod communication. However, it requires a robust underlying networking implementation, often provided by external plugins.
Service discovery in Kubernetes is DNS-based, allowing services to be accessed using stable names. This abstraction decouples applications from underlying infrastructure changes.
Network policies allow fine-grained control over traffic flow between pods. This enables segmentation, isolation, and security enforcement within the cluster.
Docker Swarm uses overlay networks to connect containers across nodes. This allows containers to communicate as if they are on the same local network.
Service discovery in Swarm is integrated into the platform and relies on internal DNS resolution. Containers can reference services by name, and Swarm handles routing automatically.
While Swarm networking is simpler to configure, it offers fewer advanced features compared to Kubernetes. Kubernetes provides more flexibility but requires a deeper understanding and configuration effort.
Storage Systems and Data Persistence Strategies
Storage management in Kubernetes is highly abstracted and flexible. It supports dynamic provisioning of storage resources, allowing applications to request storage without knowing the underlying infrastructure.
Persistent volumes and persistent volume claims form the foundation of this system. Volumes represent physical or virtual storage resources, while claims represent application requests for storage.
Storage classes define different performance tiers, enabling workloads to select appropriate storage types based on requirements.
This abstraction enables portability across environments and simplifies infrastructure management.
Docker Swarm, on the other hand, relies on external storage solutions. It does not provide a built-in persistent storage abstraction layer equivalent to Kubernetes.
This means storage management in Swarm is often handled at the infrastructure or application level rather than through the orchestration system itself.
As a result, Kubernetes provides a more integrated and flexible approach to data persistence, especially in large-scale distributed systems.
Security Models and Access Control Mechanisms
Security is a multi-layered concern in both Kubernetes and Docker Swarm, but the approaches differ significantly.
Kubernetes implements a comprehensive security framework that includes authentication, authorization, and admission control.
Authentication determines who can access the cluster. Authorization controls what actions they can perform. Role-based access control allows fine-grained permission assignment.
Secrets management enables secure storage of sensitive information such as passwords and API keys. These secrets can be injected into containers at runtime.
Network policies provide additional security by controlling communication between pods.
Docker Swarm uses a simpler security model. It relies heavily on mutual TLS encryption between nodes to secure communication.
Access control is more limited compared to Kubernetes, and configuration is generally simpler.
While Swarm provides adequate security for many use cases, Kubernetes offers more granular control and enterprise-grade security features.
Operational Overhead and Learning Curve Comparison
One of the most important practical differences between Kubernetes and Docker Swarm is operational complexity.
Kubernetes has a steep learning curve due to its large number of components and abstractions. Understanding how the system works requires knowledge of distributed systems, networking, storage, and automation principles.
Operational tasks such as debugging, scaling, and configuration management can be complex. Logs and metrics are distributed across multiple components, making troubleshooting more involved.
However, this complexity enables Kubernetes to handle highly complex and large-scale systems.
Docker Swarm is significantly easier to learn and operate. Its integration with Docker CLI reduces the need for additional tooling or command sets.
Cluster setup is straightforward, and day-to-day operations are simpler. This makes Swarm attractive for smaller teams or projects with limited operational requirements.
The trade-off is reduced flexibility and scalability compared to Kubernetes.
Performance Considerations and System Efficiency
Performance characteristics differ between Kubernetes and Docker Swarm due to architectural differences.
Kubernetes introduces more overhead due to its multi-component control plane and extensive feature set. However, this overhead is typically negligible in large-scale environments where its capabilities are fully utilized.
Swarm has lower overhead and faster setup times, making it more efficient in smaller environments.
In terms of raw container performance, both systems rely on the underlying container runtime and host infrastructure. Therefore, differences in performance are primarily related to orchestration overhead rather than container execution itself.
Ecosystem Maturity and Industry Adoption Trends
Kubernetes has become the dominant orchestration platform in modern cloud-native ecosystems. It is widely supported across cloud providers, infrastructure tools, and third-party integrations.
Its ecosystem includes tools for monitoring, logging, security, networking, and automation. This extensive ecosystem makes it highly extensible and adaptable to diverse environments.
Docker Swarm has a smaller ecosystem and is less widely adopted in large-scale enterprise environments. While it remains supported and functional, its development momentum and community adoption are more limited compared to Kubernetes.
This difference in ecosystem maturity influences long-term adoption decisions, especially for organizations planning large-scale or evolving infrastructure.
Decision Factors for Choosing Between Kubernetes and Docker Swarm
Choosing between Kubernetes and Docker Swarm depends on multiple technical and operational factors.
System scale is one of the most important considerations. Kubernetes is better suited for large-scale distributed systems with complex requirements. Swarm is better suited for smaller applications or simpler environments.
Operational expertise is another key factor. Kubernetes requires specialized knowledge and training, while Swarm can be managed with basic Docker experience.
Flexibility and extensibility are critical in complex environments. Kubernetes provides extensive customization options, while Swarm prioritizes simplicity.
Infrastructure complexity also plays a role. Kubernetes is ideal for multi-cluster, multi-cloud, or hybrid environments. Swarm is better suited for single-cluster or small-scale deployments.
Long-term scalability requirements often determine the final choice. Kubernetes provides a more future-proof architecture for growing systems, while Swarm is more suitable for stable, smaller-scale workloads.
Evolving Role of Orchestration in Modern Infrastructure
As cloud-native technologies continue to evolve, orchestration platforms are becoming more central to infrastructure design.
Kubernetes has positioned itself as the foundational layer for modern distributed systems, enabling advanced automation, scalability, and resilience.
Docker Swarm continues to serve a niche role in simpler environments where ease of use is prioritized over advanced functionality.
Both systems reflect different approaches to solving the same fundamental problem: managing containers at scale efficiently and reliably.
The choice between them is ultimately shaped by system complexity, operational requirements, and long-term architectural goals.
Conclusion
Container orchestration has become a defining element of modern infrastructure design, and both Kubernetes and Docker Swarm emerged to solve the same core problem from very different perspectives. At the center of this comparison is not simply a feature checklist, but a deeper question of architectural philosophy, operational tolerance for complexity, and long-term scalability expectations.
Kubernetes represents an industrial-strength approach to distributed systems management. It was designed for environments where applications are no longer single processes running on a single machine, but instead collections of loosely coupled services spread across clusters, regions, and sometimes even multiple cloud providers. Its architecture reflects this reality. Every component exists to enforce consistency, resilience, and predictability in systems that are inherently unpredictable due to their distributed nature.
The power of Kubernetes lies in its declarative model. Instead of instructing the system step by step, operators define what the system should look like, and Kubernetes continuously works to ensure reality matches that definition. This creates a self-healing environment where failures are not just expected but automatically corrected. Pods are replaced, workloads are rescheduled, and services are rebalanced without manual intervention. Over time, this reduces operational risk in large environments, where manual recovery would be too slow or too error-prone.
However, this capability does not come without cost. Kubernetes introduces a significant learning curve, and its complexity is not superficial. It is structural. Understanding how control planes, schedulers, controllers, networking layers, and storage abstractions interact requires a shift in thinking from traditional system administration to distributed systems engineering. Misconfiguration does not simply lead to inefficiency; it can lead to cascading failures that are difficult to diagnose.
Despite this complexity, Kubernetes has become the dominant standard in enterprise and cloud-native ecosystems because it scales with organizational ambition. As systems grow from tens to thousands of services, and from single clusters to multi-region deployments, Kubernetes provides the abstraction layer necessary to manage that growth without collapsing under operational overhead. It is not optimized for simplicity; it is optimized for survivability at scale.
Docker Swarm exists at the opposite end of this design spectrum. It prioritizes accessibility, speed of deployment, and operational clarity. It integrates directly into the Docker ecosystem, allowing users to transition from container management to orchestration without learning an entirely new conceptual framework. This makes it highly attractive for small teams, simpler applications, and environments where infrastructure complexity is intentionally minimized.
Swarm’s architecture reflects this philosophy. Instead of multiple interacting control plane components, it relies on a more unified manager-worker model. Services are defined, replicated, and maintained with relatively straightforward configuration. The system ensures the desired state with less overhead and fewer moving parts. As a result, Swarm is easier to deploy, easier to understand, and easier to maintain in constrained environments.
However, this simplicity also defines its limits. Swarm does not provide the same depth of control over scheduling, networking policies, or extensibility. It lacks the ecosystem breadth that Kubernetes has developed over time, and it does not scale operationally in the same way when systems become highly distributed or highly dynamic. While it performs reliably within its intended scope, that scope is narrower.
The comparison between Kubernetes and Docker Swarm is therefore not about superiority in absolute terms, but suitability for context. Kubernetes excels in environments where infrastructure is complex, workloads are diverse, and long-term scalability is a requirement rather than an option. Docker Swarm excels in environments where operational simplicity is more valuable than architectural flexibility, and where teams prefer minimal cognitive overhead.
This distinction becomes particularly important when considering organizational maturity. Teams with strong DevOps practices, infrastructure automation experience, and distributed systems knowledge are more likely to benefit from Kubernetes, as they can leverage its full feature set without being overwhelmed by its complexity. On the other hand, smaller teams or organizations in earlier stages of cloud adoption may find Kubernetes unnecessarily heavy, making Swarm a more practical starting point.
Another important factor is ecosystem evolution. Kubernetes has become deeply integrated into modern cloud ecosystems, with extensive tooling for monitoring, logging, security, and deployment automation. This ecosystem effect reinforces its position as a default choice for large-scale systems. Docker Swarm, while stable and functional, has not seen the same level of ecosystem expansion, which limits its long-term strategic role in rapidly evolving infrastructure landscapes.
Performance considerations also play a role, but not in the way they are often assumed. The difference in raw container execution performance between Kubernetes and Swarm is minimal because both ultimately rely on the underlying container runtime and host operating system. The real difference lies in orchestration overhead, scheduling intelligence, and system adaptability under load. Kubernetes introduces more overhead but also provides significantly more control and resilience mechanisms. Swarm reduces overhead but also reduces the depth of control available to the operator.
Security models further highlight the philosophical divide. Kubernetes implements a multi-layered security architecture that includes authentication, authorization, network policies, and secrets management. This allows for fine-grained control over who can access what within a cluster. Swarm, while secure in its own right through mechanisms like TLS encryption between nodes, offers a simpler and less granular security model. This makes Kubernetes more suitable for regulated or high-security environments where access control precision is essential.
Ultimately, the decision between Kubernetes and Docker Swarm is not static. It evolves with the system it supports. A small application may begin its lifecycle comfortably within Swarm due to its simplicity and low operational cost. As that application grows, adds services, increases traffic, and requires more sophisticated deployment strategies, Kubernetes often becomes the natural migration path.
This evolutionary pattern reflects a broader truth in infrastructure design: tools are not just chosen based on current needs, but also based on anticipated complexity. Kubernetes prepares systems for scale that may not yet exist, while Swarm optimizes for present simplicity.
Both technologies remain relevant, but they serve different roles in the ecosystem. Kubernetes is the infrastructure backbone for large-scale distributed computing, while Docker Swarm functions as a streamlined orchestration layer for smaller or less complex environments. Understanding this distinction allows engineers and organizations to make decisions based not on popularity or trend, but on architectural fit and operational reality.