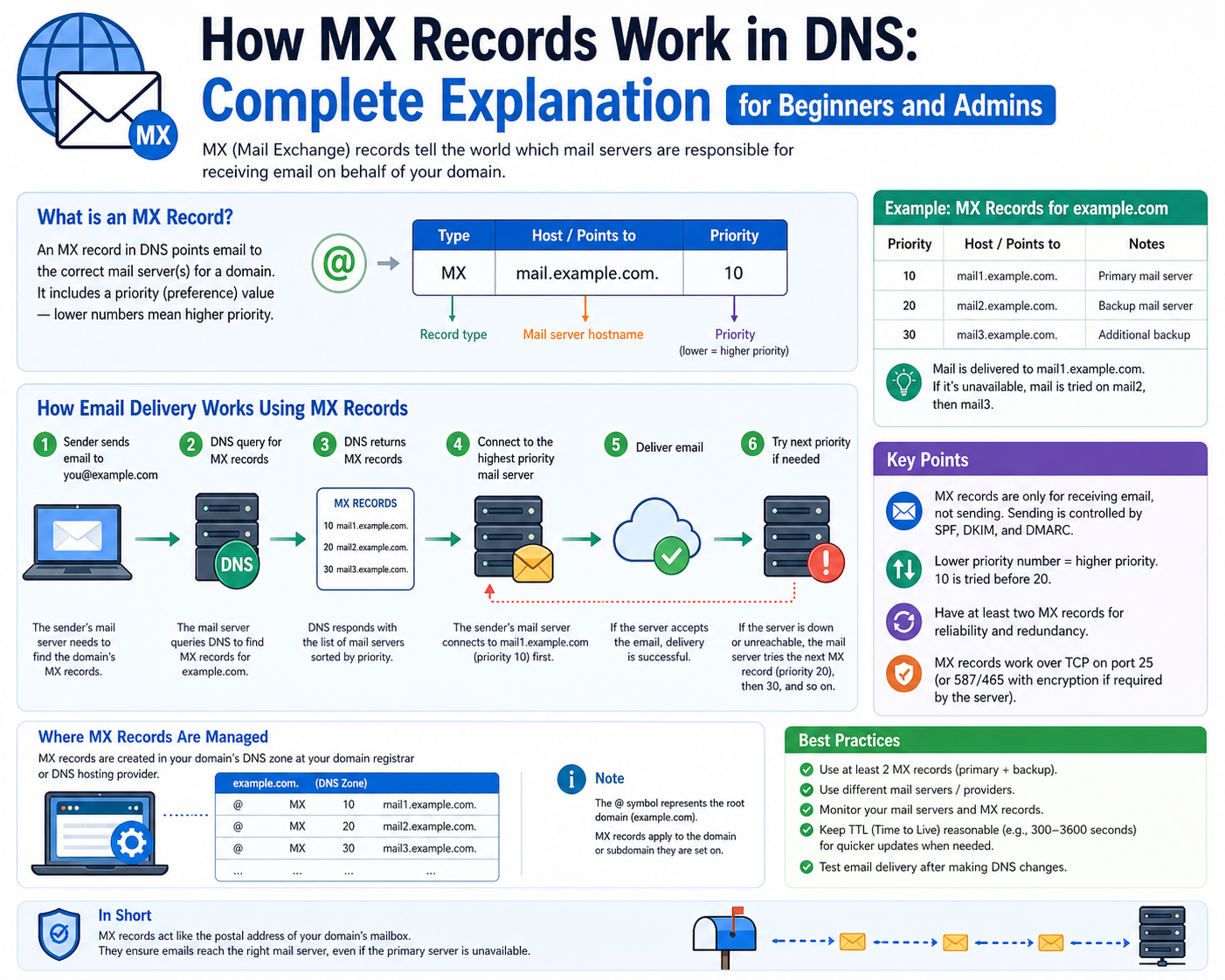
The internet relies on a distributed naming system that translates human-readable identifiers into machine-readable network addresses. This system is essential for both browsing and communication services. Among its many functions, one of the most critical is enabling email delivery through structured routing rules defined at the domain level. When an email is sent, it does not travel randomly across networks; instead, it follows a defined path governed by specific records stored in a hierarchical naming system. These records determine where messages should be directed and how mail servers should be contacted. Within this structure, mail exchange records serve as dedicated instructions that guide electronic messages to the correct destination servers responsible for handling incoming mail traffic. Unlike general web navigation records, which primarily resolve names to IP addresses for content access, mail routing records are specialized to support message transfer protocols. They ensure that communication systems can identify which servers are authorized to receive email for a given domain and in what order they should be contacted.
How Domain Resolution Initiates Communication Requests
When a user initiates any online request by entering a human-readable address into a browser or email client, the system first begins a resolution process. This process involves multiple layers of distributed lookup services designed to translate the requested name into a usable network location. The initial request is sent to a resolving service that acts as an intermediary between the user device and global naming infrastructure. This resolver communicates with high-level reference servers that provide directional guidance rather than final answers. These reference systems then guide the query toward more specific directories responsible for different segments of the naming hierarchy. Eventually, the request reaches the authoritative source responsible for the domain in question, which holds the definitive mapping information. At this stage, the system retrieves the required network address or service-specific routing instructions. For email communication, instead of returning a single direct address, the system may return multiple prioritized destinations. These destinations are defined through specialized records that identify mail-handling servers. The resolution process ensures that communication requests are not only directed correctly but also optimized based on predefined priority rules and redundancy configurations.
Role of Mail Exchange Records in Email Infrastructure
Mail exchange records are structured directives stored within domain-level configuration systems that specify which servers are responsible for handling incoming electronic messages. These records act as routing instructions that allow sending systems to identify where email traffic should be delivered. Each record contains a reference to a mail handling endpoint along with an associated priority value that determines the order in which servers should be contacted. Lower priority values indicate higher preference, meaning those servers are attempted first during delivery. This prioritization system allows administrators to define primary and backup mail handling paths. If the primary destination is unavailable, secondary or tertiary servers can take over without interruption to message delivery. This hierarchical structure is essential for maintaining continuity in communication systems, especially in environments where reliability is critical. Mail exchange records do not store the messages themselves; instead, they function as directional pointers that guide sending systems toward active mail processing infrastructure.
Structure and Components of Mail Routing Entries
Each mail routing entry consists of several key components that collectively define how email traffic should be handled. The first component is the domain reference, which identifies the organizational or system boundary for which the record applies. The second component is the destination server specification, which indicates the system responsible for receiving messages. This destination is typically represented in a format that can be resolved into a network address. The third component is the priority value, which determines the sequence in which multiple destinations are used. When multiple entries exist for a single domain, systems interpret the lowest numerical value as the primary route. Additional components may include time-based validity settings that control how long a resolver should cache the record before requesting updated information. This caching mechanism helps reduce unnecessary queries and improves overall system efficiency. Together, these elements create a structured framework that enables predictable and scalable email routing behavior across distributed systems.
Email Delivery Process Driven by Mail Routing Logic
When an email is sent from one system to another, the sending infrastructure initiates a lookup process to determine the correct destination for message delivery. This process begins with a query for mail routing information associated with the recipient’s domain. Once the relevant records are retrieved, the sending system evaluates the available destinations based on their priority values. The system then attempts to establish a connection with the highest priority mail handling server. If the connection is successful, the message is transmitted using a standardized transfer protocol designed specifically for email communication. The receiving server then validates the recipient information and determines whether the mailbox exists and is capable of accepting new messages. If validation is successful, the message is stored within the recipient’s mailbox environment. If the primary server is unreachable, the sending system automatically attempts secondary destinations based on priority order. This fallback mechanism ensures that email delivery is resilient and not dependent on a single point of failure.
Interaction Between Email Transfer Protocols and Routing Systems
Email delivery relies on a specialized communication protocol that governs how messages are transferred between servers. This protocol defines a structured sequence of commands that allows sending and receiving systems to exchange information reliably. When combined with mail routing records, the protocol ensures that messages are directed to the correct destination before transmission begins. The routing system provides the address, while the transfer protocol manages the actual delivery process. Together, they form a coordinated mechanism that ensures messages are not only routed correctly but also successfully delivered. The protocol operates through a handshake process that verifies server readiness before any message content is transmitted. Once a connection is established, message data is transferred in structured segments, ensuring integrity during transmission. The receiving system then acknowledges successful delivery or reports errors if issues arise. This integration between routing logic and transfer protocol ensures that email systems remain both efficient and reliable under varying network conditions.
Priority Handling and Load Distribution in Mail Routing Systems
One of the key features of mail routing architecture is the ability to distribute traffic based on priority values assigned to multiple destination servers. This system allows organizations to define primary and secondary processing paths for incoming messages. In cases where multiple servers share the same priority value, traffic can be distributed evenly among them, creating a form of load balancing. This approach helps prevent overload on a single server and improves overall system performance. When priority values differ, systems strictly follow the defined order, ensuring that higher-priority servers receive traffic first. If a higher-priority server becomes unavailable, the system automatically shifts to the next available option. This dynamic behavior ensures continuous service availability even during partial system failures. The combination of priority-based selection and fallback routing creates a flexible and resilient communication infrastructure capable of handling varying levels of demand.
Caching Behavior and Time-Controlled Record Updates
To improve efficiency, mail routing information is often cached by intermediary systems for a specified duration. This caching period is controlled by a time-based parameter that defines how long a record should be considered valid before it must be refreshed. During this period, systems use stored information rather than repeatedly querying authoritative sources. This reduces network overhead and speeds up communication processes. However, once the defined time period expires, systems are required to request updated routing information to ensure accuracy. This mechanism is particularly important in environments where mail server configurations change frequently. By controlling how long information is retained, administrators can balance performance optimization with data accuracy. Proper configuration of caching intervals is essential to ensure that email delivery remains both efficient and up to date with current infrastructure changes.
Security Considerations in Email Routing Environments
Email routing systems operate within a broader security framework designed to prevent unauthorized message delivery and domain impersonation. Several validation mechanisms are commonly used to enhance trust in email communication. One such mechanism defines which servers are authorized to send messages on behalf of a domain, helping to prevent spoofing attempts. Another mechanism applies digital signatures to outgoing messages, allowing receiving systems to verify authenticity. A further layer of protection defines how receiving systems should handle messages that fail authentication checks, including options such as acceptance, quarantine, or rejection. These security controls work alongside routing records to ensure that messages are not only delivered correctly but also validated for authenticity. Together, they form a multi-layered defense structure that strengthens the integrity of email communication systems and reduces the risk of fraudulent activity.
Email Transport Layers and Message Relay Architecture
Modern electronic communication systems rely on layered transport mechanisms that separate message creation from message delivery. Once a message is generated by a client application, it is handed off to a relay component responsible for initiating transmission toward external networks. This relay component does not deliver messages directly to end recipients but instead communicates with external mail handling systems using standardized transmission procedures. These procedures define how data packets are structured, acknowledged, and transferred across network boundaries. The relay system acts as an intermediary that ensures messages are properly formatted and queued before outbound delivery begins. In large-scale environments, multiple relay nodes may exist to distribute outgoing traffic efficiently and prevent congestion. These nodes work together to ensure consistent delivery behavior regardless of message volume or destination complexity. The separation between message generation and transport allows systems to remain modular, scalable, and adaptable to changing network conditions.
Role of Mail Servers in Receiving and Processing Messages
Mail handling servers are specialized systems designed to receive incoming electronic messages, validate them, and store them for user access. These servers operate continuously, listening for connection requests from external sending systems. When a message arrives, the server performs a series of validation checks to confirm that the recipient exists and is eligible to receive communication. If the recipient is valid, the message is placed into a structured storage environment associated with that user. This storage environment organizes messages in a way that allows efficient retrieval and management. Mail servers also handle message indexing, categorization, and filtering based on predefined rules. In enterprise environments, multiple mail servers may operate in parallel to distribute load and ensure continuous availability. These servers often synchronize with each other to maintain consistent mailbox states across the system. This synchronization ensures that users can access their messages from different devices without discrepancies in message history or status.
Routing Decision Logic and Server Selection Mechanisms
When a sending system retrieves routing information, it must apply decision logic to determine which destination server to contact first. This decision is based on structured priority values assigned to each available destination. The system begins by sorting available targets according to these values and then attempts connection starting with the highest priority entry. If the first attempt fails due to unavailability or network issues, the system proceeds to the next entry in the sequence. This iterative process continues until a successful connection is established or all options are exhausted. In environments with multiple equally prioritized destinations, the system may distribute connection attempts across all available servers to balance traffic. This approach improves resilience and reduces the risk of overload on any single endpoint. The decision logic is deterministic, ensuring consistent behavior across repeated delivery attempts. This structured selection process is essential for maintaining reliability in distributed communication environments where server availability may fluctuate.
Message Queuing and Deferred Delivery Handling
In some cases, immediate delivery of a message is not possible due to temporary network issues, server overload, or destination unavailability. When this occurs, sending systems place messages into a structured queue for later delivery attempts. These queues operate as temporary holding areas where messages remain until conditions improve. Each queued message is associated with metadata that tracks delivery attempts, timestamps, and retry intervals. The system periodically re-evaluates queued messages and attempts retransmission based on updated routing information. If delivery continues to fail over extended periods, the system may increase retry intervals to reduce network strain. This deferred delivery mechanism ensures that messages are not lost due to transient failures. It also allows communication systems to maintain stability during periods of high traffic or infrastructure disruption. Queue management is a critical component of large-scale messaging systems, enabling them to handle variable workloads without sacrificing reliability or data integrity.
Domain Delegation and Hierarchical Name Resolution
The structure of naming systems used in network communication is hierarchical, allowing responsibility for different segments to be distributed across multiple administrative levels. At the top level, root authorities delegate control of major categories to intermediate systems responsible for specific domain groups. These intermediate systems then delegate authority further down to individual domain administrators. This delegation model ensures that no single system is responsible for the entire naming structure. Instead, responsibility is distributed, allowing for scalability and localized control. Each delegated level maintains records that define how queries should be directed to more specific authorities. This hierarchical model also applies to mail routing information, where domain-level configurations determine how messages should be handled within a specific administrative boundary. Delegation ensures that updates can be made independently at different levels without affecting the entire system. This structure is fundamental to the scalability and resilience of global communication networks.
Propagation Delays and Information Synchronization
When changes are made to routing configurations, these updates must be distributed across a wide network of caching systems and resolvers. This distribution process is not instantaneous and may take time depending on caching behavior and refresh intervals. During this period, different systems may temporarily hold outdated information, leading to inconsistencies in routing behavior. These delays are a natural consequence of distributed caching designed to optimize performance. To manage this, systems rely on time-based validity settings that determine how long information can be stored before requiring refresh. Once this time expires, systems request updated records from authoritative sources. This mechanism ensures eventual consistency across the network while maintaining efficiency during normal operations. However, during transitional periods, message delivery paths may vary depending on which cached data is being used. Understanding propagation behavior is essential for diagnosing temporary inconsistencies in communication routing.
Redundancy Design and Failover Strategies in Mail Systems
Reliability in communication infrastructure is achieved through redundancy and failover mechanisms that ensure continuity during system failures. Multiple mail handling servers are often deployed to serve the same domain, each configured with different priority levels. If the primary server becomes unavailable, traffic is automatically redirected to secondary systems. In more advanced configurations, systems operate in active-active mode, where multiple servers handle traffic simultaneously. This approach distributes load evenly and reduces dependency on a single system. Alternatively, active-passive configurations keep secondary servers idle until a failure occurs. Failover mechanisms are designed to activate automatically without manual intervention, ensuring minimal disruption to message delivery. These strategies are essential for maintaining high availability in environments where communication reliability is critical. Redundancy also extends to geographic distribution, where servers are placed in different regions to mitigate the impact of localized outages.
Message Authentication and Trust Verification Flow
Before accepting incoming messages, receiving systems often perform a series of trust verification checks to ensure message legitimacy. These checks involve validating whether the sending system is authorized to send messages on behalf of the claimed origin. Authentication mechanisms rely on predefined policies that describe which sources are permitted. When a message fails validation, the receiving system may apply different handling rules depending on configuration. Some messages may be accepted but marked for review, while others may be redirected or rejected entirely. Digital verification processes may also be applied to confirm that message content has not been altered during transmission. These verification steps are integrated into the receiving pipeline and occur before final message storage. The goal of these mechanisms is to reduce fraudulent communication and improve overall trust in electronic messaging systems.
Server Load Distribution and Traffic Balancing Techniques
In environments with high message volume, distributing traffic evenly across multiple systems is essential for maintaining performance. Load distribution mechanisms ensure that no single server becomes overwhelmed by incoming requests. This is achieved by assigning multiple destinations with equal priority values, allowing sending systems to alternate between them. Some implementations use adaptive selection methods that take server responsiveness into account when choosing destinations. This dynamic behavior allows systems to respond to changing conditions in real time. Load balancing also improves fault tolerance by ensuring that traffic can be redirected quickly if a server becomes unavailable. In large-scale deployments, traffic distribution may be influenced by geographic proximity or network latency, further optimizing delivery efficiency. These mechanisms collectively ensure that communication systems remain responsive even under heavy usage conditions.
Diagnostic Techniques for Routing and Delivery Failures
When message delivery issues occur, diagnostic processes are used to identify the root cause. These processes often begin by reviewing routing information to confirm that correct destinations are being used. If routing data appears valid, the next step involves analyzing connection attempts and error responses. Common issues include server unavailability, incorrect configuration, or network interruptions. Diagnostic systems may also examine message queues to determine whether messages are being delayed or repeatedly retried. In some cases, inconsistencies in cached routing information may lead to incorrect delivery attempts. Adjusting refresh intervals or clearing outdated records can resolve such issues. Detailed logging systems provide visibility into each stage of the delivery process, allowing administrators to trace message flow from origin to destination. Effective diagnostics require a structured understanding of both routing logic and transport behavior.
Impact of Network Conditions on Message Delivery Performance
Network conditions play a significant role in determining the speed and reliability of message delivery. High latency, packet loss, or congestion can all affect the ability of systems to establish successful connections. When network performance degrades, message delivery may be delayed or temporarily interrupted. Routing systems attempt to compensate for these conditions by retrying connections or switching to alternative destinations. In some cases, messages may remain in queued states until network conditions improve. Adaptive systems may also adjust retry intervals based on observed performance trends. These adjustments help balance delivery efficiency with network stability. Understanding the impact of network behavior is essential for optimizing communication systems, especially in distributed environments where multiple network paths may exist.
Advanced Routing Structures in Distributed Communication Systems
In complex infrastructures, routing structures may extend beyond simple hierarchical models to include distributed decision-making layers. These structures allow routing decisions to be influenced by multiple factors, including server health, geographic location, and historical performance. Instead of relying solely on static priority values, advanced systems may dynamically adjust routing behavior based on real-time conditions. This enables more efficient use of resources and improves overall delivery success rates. Distributed routing also allows systems to scale horizontally by adding new nodes without requiring major configuration changes. Each node participates in the routing process, contributing to a collective decision-making system. This approach enhances flexibility and resilience, making it suitable for large-scale communication environments where conditions are constantly changing.
Advanced Mail Routing Intelligence and Adaptive Delivery Systems
Modern communication infrastructures have evolved beyond static routing logic into adaptive systems capable of making real-time decisions based on network behavior, server responsiveness, and historical delivery patterns. Instead of relying only on predefined priority values, intelligent routing layers continuously evaluate the performance of available destinations. These systems analyze response times, connection success rates, and failure frequency to determine the most efficient delivery path at any given moment. When a destination server begins to show signs of latency or instability, routing intelligence can temporarily reduce its preference in the selection process. Conversely, consistently stable servers may be promoted in priority during active delivery cycles. This adaptive behavior allows the system to respond dynamically to changing conditions without requiring manual configuration updates. In distributed environments, this intelligence is often shared across multiple nodes, enabling collective optimization of routing decisions. The result is a highly responsive communication ecosystem that adjusts itself in real time to maintain message delivery efficiency and reliability.
Distributed Coordination Between Mail Handling Nodes
In large-scale communication environments, mail handling is rarely confined to a single system. Instead, multiple nodes operate in coordination to manage message intake, processing, and delivery. These nodes communicate with each other to synchronize state information, ensuring that no single system operates with outdated or inconsistent data. Coordination includes sharing information about server availability, load levels, and recent delivery performance. When one node detects a failure or degradation in a destination server, it can propagate this information to other nodes, allowing them to adjust their routing behavior accordingly. This distributed coordination reduces redundant connection attempts to failing systems and improves overall efficiency. It also ensures that message delivery behavior remains consistent across different entry points into the system. In highly distributed environments, coordination mechanisms are essential for maintaining coherence across geographically separated infrastructure components.
Temporal Behavior of Routing Data and System Refresh Cycles
Routing information is not permanently static; it is governed by temporal constraints that define how long data remains valid before requiring refresh. These constraints are essential for balancing performance and accuracy. When routing data is retrieved, it is cached for a specified duration to reduce repeated lookup operations. During this caching period, systems use stored information instead of repeatedly querying authoritative sources. However, once the validity period expires, a new lookup is required to ensure that the most current routing configuration is used. This refresh cycle helps ensure that changes in infrastructure, such as server additions or removals, are eventually reflected across all systems. The duration of these cycles can significantly impact system behavior. Shorter cycles increase accuracy but generate more network traffic, while longer cycles improve efficiency but may introduce temporary inconsistencies. Proper tuning of these parameters is critical for maintaining optimal system performance in dynamic environments.
Hierarchical Failure Recovery and Escalation Paths
When primary routing attempts fail, communication systems follow structured escalation paths designed to maximize delivery success. These paths are typically defined in hierarchical order based on priority values assigned to available destinations. The system first attempts delivery to the highest-priority destination. If this attempt fails, the system escalates to the next available option. This process continues until a successful connection is established or all options are exhausted. In advanced configurations, escalation may include additional logic that temporarily bypasses certain destinations if they are consistently failing. This prevents repeated attempts to unstable systems and improves overall delivery efficiency. Some systems also implement retry backoff strategies, where the interval between attempts increases progressively after repeated failures. This reduces network strain and allows time for temporary issues to resolve. Hierarchical failure recovery ensures that communication remains resilient even in the presence of partial system outages.
Message Integrity Assurance During Transmission
Ensuring message integrity during transmission is a critical component of communication systems. As messages traverse multiple network layers, they may be subject to delays, packet fragmentation, or route changes. To protect against corruption or unauthorized modification, systems employ integrity verification mechanisms. These mechanisms generate cryptographic or structured validation data that accompanies the message throughout its journey. When the message reaches its destination, the receiving system performs verification checks to ensure that the content has not been altered. If discrepancies are detected, the message may be rejected or flagged for further inspection. Integrity assurance also includes sequence validation to ensure that message components arrive in the correct order. This is particularly important in environments where large messages are broken into smaller segments for transmission. By maintaining strict integrity controls, communication systems ensure that delivered messages accurately reflect their original content.
Load Sensitivity and Adaptive Resource Allocation
Communication systems must handle varying levels of traffic, often fluctuating between low and high demand periods. To manage this variability, modern infrastructures implement load-sensitive behavior that adjusts resource allocation dynamically. When traffic increases, additional processing resources may be activated to handle the increased demand. Conversely, during low-traffic periods, systems may reduce resource usage to improve efficiency. Load-sensitive routing also influences destination selection, as servers under heavy load may temporarily receive fewer incoming connections. This prevents performance degradation and ensures more balanced system utilization. In distributed environments, load information is shared across nodes to enable coordinated decision-making. This allows the system to maintain stability even during sudden traffic spikes. Adaptive resource allocation ensures that communication systems remain responsive and efficient under a wide range of operating conditions.
Geographically Distributed Delivery Optimization
In global communication environments, geographic distance between systems can significantly impact delivery performance. To address this, routing systems may incorporate location-aware optimization techniques. These techniques evaluate the physical or network proximity between sending and receiving systems to determine the most efficient delivery path. Messages may be directed to geographically closer servers to reduce latency and improve delivery speed. In multi-region infrastructures, routing decisions may also consider regional availability and regulatory constraints. This ensures that messages are processed within appropriate jurisdictions when required. Geographic optimization often works in combination with priority-based routing, resulting in a multi-factor decision model. This model balances performance, reliability, and compliance considerations to determine optimal delivery paths. By integrating geographic awareness into routing logic, communication systems can achieve lower latency and improved user experience across distributed environments.
Behavior of Queued Messages Under Prolonged Failure Conditions
When message delivery fails repeatedly over extended periods, queued messages remain in a holding state while retry mechanisms continue attempting delivery. Over time, the system may adjust retry frequency based on failure patterns to avoid excessive resource consumption. Messages that remain undelivered for long durations are typically marked with extended retry intervals. In some systems, escalation policies may be applied to notify administrators of persistent delivery failures. Queue behavior is influenced by both routing information and network conditions. If routing data changes during the queue period, messages may be redirected to alternative destinations without requiring regeneration. This dynamic adjustment ensures that messages remain viable even when infrastructure changes occur. However, if failure conditions persist beyond defined thresholds, messages may eventually be discarded or returned to the sender. Queue management ensures that temporary issues do not result in immediate message loss while maintaining system efficiency.
Protocol Interaction with Multi-Layer Communication Stacks
Message delivery systems operate within multi-layer communication frameworks where different layers handle distinct responsibilities. The transport layer manages connection establishment and data transfer, while higher layers define message formatting and delivery rules. Routing systems operate at an intermediary level, bridging naming resolution with transport execution. When a message is sent, each layer contributes to the delivery process in a coordinated sequence. The routing layer first determines the destination server, after which the transport layer establishes a connection. Once the connection is active, the message formatting layer ensures that data is structured correctly for transmission. After delivery, acknowledgment signals are propagated back through the layers to confirm success or report failure. This layered architecture allows each component to function independently while contributing to a unified delivery process. It also enables modular upgrades and improvements without disrupting the entire system.
Consistency Models in Distributed Routing Environments
In distributed systems, maintaining consistent routing behavior across multiple nodes is a complex challenge. Different nodes may temporarily hold different versions of routing information due to caching delays or propagation latency. To manage this, systems adopt consistency models that define how and when data synchronization occurs. Some systems prioritize immediate consistency, ensuring that all nodes reflect changes as quickly as possible. Others adopt eventual consistency, where updates propagate gradually across the network. Each model has trade-offs between performance and accuracy. In eventual consistency models, temporary discrepancies may occur, but the system eventually converges to a unified state. In immediate consistency models, synchronization overhead may reduce performance but ensures uniform behavior. Routing systems must carefully balance these models to achieve both reliability and efficiency in distributed environments.
Failure Isolation and Containment Strategies
When failures occur within communication systems, it is essential to isolate affected components to prevent widespread disruption. Failure isolation mechanisms detect malfunctioning servers or network segments and remove them from active routing pools. This prevents continued traffic attempts to unstable systems. Containment strategies ensure that failures remain localized and do not propagate across the network. In some cases, redundant systems automatically take over responsibilities from failed components, maintaining uninterrupted service. Monitoring systems continuously evaluate server health to detect early signs of failure. Once detected, traffic is gradually shifted away from affected systems to reduce impact. This proactive approach ensures that communication systems remain stable even during partial infrastructure failures. Isolation and containment are critical for maintaining resilience in large-scale distributed environments.
Long-Term Evolution of Email Routing Infrastructure
Over time, communication infrastructure has evolved from simple static routing models to highly dynamic, intelligent systems capable of real-time adaptation. Early systems relied on fixed configurations that required manual updates for any changes in infrastructure. Modern systems, however, incorporate automation, distributed coordination, and adaptive decision-making to optimize performance. This evolution has been driven by increasing message volumes, global connectivity demands, and the need for higher reliability. Contemporary routing systems are capable of self-adjustment, load balancing, and failure recovery without human intervention. They integrate multiple layers of intelligence to ensure efficient delivery under varying conditions. As communication demands continue to grow, routing infrastructure will likely become even more autonomous, incorporating predictive analytics and machine-driven optimization to further enhance performance and reliability.
Conclusion
Email routing systems form the backbone of modern electronic communication, ensuring that messages are delivered accurately, efficiently, and reliably across distributed networks. At their core, these systems depend on structured naming and resolution mechanisms that translate human-readable identifiers into actionable delivery instructions. What appears to be a simple act of sending a message actually involves multiple coordinated processes working in sequence, each responsible for a specific layer of interpretation, validation, or transmission. The overall architecture is designed to separate concerns so that naming, routing, transport, and storage functions can operate independently while still contributing to a unified delivery pipeline.
One of the most important aspects of this ecosystem is the way routing information is structured and interpreted. Instead of relying on direct static addressing, systems use prioritized destination lists that allow flexibility in how messages are delivered. This priority-based approach ensures that communication does not depend on a single point of failure. If one destination becomes unavailable, the system can automatically transition to alternative routes without requiring manual intervention. This built-in redundancy is essential for maintaining continuity in environments where uptime and reliability are critical.
Another defining characteristic of email routing infrastructure is its distributed nature. Rather than relying on a single centralized authority, responsibility is spread across multiple hierarchical and regional components. This distribution allows different segments of the system to operate independently while still adhering to global coordination rules. It also improves scalability, as new systems can be integrated without disrupting existing operations. The hierarchical structure ensures that routing decisions are made progressively, starting from broad reference systems and narrowing down to authoritative sources responsible for specific domains.
Caching and time-based validity mechanisms play a crucial role in optimizing performance within these systems. By storing routing information temporarily, systems reduce the need for repeated lookups, which significantly improves efficiency. However, this caching behavior introduces a balance between performance and freshness of data. Time-to-live parameters define how long information remains valid before it must be refreshed. This ensures that changes in infrastructure eventually propagate across all systems while still maintaining high-speed operation during normal conditions. The trade-off between consistency and efficiency is carefully managed through these timing controls.
Reliability is further enhanced through failover and redundancy strategies. Multiple servers are often configured to handle the same domain, allowing traffic to shift automatically in the event of a failure. These configurations can operate in different modes, including active-active setups where load is shared, or active-passive setups where backup systems remain idle until needed. This redundancy ensures that even in the presence of hardware failures or network disruptions, message delivery can continue without interruption. The system’s ability to adapt dynamically to failures is one of its most important resilience features.
Message queuing is another essential component that ensures delivery even when immediate transmission is not possible. Instead of discarding failed messages, systems temporarily store them and attempt retransmission based on predefined intervals. This approach allows communication to remain reliable even under unstable network conditions. Queued messages are tracked with metadata that records delivery attempts, timestamps, and retry logic. Over time, the system adjusts its behavior based on success or failure patterns, improving efficiency while maintaining persistence of delivery attempts.
Security and trust verification mechanisms add another layer of protection to the entire ecosystem. These mechanisms ensure that messages originate from legitimate sources and have not been altered during transmission. Validation processes may include checks against authorized sending systems, integrity verification of message content, and policy-based handling of failed authentication attempts. These safeguards are critical in preventing unauthorized use of communication channels and maintaining trust in electronic messaging systems.
Load distribution techniques ensure that no single server becomes overwhelmed by incoming traffic. By spreading requests across multiple systems, communication infrastructure maintains stability even during periods of high demand. These techniques may include equal priority distribution, adaptive selection based on performance, or geographically aware routing decisions. Load balancing not only improves performance but also enhances fault tolerance by reducing dependency on individual components.
Network conditions also significantly influence delivery behavior. Factors such as latency, congestion, and packet loss can affect how quickly and successfully messages are transmitted. Routing systems must adapt to these conditions by adjusting retry intervals, switching destinations, or temporarily queuing messages. This adaptability ensures that communication remains functional even when underlying network conditions are less than ideal. The system’s ability to respond to changing conditions in real time is a key factor in its overall robustness.
Over time, email routing systems have evolved from simple static models into highly adaptive and intelligent infrastructures. Early implementations required manual configuration and lacked flexibility, while modern systems incorporate dynamic decision-making, distributed coordination, and performance-based optimization. This evolution has been driven by the increasing scale and complexity of global communication demands. Today’s systems are capable of self-adjustment, predictive behavior, and automated recovery from failures.
Despite this complexity, the fundamental purpose remains consistent: ensuring that messages reach their intended destinations accurately and efficiently. Every component, from routing logic to transport protocols and security validation, contributes to this objective. The seamless interaction between these components creates the illusion of simplicity for end users, even though the underlying system is highly sophisticated.
Ultimately, email routing infrastructure represents a carefully balanced ecosystem of reliability, scalability, and adaptability. It combines hierarchical organization with distributed execution, static configuration with dynamic adjustment, and performance optimization with security enforcement. This combination allows it to support one of the most widely used communication systems in the world, handling vast volumes of messages across diverse environments while maintaining consistent and dependable delivery behavior.