Modern digital environments depend heavily on structured and reliable data storage systems that can support continuous information flow across applications, services, and analytics platforms. A database management system is the foundational software layer responsible for organizing, storing, retrieving, and securing data in a structured format. It acts as an intermediary between users, applications, and physical storage systems, ensuring that data operations remain consistent and efficient. In large-scale environments, database systems are not just storage tools but critical components that support decision-making, operational workflows, and business intelligence. Organizations rely on these systems to maintain accurate records of transactions, user activities, product inventories, and analytical insights. The ability of a database system to handle large volumes of structured and unstructured data determines how effectively an organization can respond to market changes and user demands.
Database management systems are designed to handle concurrency, ensuring that multiple users can access and modify data simultaneously without causing inconsistencies. They also provide mechanisms for data security, backup, and recovery, which are essential for protecting sensitive information and maintaining system reliability. In enterprise environments, database systems are integrated into nearly every application, from customer relationship platforms to financial systems and content management tools. This deep integration highlights the importance of understanding how data is structured and managed at a fundamental level.
How Data Storage Works in Large-Scale Applications
Data storage in modern applications is not simply about saving information; it involves organizing data in a way that ensures fast retrieval, efficient processing, and long-term scalability. Large-scale applications often deal with millions or even billions of records, requiring storage systems that can handle high volumes of transactions without performance degradation. Database systems achieve this through structured storage models that organize data into logical units. These units are optimized for query performance and data integrity, ensuring that users can retrieve relevant information quickly and accurately.
The storage process involves writing data to physical or cloud-based storage systems while maintaining logical structures that define how the data is accessed. Indexing mechanisms are often used to accelerate query performance by allowing the system to locate specific records without scanning entire datasets. This becomes particularly important in environments where real-time data access is required, such as financial trading systems, e-commerce platforms, and analytics dashboards. Efficient data storage design ensures that systems remain responsive even as data volume increases over time.
Relational Database Model and Its Core Principles
The relational database model is one of the most widely adopted approaches for structuring and managing data. It is based on the concept of organizing data into tables that represent different entities within a system. Each table consists of rows and columns, where rows represent individual records and columns define attributes associated with those records. This structure allows data to be logically organized in a way that is both human-readable and machine-efficient.
The relational model is built on the principle of relationships between data entities. Instead of storing all information in a single structure, data is divided into multiple tables that are linked through defined relationships. This approach reduces redundancy and improves consistency across the database. It also allows for more flexible data modeling, where changes in one part of the system do not require restructuring the entire database.
Relational systems rely heavily on mathematical principles derived from set theory and relational algebra. These foundations enable complex data operations such as filtering, sorting, joining, and aggregating data across multiple tables. The structured nature of relational databases makes them ideal for applications that require high levels of data integrity and consistency.
Tables, Rows, Columns, and Data Relationships
In relational databases, tables serve as the primary structure for storing data. Each table is designed to represent a specific entity, such as customers, orders, or products. Within each table, rows represent individual records, while columns define the properties of those records. This structured format allows data to be organized consistently and predictably.
Relationships between tables are established through key fields that connect related data across different structures. This allows information stored in separate tables to be combined and analyzed as a unified dataset. For example, a customer table may be linked to an orders table through a unique customer identifier, enabling the system to retrieve all orders associated with a specific customer.
This relational structure enhances data flexibility by allowing multiple perspectives on the same dataset. It also reduces duplication by ensuring that each piece of information is stored only once and referenced as needed. This approach improves storage efficiency and reduces the risk of inconsistencies arising from duplicated data entries.
Primary Keys, Foreign Keys, and Data Integrity
Data integrity is a critical aspect of relational database design. It ensures that the information stored within the system remains accurate, consistent, and reliable over time. Primary keys play a central role in maintaining this integrity by uniquely identifying each record within a table. No two records in the same table can share the same primary key, which guarantees uniqueness and prevents duplication.
Foreign keys are used to establish relationships between tables. A foreign key in one table references the primary key in another table, creating a link between related datasets. This relationship ensures that data remains consistent across the database and that changes in one table are reflected in related tables. These key relationships form the backbone of relational database architecture, enabling complex data structures to function cohesively.
Data integrity rules also include constraints that define how data can be entered, updated, or deleted. These rules help prevent invalid or inconsistent data from entering the system. By enforcing strict structural guidelines, relational databases maintain a high level of reliability, which is essential for business-critical applications.
Structured Query Language and Its Role in Data Operations
Structured Query Language serves as the primary interface for interacting with relational database systems. It provides a standardized method for performing operations such as data retrieval, insertion, updating, and deletion. SQL is designed to be both powerful and accessible, allowing users to execute complex data operations using relatively simple syntax.
SQL is divided into different categories of commands, each serving a specific purpose. Data definition commands are used to create and modify database structures, while data manipulation commands handle the insertion and retrieval of information. Data control commands manage permissions and access rights, ensuring that only authorized users can interact with specific parts of the database.
The standardized nature of SQL allows it to be used across different relational database systems, making it an essential skill in data management and software development. Its ability to handle complex queries involving multiple tables and conditions makes it a critical tool for analyzing large datasets.
SQL Commands and Data Interaction Workflow
The process of interacting with a database using SQL involves writing queries that define specific operations. These queries are interpreted by the database engine, which then executes the requested actions and returns the results. This interaction model allows users to extract meaningful insights from large datasets without needing to understand the underlying storage mechanisms.
SQL queries can be simple or highly complex, depending on the requirements of the operation. Simple queries may retrieve all records from a table, while more advanced queries can combine multiple tables, apply filters, and perform calculations. This flexibility makes SQL suitable for a wide range of applications, from basic data retrieval to advanced analytical processing.
The efficiency of SQL queries depends on how well the database is structured and indexed. Proper database design ensures that queries execute quickly and return accurate results, even when dealing with large volumes of data.
Evolution and Importance of Relational Databases
Relational databases have evolved over several decades to become the dominant model for structured data storage. Their popularity is driven by their ability to provide consistent, reliable, and scalable data management solutions. Over time, relational systems have been optimized to handle increasingly complex workloads, making them suitable for modern enterprise applications.
The widespread adoption of relational databases is also due to their strong theoretical foundation and standardized query language. These systems provide a predictable and stable environment for managing critical business data. Their ability to enforce data integrity and support complex relationships makes them essential for industries such as finance, healthcare, and e-commerce.
MySQL as a Leading Relational Database System
MySQL is one of the most widely used relational database systems in modern computing environments. It is designed to provide high performance, reliability, and scalability for a wide range of applications. MySQL supports standard SQL operations and is capable of handling large datasets with high efficiency.
The system is known for its ability to support high-traffic applications, making it a popular choice for web-based platforms and enterprise systems. Its architecture is optimized for speed and reliability, allowing it to process large numbers of queries simultaneously. MySQL also supports multiple storage engines, which provide flexibility in how data is stored and managed.
Architecture and Performance Characteristics of MySQL
MySQL’s architecture is designed to separate query processing from storage management. This modular design allows for flexibility in optimizing performance based on specific application requirements. The system uses indexing and caching mechanisms to improve query execution speed and reduce latency.
Scalability is another key feature of MySQL, allowing it to handle increasing data volumes without significant performance degradation. It supports replication and clustering techniques that enable data distribution across multiple servers, improving reliability and availability.
Open Source Development and Community Ecosystem of MySQL
MySQL is supported by a strong open-source community that contributes to its continuous development and improvement. This collaborative ecosystem ensures that the system remains up-to-date with modern data management requirements. The open-source nature of MySQL allows organizations to adopt and customize the system according to their needs without licensing restrictions.
Community contributions play a significant role in enhancing system features, improving performance, and addressing security concerns. This collaborative model has helped MySQL maintain its position as one of the most widely used relational database systems in the world.
Introduction to Database Access and Management Interfaces
While SQL provides direct interaction with databases, graphical and terminal-based interfaces simplify the process of managing and querying data. These tools offer visual representations of database structures, making it easier to navigate complex datasets. They also provide features for executing queries, monitoring performance, and managing connections to multiple database systems.
Such interfaces are particularly useful in environments where multiple databases are managed simultaneously. They streamline workflows by providing a centralized platform for database operations, reducing the need to switch between different tools or command-line environments.
Understanding MySQL in Modern Data Infrastructure Environments
MySQL operates as a high-performance relational database management system designed to support structured data storage and retrieval across a wide range of applications. It plays a central role in modern data-driven environments where applications rely on fast, reliable, and scalable data access. MySQL is built to handle both small-scale applications and large enterprise systems, making it a flexible solution for diverse workloads. Its widespread adoption is driven by its ability to efficiently process large volumes of queries while maintaining stability and data integrity.
In modern software ecosystems, MySQL is often integrated into web applications, analytics platforms, and enterprise systems. It provides the backend infrastructure that enables applications to store user information, transaction records, and operational data. The system is optimized for performance, ensuring that even under heavy loads, queries are executed efficiently. This makes it suitable for environments where high availability and responsiveness are critical requirements.
MySQL also supports multiple deployment models, including local installations, cloud-based environments, and distributed systems. This flexibility allows organizations to design database architectures that align with their scalability and performance needs. As data requirements grow, MySQL can be expanded through replication and clustering techniques to ensure continuous availability and load balancing.
Core Architectural Design of MySQL Systems
The architecture of MySQL is designed around a modular structure that separates different components of database processing. This separation allows the system to efficiently manage query execution, storage handling, and memory usage. At the core of MySQL is the SQL processing layer, which interprets user queries and translates them into operations that interact with the storage engine.
The storage engine layer is responsible for physically managing how data is stored and retrieved. MySQL supports multiple storage engines, each optimized for specific types of workloads. Some engines focus on transactional processing, while others prioritize speed and read-heavy operations. This flexibility allows database administrators to choose the most suitable configuration based on application requirements.
Another critical component of MySQL architecture is the buffer pool, which stores frequently accessed data in memory. This reduces the need for repeated disk access and significantly improves query performance. The query cache mechanism, although less commonly used in modern versions, also plays a role in speeding up repeated queries by storing previously executed results.
Data Storage Mechanisms and Indexing Strategies
Efficient data storage is a fundamental aspect of MySQL performance. Data is stored in structured tables, where each table represents a logical entity within the system. The physical storage of these tables is managed by the underlying storage engine, which determines how data is written to disk and retrieved during queries.
Indexing is one of the most important optimization techniques used in MySQL. Indexes allow the database system to quickly locate specific records without scanning entire tables. This significantly improves query performance, especially in large datasets. Indexes are typically created on columns that are frequently used in search conditions or join operations.
There are different types of indexes used in MySQL, including primary indexes, secondary indexes, and composite indexes. Each type serves a specific purpose in optimizing data retrieval. Proper index design is essential for maintaining system performance, as poorly designed indexes can lead to unnecessary overhead and slower query execution.
Query Execution Process and Optimization Techniques
When a query is submitted to MySQL, it goes through several stages before results are returned. The first stage involves parsing the query to ensure it is syntactically correct. Once validated, the query optimizer evaluates different execution strategies to determine the most efficient way to retrieve the requested data.
The query optimizer plays a crucial role in performance enhancement. It analyzes available indexes, table structures, and data distribution to select an optimal execution plan. This process ensures that the database system minimizes resource usage while maximizing speed.
Once an execution plan is selected, the storage engine retrieves the required data and processes it according to the query instructions. The final results are then returned to the user or application. Query optimization techniques such as indexing, query rewriting, and caching are essential for maintaining high performance in large-scale systems.
Transaction Management and Data Consistency in MySQL
Transactions are a key feature of relational database systems that ensure data consistency during multiple operations. A transaction is a sequence of operations that are treated as a single unit. MySQL ensures that either all operations within a transaction are completed successfully or none of them are applied.
This behavior is governed by the ACID properties, which stand for atomicity, consistency, isolation, and durability. Atomicity ensures that transactions are treated as indivisible units. Consistency guarantees that the database remains in a valid state after each transaction. Isolation ensures that concurrent transactions do not interfere with each other. Durability ensures that once a transaction is committed, it remains permanent even in the event of system failure.
Transaction management is particularly important in financial systems, e-commerce platforms, and any application where data accuracy is critical. MySQL provides mechanisms such as rollback and commit operations to manage transaction states effectively.
Concurrency Control and Multi-User Access Handling
In environments where multiple users access the database simultaneously, concurrency control becomes essential. MySQL uses locking mechanisms and isolation levels to manage simultaneous data access. These mechanisms ensure that data remains consistent even when multiple operations occur at the same time.
Locking can be applied at different levels, including row-level and table-level locking. Row-level locking allows multiple users to access different rows of the same table simultaneously, improving concurrency. Table-level locking restricts access to the entire table during certain operations, ensuring data integrity during critical updates.
Isolation levels define how transaction changes are visible to other transactions. Different isolation levels provide a balance between performance and consistency, allowing developers to choose the appropriate level based on application requirements.
Data Security and Access Control Mechanisms
Security is a critical aspect of database management systems, and MySQL provides multiple layers of protection to safeguard data. Access control mechanisms ensure that only authorized users can perform specific operations within the database. User accounts are assigned privileges that define what actions they can perform, such as reading, writing, or modifying data.
Authentication mechanisms verify user identity before granting access to the system. MySQL supports password-based authentication as well as more advanced security methods such as encrypted connections. These security features help protect sensitive data from unauthorized access and potential breaches.
Data encryption is also an important component of MySQL security. Encryption can be applied to data at rest as well as data in transit, ensuring that information remains protected throughout its lifecycle. These security measures are essential for maintaining compliance with data protection standards in enterprise environments.
Backup, Recovery, and Data Reliability Strategies
Database reliability is maintained through robust backup and recovery mechanisms. MySQL provides tools for creating full backups, incremental backups, and point-in-time recovery options. These features ensure that data can be restored in the event of system failure, corruption, or accidental deletion.
Backup strategies are typically designed based on the criticality of the data and the required recovery time objectives. Regular backups ensure that recent data can be recovered without significant loss. Recovery processes involve restoring data from backup files and applying transaction logs to bring the database to its most recent state.
Reliability is further enhanced through replication techniques, where data is copied across multiple database servers. This ensures high availability and reduces the risk of data loss in case of hardware failure.
Scalability and Performance Tuning in MySQL Systems
Scalability is a key requirement in modern database systems, especially as data volumes continue to grow. MySQL supports vertical and horizontal scaling techniques to handle increasing workloads. Vertical scaling involves upgrading hardware resources, while horizontal scaling involves distributing data across multiple servers.
Performance tuning is an ongoing process that involves optimizing queries, adjusting configuration settings, and improving indexing strategies. Database administrators monitor system performance to identify bottlenecks and implement optimization techniques.
Caching mechanisms, query optimization, and load balancing all contribute to improving system performance. These techniques ensure that MySQL can handle high traffic environments without compromising speed or reliability.
Role of MySQL in Web Applications and Enterprise Systems
MySQL is widely used in web application development due to its reliability and ease of integration. It serves as the backend database for content management systems, e-commerce platforms, and social networking applications. Its ability to handle large numbers of concurrent users makes it suitable for high-traffic websites.
In enterprise systems, MySQL is used to manage business-critical data such as financial records, customer information, and operational workflows. Its scalability and performance capabilities make it suitable for large organizations with complex data requirements.
The integration of MySQL with programming languages and development frameworks further enhances its usability in modern software development environments.
Data Modeling Techniques in Relational Systems
Data modeling is the process of designing database structures that accurately represent real-world entities and relationships. In relational systems, data modeling involves defining tables, attributes, and relationships between entities.
Normalization is a key technique used in data modeling to eliminate redundancy and improve data integrity. It involves organizing data into multiple related tables to reduce duplication. Proper data modeling ensures that databases are efficient, scalable, and easy to maintain.
Entity-relationship modeling is commonly used to visualize database structures and define relationships between different data entities. This approach helps in designing logical and physical database schemas that align with application requirements.
Integration of MySQL with Modern Development Environments
MySQL integrates seamlessly with modern programming languages and development frameworks. This allows developers to build dynamic applications that interact with databases in real time. APIs and database connectors enable applications to send queries and receive data efficiently.
This integration supports a wide range of use cases, from simple data retrieval operations to complex analytical processing. It also enables the development of scalable applications that can handle large volumes of data and user interactions.
Modern development environments often include tools that simplify database connectivity, query execution, and performance monitoring, making MySQL an essential component of application development workflows.
Evolution of Database Management Tools in Multi-Database Environments
Modern data ecosystems rarely rely on a single database system. Instead, organizations operate across multiple relational and non-relational databases to support different applications, services, and analytical needs. This complexity has led to the evolution of database management tools that provide unified access to multiple systems through a single interface. These tools reduce operational complexity and improve productivity by allowing database professionals to manage different environments without switching between multiple applications.
In earlier database workflows, administrators and developers were required to use separate clients for each database system. This created inefficiencies and increased the learning curve for managing diverse infrastructures. As data environments became more distributed, the need for cross-platform database clients grew significantly. These tools are designed to simplify connectivity, improve usability, and provide consistent interaction models across different database technologies.
Modern database management tools focus on accessibility, lightweight performance, and cross-platform compatibility. They are designed to run on multiple operating systems while supporting connections to various relational database systems. This allows users to maintain a unified workflow regardless of the underlying database architecture.
Understanding Cross-Platform SQL Client Architecture
Cross-platform SQL clients are designed to provide a consistent interface for interacting with multiple database systems. These tools act as intermediaries between users and databases, translating user actions into structured queries that can be executed across different database engines.
The architecture of these clients typically includes a connection manager, query execution engine, and user interface layer. The connection manager handles authentication and communication with database servers. It supports different connection types, including direct connections, remote server access, and secure, encrypted tunnels.
The query execution engine is responsible for sending SQL commands to the database and retrieving results. It ensures compatibility with different database dialects while maintaining consistent output formatting. The user interface layer provides visual tools such as query editors, schema explorers, and result viewers that simplify database interaction.
Cross-platform compatibility is achieved through the use of standardized communication protocols and abstraction layers. This allows the same tool to connect to multiple database systems without requiring system-specific modifications.
Introduction to Lightweight Database Clients in Modern Workflows
Lightweight database clients have become increasingly popular due to their simplicity and efficiency. These tools are designed to provide essential database management functionality without unnecessary complexity. They focus on core features such as connection management, query execution, and result visualization.
Unlike traditional enterprise database management systems, lightweight clients prioritize speed and usability. They are often used in development environments where quick access to databases is required for testing, debugging, and analysis tasks. Their minimal resource requirements make them suitable for use on a wide range of systems, including low-power machines and remote development environments.
These tools are particularly valuable in agile development workflows, where rapid iteration and continuous testing are essential. By providing a streamlined interface, they allow developers to focus on query logic and data analysis rather than system configuration.
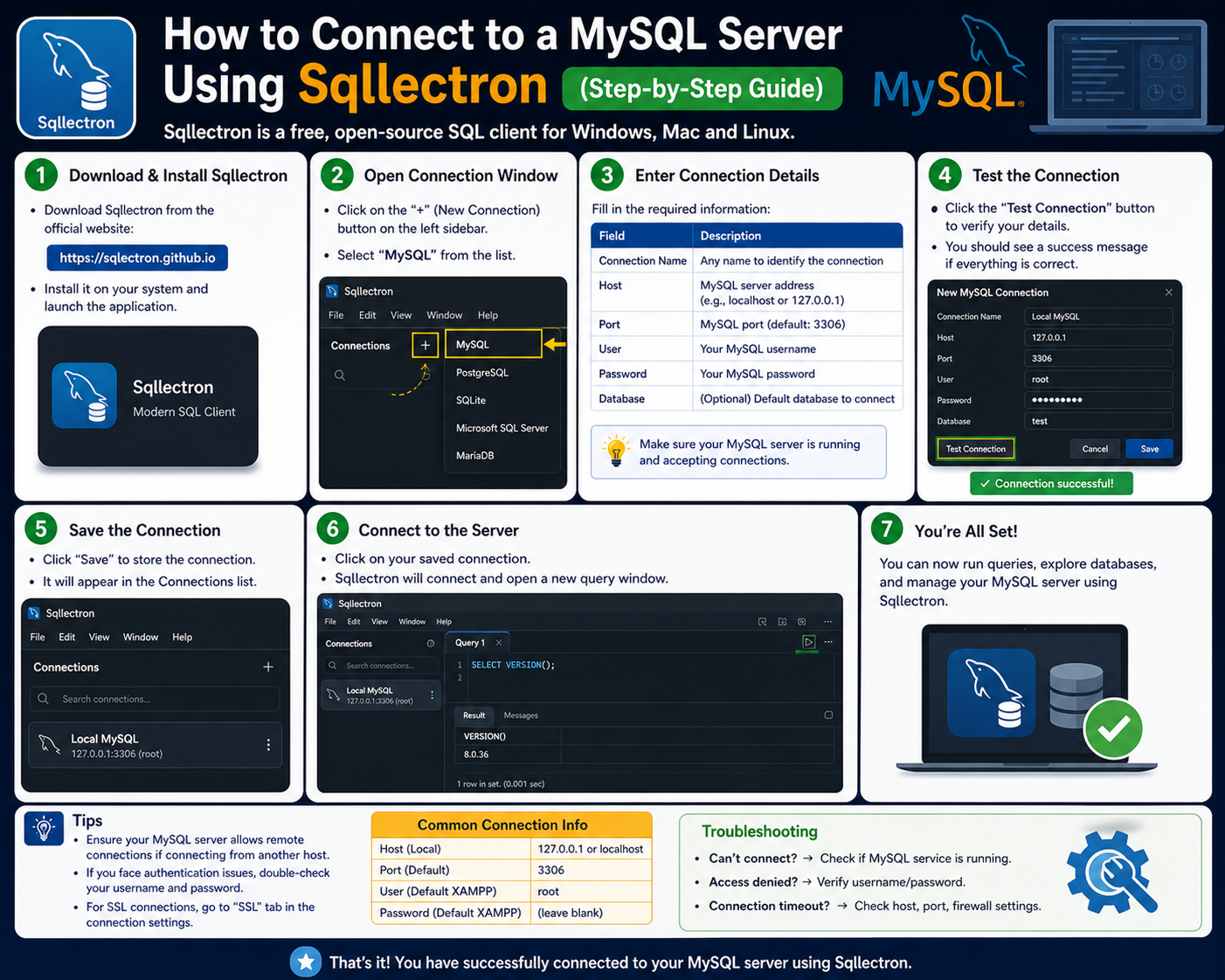
Overview of Sqlectron in Modern Database Ecosystems
Sqlectron is a lightweight database client designed to simplify interaction with relational database systems. It provides a unified interface that supports multiple database connections, allowing users to manage different databases from a single application. Its design emphasizes simplicity, cross-platform compatibility, and ease of use.
Sqlectron is commonly used by developers, database administrators, and data analysts who need quick access to multiple database systems. It supports both graphical and terminal-based interfaces, offering flexibility based on user preference. The graphical interface provides a visual environment for managing connections and executing queries, while the terminal version caters to users who prefer command-line workflows.
The tool is designed to be minimalistic, focusing on essential database operations rather than advanced enterprise features. This makes it particularly useful in development and testing environments where speed and simplicity are more important than complex configuration options.
Connection Management and Database Access Workflow
Database connection management is a fundamental feature of Sqlectron. The tool allows users to create and manage multiple database connections within a single interface. Each connection requires essential information such as database type, host address, port number, authentication credentials, and optional security configurations.
Once a connection is established, it is stored within the application for future use. This eliminates the need to repeatedly enter connection details, improving efficiency in repetitive workflows. Users can switch between different database connections seamlessly, enabling multitasking across multiple environments.
Secure connection options are also supported, including encrypted authentication methods and secure shell tunneling. These features enhance security when accessing remote databases, ensuring that sensitive information is protected during transmission.
Query Execution and Data Retrieval Processes
Sqlectron provides a query editor that allows users to write and execute structured queries directly against connected databases. The query execution process involves sending SQL commands to the database server and retrieving structured results.
The results are displayed in a tabular format, making it easy to analyze and interpret data. Users can execute simple queries for data retrieval or complex queries involving joins, filters, and aggregations. The tool also supports multiple query execution, allowing users to run batch operations efficiently.
Query execution performance depends on the underlying database system as well as the complexity of the query. Sqlectron acts as an intermediary, ensuring that queries are properly formatted and transmitted to the database engine for processing.
Multi-Database Support and Cross-System Compatibility
One of the key advantages of Sqlectron is its ability to support multiple database systems. It is designed to work with popular relational databases, allowing users to manage different systems without switching tools. This cross-database compatibility simplifies workflows in environments where multiple database technologies are used simultaneously.
The tool abstracts differences between database systems, providing a consistent interface for query execution and data management. This reduces the need for users to learn system-specific tools or interfaces for each database platform.
Cross-database support also enables comparative analysis across different systems. Users can retrieve and compare data from multiple sources within a unified environment, improving data analysis capabilities.
Graphical Interface and User Experience Design Principles
The graphical interface of Sqlectron is designed to be intuitive and user-friendly. It provides a clean layout that organizes database connections, query editors, and result views in a structured manner. This design reduces cognitive load and allows users to focus on database operations rather than interface navigation.
The interface includes features such as syntax highlighting, query history, and result filtering. These features enhance productivity by making it easier to write and manage queries. The visual design emphasizes simplicity, ensuring that even users with limited technical experience can navigate the tool effectively.
User experience design plays a crucial role in database management tools, as it directly impacts efficiency and usability. A well-designed interface reduces the time required to perform database operations and minimizes the risk of errors.
Terminal-Based Database Interaction and Command-Line Usage
In addition to its graphical interface, Sqlectron provides a terminal-based version for users who prefer command-line environments. This version offers similar functionality but operates entirely through text-based commands.
Terminal-based database interaction is widely used in development and system administration environments due to its speed and flexibility. It allows users to execute queries, manage connections, and retrieve data without relying on graphical interfaces.
This approach is particularly useful in remote server environments where graphical interfaces may not be available. It also supports automation through scripting, enabling repetitive database tasks to be executed efficiently.
Security Practices in Database Client Applications
Security is a critical consideration in database management tools. Sqlectron incorporates several security features to ensure safe database access. These include encrypted connections, secure authentication methods, and support for SSH tunneling.
Encrypted connections protect data during transmission between the client and the database server. Authentication mechanisms ensure that only authorized users can access database systems. SSH tunneling provides an additional layer of security by creating a secure channel for database communication.
These security practices are essential in environments where sensitive data is handled. They help prevent unauthorized access and ensure compliance with data protection standards.
Workflow Optimization in Database Development Environments
Database development workflows often involve repetitive tasks such as querying, testing, and debugging. Tools like Sqlectron help optimize these workflows by providing quick access to multiple databases and simplifying query execution.
Workflow optimization is achieved through features such as saved connections, query history, and reusable query templates. These features reduce the time required to perform common database operations and improve overall productivity.
In collaborative environments, consistent tools and workflows also help standardize database operations across teams. This ensures that all team members follow similar processes when interacting with databases.
Role of Lightweight Clients in Agile Development Practices
Agile development practices emphasize rapid iteration, continuous testing, and quick feedback cycles. Lightweight database clients align well with these principles by providing fast and flexible access to data systems.
These tools enable developers to quickly test database changes, validate queries, and analyze results without complex setup processes. This supports faster development cycles and improves overall system responsiveness.
By reducing the overhead associated with database management, lightweight clients allow development teams to focus more on application logic and feature development.
Integration with Modern Development Toolchains
Modern development environments often include integrated toolchains that combine code editors, version control systems, and database clients. Sqlectron can be used alongside these tools to provide a complete development workflow.
This integration allows developers to manage application code and database operations within a unified environment. It improves efficiency by reducing context switching between different tools and platforms.
Database clients also support collaboration by allowing multiple users to access shared database environments. This is particularly useful in team-based development projects where consistent data access is required.
Data Analysis and Visualization Support in Database Clients
While Sqlectron primarily focuses on query execution and database management, it also supports basic data visualization through tabular result displays. These visual representations help users analyze query results more effectively.
Data analysis in database clients involves retrieving structured information and interpreting patterns within datasets. Although advanced analytics are typically performed using specialized tools, database clients provide the foundational layer for data exploration.
By enabling quick access to raw data, these tools support early-stage analysis and validation processes in data-driven workflows.
Importance of Unified Database Access in Modern Systems
Unified database access tools play a crucial role in simplifying complex data environments. They reduce the need for multiple specialized applications and provide a consistent interface for managing diverse systems.
This unified approach improves efficiency, reduces training requirements, and enhances operational consistency across organizations. It also supports better data governance by centralizing database interaction within a single controlled environment.
As data ecosystems continue to grow in complexity, the importance of unified database access tools will continue to increase, making them a key component of modern data infrastructure strategies.
Conclusion
The evolution of database systems and the tools used to manage them reflects the broader transformation of how modern organizations handle data at scale. From early file-based storage systems to highly structured relational database management systems, the journey has been driven by the increasing demand for accuracy, efficiency, and scalability in data processing. Today, systems like MySQL represent a mature and widely trusted approach to managing structured data, while tools such as lightweight SQL clients demonstrate how usability and accessibility have become equally important in database workflows.
At the core of this ecosystem is the relational model, which continues to serve as the foundation for a vast majority of enterprise and web-based applications. Its structured approach to organizing data into tables, enforcing relationships through keys, and maintaining strict integrity rules ensures that data remains consistent even in highly complex environments. This structure is particularly important in scenarios where multiple applications depend on the same underlying datasets, as it reduces redundancy and prevents inconsistencies that could otherwise compromise system reliability.
SQL remains one of the most influential technologies in this space. Its standardized syntax and powerful query capabilities allow users to interact with data in a precise and controlled manner. Over time, SQL has evolved to support increasingly sophisticated operations, enabling not only basic data retrieval but also complex analytical processing across large datasets. Its role as a universal language for relational databases ensures interoperability between systems and reduces the learning curve for professionals working across different platforms.
MySQL, as one of the most widely adopted relational database systems, exemplifies the balance between performance, reliability, and accessibility. Its architecture is designed to handle a wide range of workloads, from small applications to large-scale enterprise systems. The modular design, which separates query processing from storage management, allows it to remain flexible and efficient under varying conditions. Features such as indexing, caching, and replication contribute to its ability to maintain high performance even under heavy traffic loads. This makes it a preferred choice for systems that require consistent uptime and fast response times.
Another important aspect of modern database systems is their ability to scale effectively. As data volumes continue to grow exponentially, scalability becomes a critical requirement. MySQL supports both vertical and horizontal scaling strategies, allowing systems to adapt to increasing demands without requiring complete architectural redesigns. Replication mechanisms further enhance scalability by distributing workloads across multiple servers, ensuring that no single system becomes a bottleneck.
Security and data integrity are equally central to the success of any database system. Modern implementations include robust authentication mechanisms, encryption protocols, and access control systems that ensure only authorized users can interact with sensitive data. These security layers are essential in protecting against unauthorized access, data breaches, and corruption. In addition, transaction management systems ensure that data operations remain consistent even in the event of system failures, preserving the reliability of stored information.
While database systems provide the foundational infrastructure, management tools play a crucial role in making these systems usable and efficient. The rise of graphical and cross-platform SQL clients reflects the need for simplified interaction models in increasingly complex environments. These tools abstract much of the underlying complexity of database systems, allowing users to focus on data analysis and query execution rather than system configuration.
Lightweight clients such as Sqlectron illustrate this shift toward simplicity and efficiency. By providing a unified interface for multiple database systems, they eliminate the need for separate tools for each platform. This not only reduces operational complexity but also improves productivity by allowing users to manage diverse environments from a single application. The ability to connect to multiple databases simultaneously is particularly valuable in modern development workflows, where applications often rely on different data sources.
The flexibility offered by such tools extends beyond simple connectivity. Features such as query editors, result visualization, and saved connections enhance the overall workflow experience. Developers and database administrators can quickly test queries, analyze results, and switch between environments without disrupting their workflow. This level of efficiency is especially important in agile development environments, where rapid iteration and continuous feedback are essential.
Another important benefit of these tools is their support for both graphical and terminal-based interfaces. This dual approach caters to a wide range of users, from those who prefer visual interaction to those who rely on command-line efficiency. Terminal-based interfaces also enable automation and scripting, which are critical for large-scale database operations and repetitive tasks. This flexibility ensures that users can choose the most appropriate interface based on their specific requirements and working style.
As data ecosystems continue to expand, the importance of unified database management tools becomes increasingly evident. Organizations are no longer confined to a single database technology but instead operate across multiple systems that serve different purposes. In such environments, the ability to manage all databases through a single interface becomes a significant advantage. It reduces training requirements, simplifies workflows, and ensures consistency across operations.
The integration of database clients into modern development environments further enhances their value. By allowing seamless interaction between application code and database systems, these tools support more efficient development processes. Developers can test queries directly within their workflow, validate data structures, and debug issues without switching between multiple applications. This integration improves both speed and accuracy in software development cycles.
Beyond operational efficiency, database management tools also contribute to better data understanding. By providing structured views of database schemas and query results, they help users interpret complex datasets more effectively. This is particularly useful in data analysis and reporting scenarios, where clarity and accuracy are essential. Even though advanced analytics often require specialized tools, database clients provide the foundational layer for exploring and validating data.
The continued evolution of database systems and management tools reflects the broader shift toward data-centric computing. As organizations increasingly rely on data to drive decisions, the need for efficient, scalable, and user-friendly database solutions becomes more critical. Relational database systems like MySQL, combined with modern SQL clients, form a powerful ecosystem that supports this transformation.
Ultimately, the strength of modern database environments lies in their ability to balance complexity with usability. While underlying systems are highly sophisticated and capable of handling massive workloads, the tools used to interact with them are designed to simplify access and improve efficiency. This balance ensures that both technical experts and general users can work effectively with data, regardless of the complexity of the underlying infrastructure.