Modern cloud systems are built on distributed architectures where applications depend on multiple services working together across compute, storage, networking, and identity layers. While this structure improves scalability and availability, it also introduces complexity. As complexity increases, so does the likelihood of unexpected behavior during partial system failures. In real-world environments, failures rarely occur in isolation; instead, they appear as cascading issues affecting multiple components at once. This makes resilience testing a critical requirement for maintaining stable production systems.
Traditional testing approaches, such as unit testing and integration testing, are effective for validating functional correctness, but they do not fully simulate real infrastructure disruptions. In production environments, issues such as sudden traffic spikes, regional network delays, service throttling, or instance termination can occur without warning. These conditions require a different testing philosophy that goes beyond correctness and focuses on system behavior under stress conditions. This is where chaos engineering principles become relevant, encouraging teams to intentionally introduce controlled failures to observe system responses.
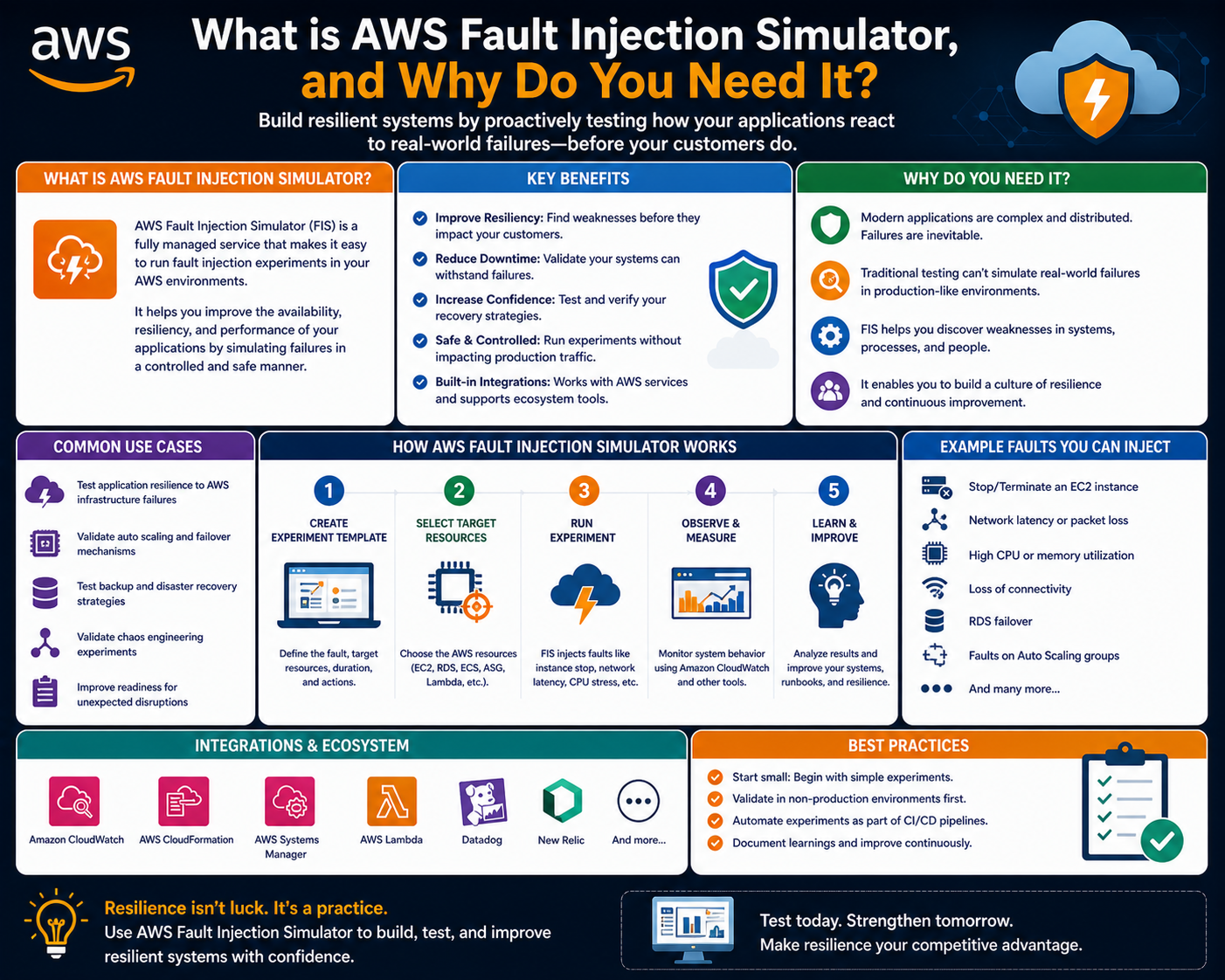
Introduction to AWS Fault Injection Simulator in Cloud Testing
AWS Fault Injection Simulator is a managed service designed to introduce controlled disruptions into cloud environments. It allows engineers to simulate real-world failure scenarios in a safe and structured manner. The purpose is not to break systems randomly but to validate how applications respond when underlying infrastructure components behave unpredictably.
Instead of waiting for real outages to discover weaknesses, organizations can proactively inject faults and measure system responses. This approach helps identify hidden dependencies, bottlenecks, and misconfigurations before they impact end users. The service operates within a controlled boundary where experiments are carefully defined, executed, and monitored.
By using structured experiment definitions, teams can replicate scenarios such as delayed network responses, sudden termination of compute instances, or temporary unavailability of service endpoints. These simulations provide insight into recovery mechanisms, failover strategies, and redundancy effectiveness across the architecture.
Key Objectives of Controlled Failure Testing
The primary goal of controlled failure testing is to improve system reliability under adverse conditions. Cloud applications are typically designed with redundancy, but redundancy alone does not guarantee resilience. It is important to verify whether fallback mechanisms actually function as expected when activated.
Another objective is to evaluate observability. Systems must not only handle failures but also report them accurately. If monitoring systems fail to detect issues, recovery becomes significantly more difficult. Controlled experiments help validate whether metrics, logs, and alarms are properly configured and responsive.
A third objective is to understand dependency chains. In large-scale environments, one service often relies on several others. A failure in a low-level service can cascade upward, impacting multiple application layers. Fault injection testing reveals these hidden relationships and helps engineers redesign systems to minimize risk.
Common Failure Scenarios in Distributed Systems
In cloud environments, several categories of failures are commonly simulated to evaluate resilience. One of the most frequent scenarios involves network disruption. This includes introducing latency, packet loss, or a complete communication breakdown between services. Such conditions help determine how applications behave when connectivity becomes unreliable.
Another important scenario involves compute instance instability. Virtual machines may stop unexpectedly due to maintenance, scaling events, or hardware issues. Simulating instance shutdowns or reboots allows teams to evaluate whether auto-recovery mechanisms, load balancers, and redundancy configurations function correctly.
DNS-related failures are also significant in distributed systems. If domain resolution becomes slow or unavailable, applications may experience widespread service degradation even if backend systems remain operational. Testing DNS failures helps validate caching strategies and fallback resolution mechanisms.
Storage and database-related disruptions can also be introduced to examine how applications handle data access delays or temporary unavailability. These tests help ensure that retry logic, buffering mechanisms, and data consistency models are robust under stress.
Role of Experiment Design in Fault Injection
A structured experiment is the foundation of controlled failure testing. Each experiment defines the scope, target resources, and type of disruption being introduced. Without careful design, fault injection can become unpredictable and potentially disruptive.
Experiment design typically begins with identifying a specific system behavior to evaluate. This could involve testing response time under network delay or verifying failover behavior during instance termination. Once the objective is clear, engineers define the affected components and the nature of the fault.
Targets are selected based on resource attributes such as instance identifiers, service roles, or environment tags. This allows precise control over which parts of the system are affected. Actions define the type of disruption, such as stopping instances or injecting latency.
By structuring experiments in this way, teams ensure repeatability. Each test can be executed multiple times under consistent conditions, making it easier to compare results and track improvements over time.
Importance of Controlled Environment Execution
Running failure simulations in a controlled environment is essential to avoid unintended impact on production workloads. Experiments are typically scoped to specific resources or environments where disruption will not affect real users.
Isolation mechanisms ensure that only targeted components are affected. This prevents system-wide outages while still allowing realistic testing conditions. Controlled execution also ensures that experiments can be stopped immediately if unexpected behavior occurs.
Monitoring plays a key role during execution. Metrics are collected in real time to observe system performance under stress. This includes response times, error rates, CPU utilization, and network throughput. These indicators help determine whether the system is degrading gracefully or failing unexpectedly.
Observability as a Core Component of Resilience Testing
Observability is a critical part of any fault injection process. Without proper monitoring, it becomes impossible to understand how systems respond to failures. Observability tools provide visibility into system behavior during experiments, enabling teams to analyze performance and detect anomalies.
Metrics-based monitoring tracks numerical data such as latency, request counts, and error percentages. Log-based monitoring captures detailed event records that provide context for system behavior. Trace-based monitoring helps visualize request flows across distributed services.
When combined, these observability layers provide a comprehensive view of system health. During fault injection experiments, they help identify whether systems are recovering as expected or exhibiting degradation patterns.
Alerting mechanisms also play a role in resilience validation. Properly configured alerts should trigger when system performance crosses defined thresholds. Testing these alerts ensures that operational teams are notified immediately during real incidents.
Experiment Templates and Standardized Testing Models
To simplify the process of designing experiments, predefined templates are often used. These templates define common failure scenarios in a reusable format. They include predefined targets, actions, and conditions that can be adapted to different environments.
Templates help standardize testing across teams and environments. Instead of designing each experiment from scratch, engineers can reuse proven configurations. This reduces complexity and improves consistency in testing practices.
Each template can be modified to match specific system requirements. Parameters such as affected resources, duration, and severity level can be adjusted to reflect realistic production conditions. This flexibility allows teams to scale their testing efforts as systems evolve.
Expanding Experiment Complexity in Cloud Resilience Testing
As cloud environments mature, resilience testing evolves from simple fault scenarios into complex, multi-layered experiments. Initial testing often focuses on isolated components such as a single compute instance or a basic network delay simulation. However, real production systems rarely fail in isolation. Instead, they experience interconnected disruptions that propagate across services.
Advanced experimentation involves combining multiple failure types within a single controlled test. For example, a system might experience simultaneous network latency and partial compute disruption. This type of scenario helps reveal how services behave when multiple stress factors interact. It also exposes hidden dependencies that are not visible during isolated testing.
Increasing complexity requires careful structuring of experiments. Each additional failure condition must be introduced in a controlled sequence. Timing, duration, and intensity of faults must be carefully calibrated to avoid overwhelming the system beyond meaningful analysis. The goal is not destruction but insight into system behavior under layered stress conditions.
Designing Multi-Component Failure Scenarios
Modern cloud applications often consist of microservices that communicate through APIs, queues, and event-driven architectures. In such environments, a single service failure can propagate across multiple layers. Multi-component failure scenarios are designed to simulate this behavior.
For instance, a database slowdown can be combined with increased API latency to evaluate how upstream services handle delayed responses. Similarly, a compute instance failure can be paired with load balancer rerouting delays to observe traffic redistribution behavior. These combinations provide deeper insights into system resilience than single-point tests.
Designing such scenarios requires a clear mapping of service dependencies. Engineers must understand which components rely on others and how data flows between them. Dependency mapping helps ensure that failure injection targets meaningful paths within the architecture rather than random components.
Controlled Chaos and System Stability Balance
A key principle in advanced resilience testing is maintaining a balance between chaos and control. While the objective is to introduce failures, the environment must remain stable enough to observe meaningful outcomes. Excessive disruption can obscure insights and make analysis difficult.
Controlled chaos is achieved through carefully defined boundaries. Experiments are limited to specific resource groups, time windows, and severity levels. This ensures that while systems are stressed, they remain observable and recoverable. The controlled nature of these experiments allows teams to repeat tests under consistent conditions, enabling comparative analysis over time.
Another important aspect is rollback capability. Experiments must include mechanisms to immediately stop or reverse injected faults. This ensures that unintended behavior does not escalate beyond the test scope. Rapid recovery mechanisms are essential for maintaining safe testing environments.
Automation in Fault Injection Workflows
Automation plays a central role in modern resilience testing strategies. Manual execution of experiments is inefficient and does not scale well in large environments. Automated workflows allow experiments to be executed consistently, repeatedly, and on schedule without human intervention.
One common automation approach involves event-driven execution. In this model, scheduled triggers initiate experiments at predefined intervals. This allows resilience testing to become a continuous process rather than a one-time activity. Automated scheduling ensures that systems are regularly validated under varying conditions.
Another approach involves integrating fault injection into deployment pipelines. In this model, experiments are executed as part of application release processes. Before new code is promoted to production, resilience tests are run to validate system stability. This ensures that newly deployed changes do not introduce hidden vulnerabilities.
Automation can also be achieved through programmatic execution using software development kits. Scripts can define experiment parameters and trigger execution dynamically. This approach provides flexibility and allows experiments to be customized based on real-time conditions or system metrics.
Event-Driven Resilience Testing Architecture
Event-driven architectures provide a powerful foundation for automated fault injection. In such systems, events trigger workflows that execute predefined experiments. These events can originate from scheduling systems, monitoring alerts, or external triggers.
For example, a monitoring system might detect increased latency in a service and automatically trigger a latency injection experiment in a related component. This helps validate whether the observed issue is isolated or part of a broader systemic problem.
Event-driven testing enables adaptive resilience validation. Instead of relying solely on scheduled tests, systems can respond dynamically to operational conditions. This creates a continuous feedback loop where real-world behavior informs testing strategies.
Integration with Observability Systems
Observability is deeply integrated into advanced resilience testing workflows. Without proper visibility, experiments cannot provide actionable insights. Observability systems collect and analyze data during fault injection, enabling engineers to understand system behavior in real time.
Metrics collection is one of the primary observability mechanisms. Key performance indicators such as latency, error rates, and throughput are continuously monitored during experiments. These metrics help determine whether systems degrade gracefully or fail abruptly.
Log aggregation provides detailed contextual information about system behavior. Logs capture events such as request failures, retries, and service interruptions. During experiments, logs help trace the sequence of events leading to observed outcomes.
Distributed tracing adds another layer of visibility by tracking requests across multiple services. This is particularly important in microservices architectures where a single request may pass through multiple components. Tracing helps identify where delays or failures originate.
Real-Time Monitoring During Fault Injection
Real-time monitoring is essential during resilience testing because it allows immediate observation of system behavior under stress. As experiments run, monitoring dashboards display live metrics that reflect system performance.
This real-time feedback helps engineers determine whether the experiment is producing expected results. If system behavior deviates from expectations, adjustments can be made immediately. This dynamic feedback loop improves the accuracy and effectiveness of testing.
Alert systems also play a critical role during execution. Alerts are configured to trigger when specific thresholds are exceeded. For example, if error rates spike beyond acceptable levels, alerts notify engineers instantly. This ensures rapid response during unexpected behavior.
Adaptive Thresholds and Intelligent Alerting
In advanced environments, static alert thresholds are often insufficient. Instead, adaptive thresholds are used to account for dynamic system behavior. These thresholds adjust based on historical performance data and current workload conditions.
During fault injection experiments, adaptive alerting helps distinguish between expected degradation and critical failures. Not all performance changes indicate a problem; some may be expected responses to simulated conditions. Intelligent alerting systems help reduce noise and improve signal accuracy.
Machine learning techniques are sometimes applied to enhance alerting systems. By analyzing historical experiment data, systems can predict expected behavior patterns and identify anomalies more accurately.
Experiment Lifecycle Management
Every resilience test follows a structured lifecycle that includes planning, execution, monitoring, and analysis. Proper lifecycle management ensures that experiments are conducted systematically and results are actionable.
The planning phase involves defining objectives, selecting targets, and designing fault scenarios. This phase is critical because poorly defined experiments produce unclear results. Clear objectives ensure that experiments generate meaningful insights.
Execution involves running the experiment under controlled conditions. During this phase, monitoring systems collect real-time data. Engineers observe system behavior and ensure that experiments remain within defined boundaries.
After execution, data analysis begins. This involves reviewing metrics, logs, and traces to understand system performance. Patterns are identified, and weaknesses are documented for future improvement.
Failure Isolation and Blast Radius Control
One of the most important aspects of resilience testing is controlling the blast radius of failures. Blast radius refers to the extent of impact caused by a simulated fault. Minimizing blast radius ensures that experiments remain safe and controlled.
Failure isolation techniques are used to restrict the scope of impact. These techniques ensure that only selected components are affected by injected faults. Isolation can be achieved through tagging, resource grouping, or environment segmentation.
Controlled blast radius allows engineers to test real failure scenarios without risking widespread disruption. It ensures that experiments remain safe even when simulating high-severity conditions.
Role of Continuous Resilience Validation
Resilience testing is not a one-time activity but a continuous process. As systems evolve, new dependencies are introduced, and existing architectures change. Continuous validation ensures that systems remain resilient over time.
Regular experimentation helps detect regression issues early. When new updates are deployed, resilience tests confirm that existing stability is not compromised. This continuous feedback loop improves system reliability and operational confidence.
Continuous validation also supports long-term architectural improvement. By analyzing trends across multiple experiments, engineers can identify recurring weaknesses and prioritize system enhancements.
Scaling Resilience Testing Across Large Environments
In large-scale cloud environments, resilience testing must be scalable. Systems may consist of hundreds or thousands of services, making manual testing impractical. Scalable testing strategies rely on automation, templates, and modular experiment design.
Templates allow the reuse of standardized test scenarios across different environments. This reduces duplication and ensures consistency. Modular design enables experiments to be combined and reused in different configurations.
Scalability also requires efficient resource management. Experiments must be designed to avoid unnecessary resource consumption while still producing meaningful results.
Transitioning from Testing Theory to Production Reality
As cloud systems evolve into large-scale distributed environments, resilience testing moves beyond structured experiments and into real-world operational validation. At this stage, the focus shifts from understanding isolated failures to ensuring that entire ecosystems can withstand unpredictable production conditions. Systems are no longer evaluated in controlled lab-like scenarios alone but are continuously assessed against realistic operational patterns.
Production environments introduce variables that cannot always be fully replicated in isolated testing. These include fluctuating traffic loads, regional service disruptions, dependency degradation, and unpredictable user behavior. Fault injection practices in this phase are designed to reflect these realities as closely as possible without disrupting end-user experience.
The goal is to ensure that systems behave predictably even when individual components fail unexpectedly. This requires careful orchestration of experiments, strict governance over execution boundaries, and continuous validation of recovery mechanisms.
Advanced Orchestration of Multi-Service Experiments
In complex cloud architectures, applications are composed of interconnected services spanning compute, storage, networking, messaging, and security layers. Advanced orchestration focuses on coordinating fault injection across multiple services simultaneously.
Instead of running isolated tests, orchestrated experiments simulate cascading failures. For example, a compute instance delay may be combined with increased database latency and partial API throttling. This allows engineers to evaluate how service chains respond when multiple dependencies degrade at once.
Orchestration also involves sequencing failures in a controlled order. A network disruption might be introduced first, followed by compute instability, and then storage delays. This sequencing helps reveal how systems prioritize recovery actions and whether fallback mechanisms activate in the correct order.
Coordinating such experiments requires precise timing control. Each failure condition must be activated and deactivated based on predefined triggers. This ensures that experiments remain structured and their outcomes can be accurately interpreted.
Dependency Mapping for Large-Scale Systems
A critical requirement for advanced resilience testing is understanding service dependencies. In large distributed environments, services rarely operate independently. Instead, they rely on complex chains of communication and shared resources.
Dependency mapping involves identifying how data flows across services and which components rely on others. This mapping forms the foundation for designing meaningful fault injection scenarios. Without it, experiments risk targeting irrelevant components that do not reflect real operational risk.
In production systems, dependency maps are often dynamic. Services scale, evolve, and change relationships over time. Continuous mapping ensures that resilience testing remains aligned with the current architecture rather than outdated assumptions.
When dependencies are well understood, fault injection experiments become significantly more effective. Engineers can simulate realistic failure chains and observe how disruptions propagate through the system.
Production-Safe Chaos Engineering Practices
Running resilience experiments in production environments requires strict safety controls. The objective is to validate system behavior without causing user-facing outages. This balance between realism and safety is achieved through carefully defined constraints.
One important practice is limiting the blast radius. Only a small subset of resources is targeted during any experiment. This ensures that even if unexpected behavior occurs, the impact remains contained.
Another practice involves gradual fault introduction. Instead of injecting full-scale failures immediately, disruptions are increased incrementally. This allows systems to adjust and provides early warning signals if instability begins to emerge.
Time-bound execution is also essential. Experiments are scheduled for fixed durations and automatically terminated after completion. This prevents prolonged exposure to failure conditions and ensures predictable recovery.
Integration with Production Monitoring Systems
In production environments, monitoring systems play a central role in resilience validation. These systems continuously collect data on performance, availability, and system health. During fault injection experiments, monitoring becomes even more critical.
Metrics such as response time, error rates, and resource utilization are tracked in real time. These indicators help determine whether systems are degrading gracefully or failing abruptly. Observability data provides immediate feedback on experiment impact.
Log systems capture detailed operational events during experiments. These logs help reconstruct system behavior and identify the exact sequence of events leading to observed outcomes. This is especially useful in distributed systems where multiple services interact simultaneously.
Tracing systems provide end-to-end visibility into request flows. They allow engineers to follow a single request across multiple services and identify where delays or failures occur. This is essential for diagnosing complex cascading failures.
Automated Recovery Validation
A key objective of resilience testing is to validate recovery mechanisms. Modern cloud systems are designed with self-healing capabilities such as auto-scaling, failover routing, and redundant service deployment. Fault injection helps verify whether these mechanisms function correctly under stress.
When a failure is introduced, systems are expected to detect the issue and initiate recovery actions automatically. These may include restarting instances, rerouting traffic, or activating backup resources. Observing these behaviors during experiments confirms whether recovery logic is correctly implemented.
Recovery validation also includes measuring recovery time. How quickly a system returns to normal operation after a failure is a critical metric. Slow recovery can indicate inefficiencies in design or misconfigured automation rules.
Continuous Resilience Engineering in Development Cycles
Resilience testing is most effective when integrated into regular development cycles. Instead of being treated as a separate activity, it becomes part of continuous delivery and deployment processes.
Before new code is released, automated resilience tests validate system stability under failure conditions. This ensures that new changes do not introduce unexpected vulnerabilities. By embedding resilience testing into development workflows, teams reduce the risk of production incidents.
Continuous testing also enables early detection of architectural weaknesses. As systems evolve, new dependencies and interactions are introduced. Regular experiments ensure that these changes do not degrade system resilience over time.
Failure Simulation in Microservices Architectures
Microservices architectures are particularly well-suited for fault injection testing because of their modular structure. Each service operates independently but communicates with others through well-defined interfaces.
Failure simulation in microservices environments often focuses on communication breakdowns. This includes delayed responses, dropped requests, or partial service unavailability. These scenarios help evaluate how services handle unreliable dependencies.
Another important aspect is service degradation behavior. Instead of failing, services may operate in degraded mode when dependencies are unavailable. Testing this behavior ensures that applications continue functioning at reduced capacity rather than failing.
Microservices environments also benefit from testing retry mechanisms. When services fail temporarily, retry logic determines whether requests are reattempted or discarded. Fault injection helps validate whether retry strategies are appropriate and do not cause excessive load.
Distributed System Stability Under Stress Conditions
Distributed systems are inherently vulnerable to partial failures. Unlike monolithic systems, where failure is often localized, distributed systems can experience uneven degradation across components.
Stress testing distributed systems involves simulating high-load conditions combined with partial failures. This helps evaluate how systems prioritize resources and maintain availability under pressure.
Load-balancing behavior is also tested under stress conditions. When some nodes fail or slow down, traffic must be redistributed efficiently. Fault injection helps ensure that load balancers respond correctly to changing conditions.
Real-Time Decision Making During Experiments
Advanced resilience testing often involves real-time decision-making. As experiments run, engineers monitor system behavior and adjust parameters dynamically if needed.
If unexpected instability is detected, experiments can be modified or terminated immediately. This flexibility ensures that testing remains safe while still providing valuable insights.
Real-time adjustments may include reducing fault intensity, narrowing the target scope, or extending observation periods. These decisions are guided by observability data collected during execution.
Long-Term Resilience Strategy Development
Resilience testing is not just about individual experiments but about building long-term system stability strategies. Over time, repeated testing reveals patterns of weakness and strength within the architecture.
These insights guide architectural improvements such as redundancy enhancements, improved failover logic, and optimized service communication patterns. Systems evolve based on empirical evidence gathered through controlled experimentation.
Long-term strategies also involve refining monitoring and alerting systems. As new failure modes are discovered, monitoring rules are updated to detect them more effectively in real-world conditions.
Organizational Adoption of Chaos Engineering Practices
Adopting resilience testing practices at an organizational level requires cultural and operational alignment. Teams must embrace the idea that controlled failure is a necessary part of building robust systems.
This shift involves integrating testing responsibilities into development, operations, and security teams. Collaboration ensures that experiments reflect real-world operational challenges and system dependencies.
Documentation and knowledge sharing are also important. Insights from experiments must be recorded and communicated across teams to ensure continuous improvement.
Conclusion
In modern cloud computing environments, system reliability is no longer defined only by how well applications perform under normal conditions, but by how predictably they behave when something goes wrong. Distributed architectures, microservices-based designs, and multi-layered infrastructure stacks have introduced an unprecedented level of complexity. While this complexity enables scalability, flexibility, and global reach, it also increases the number of potential failure points. In such environments, traditional testing methods alone are not sufficient to ensure stability. Controlled failure testing through fault injection has therefore become an essential practice for understanding and strengthening system behavior under stress.
The core value of resilience testing lies in shifting the mindset from reactive troubleshooting to proactive validation. Instead of waiting for production incidents to reveal weaknesses, systems are deliberately exposed to controlled disruptions in advance. This approach allows engineers to uncover hidden dependencies, misconfigured recovery mechanisms, and unexpected failure cascades before they affect real users. Over time, this significantly reduces the frequency and severity of outages, while also improving overall system confidence.
One of the most important insights gained through fault injection practices is the realization that failure is not an exception in distributed systems; it is an expected condition. Network latency, service degradation, hardware instability, and partial outages are normal occurrences in large-scale environments. The real challenge is not eliminating failure, but ensuring that systems degrade gracefully and recover efficiently. Resilience engineering focuses on designing systems that continue functioning even when individual components become unreliable.
As organizations adopt these practices more deeply, they begin to understand the importance of observability as a foundational requirement rather than an optional enhancement. Without visibility into system behavior, fault injection experiments lose their value. Metrics, logs, and traces provide the necessary context to interpret how systems respond under stress. They reveal whether failures are isolated or cascading, whether recovery mechanisms are effective, and whether performance degradation follows expected patterns. Observability transforms raw experiment data into actionable insights that guide architectural improvements.
Another critical outcome of resilience testing is improved understanding of system dependencies. In complex architectures, services rarely operate in isolation. A single user request may pass through multiple services, databases, caches, and external integrations. Fault injection experiments expose these relationships by revealing how failures in one component affect others. This dependency awareness is essential for designing systems that are not overly reliant on any single point of failure.
Over time, organizations that consistently apply resilience testing practices begin to develop more robust engineering cultures. Teams move away from assuming ideal system behavior and instead design for unpredictability. This cultural shift encourages better architectural decisions, such as implementing redundancy, designing fallback mechanisms, and minimizing tight coupling between services. It also promotes accountability, as teams gain a clearer understanding of how their services behave under real-world stress conditions.
Automation plays a significant role in scaling these practices. Manual testing alone cannot keep up with the speed and complexity of modern cloud deployments. Automated resilience testing allows experiments to be executed regularly, consistently, and across multiple environments without human intervention. This ensures that resilience validation becomes an ongoing process rather than a one-time activity. When integrated into deployment pipelines, it also ensures that every change to the system is evaluated not only for functionality but also for stability under failure conditions.
Another important benefit of continuous resilience testing is early detection of regressions. As systems evolve, new features, dependencies, and configurations are introduced. Without regular validation, these changes can unintentionally weaken system resilience. Automated fault injection helps detect these issues early by continuously challenging the system under controlled stress conditions. This reduces the likelihood of unexpected production failures and improves long-term stability.
From an operational perspective, resilience testing also strengthens incident response capabilities. By simulating failure scenarios in advance, teams become better prepared to handle real incidents. They gain familiarity with system behavior under stress, understand recovery procedures, and identify gaps in monitoring or alerting systems. This leads to faster response times and more effective resolution strategies during actual outages.
In addition to operational benefits, fault injection practices also contribute to better capacity planning. By observing how systems behave under simulated stress, engineers can identify performance bottlenecks and scalability limitations. This information helps in making informed decisions about resource allocation, scaling strategies, and infrastructure optimization. As a result, systems become not only more resilient but also more efficient.
It is also important to recognize that resilience testing is not a one-time engineering milestone but an ongoing discipline. Cloud environments are constantly evolving, and new risks emerge as systems grow in scale and complexity. Continuous experimentation ensures that resilience keeps pace with these changes. It creates a feedback loop where real system behavior informs future design decisions, leading to gradual but consistent improvement over time.
At a broader level, the adoption of fault injection and chaos engineering practices reflects a mature approach to cloud architecture design. Instead of focusing solely on preventing failure, organizations acknowledge that failure is inevitable and design systems that can withstand it. This mindset leads to more resilient, adaptive, and reliable infrastructures capable of supporting mission-critical workloads.
Ultimately, resilience engineering through controlled fault injection strengthens both technical systems and organizational readiness. It improves system reliability, enhances observability, validates recovery mechanisms, and builds confidence in production environments. More importantly, it fosters a culture where systems are continuously tested against reality rather than assumptions. In an era where digital infrastructure underpins nearly every aspect of business and communication, this proactive approach to reliability becomes not just beneficial but essential for long-term success.
As systems continue to scale across multiple regions, availability zones, and hybrid environments, the importance of anticipating failure rather than reacting to it becomes even more significant. Modern applications are expected to remain available under increasingly demanding conditions, including sudden traffic surges, partial service outages, and unpredictable network behavior. Without structured resilience validation, even well-designed architectures can reveal hidden weaknesses only after impacting end users. Controlled fault injection reduces this uncertainty by exposing vulnerabilities in a safe, repeatable, and measurable way.
Another important aspect is the way resilience practices improve engineering decision-making over time. When teams regularly observe how systems behave under stress, they begin to make more informed architectural choices. Instead of optimizing solely for performance or cost, they also prioritize fault tolerance, graceful degradation, and recovery speed. This leads to more balanced system designs where reliability is treated as a core requirement rather than an afterthought.