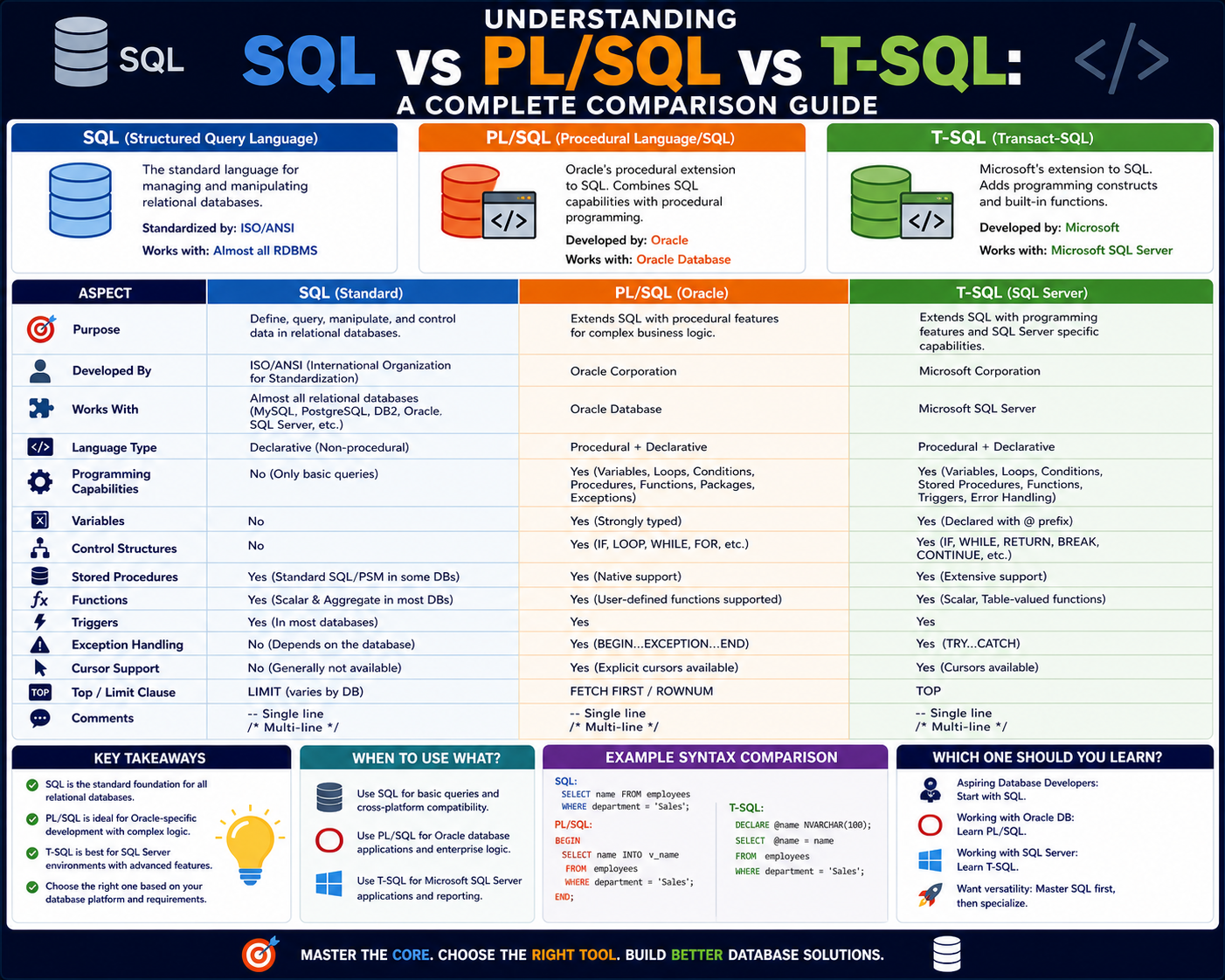
Relational database systems are the core infrastructure behind most modern software applications that handle structured data. Whether it is financial systems, e-commerce platforms, analytics dashboards, or enterprise applications, relational databases provide a reliable and organized way to store and retrieve information. At the heart of these systems lies SQL, a language that has shaped data management practices for decades. To understand SQL and its extended dialects, such as PL/SQL and T-SQL, it is important to first understand how relational databases operate and why SQL became the standard interface for interacting with them.
What SQL Is and Why It Was Created
SQL, or Structured Query Language, was designed as a standardized way to interact with relational databases. It was influenced by the relational model of data, which organizes information into tables made up of rows and columns. Each table represents a specific entity, such as customers or orders, while rows represent individual records and columns define attributes of those records.
The primary goal of SQL was to simplify data interaction. Instead of writing complex low-level instructions, developers could use a structured language to describe what data they needed. This made database interaction more efficient and accessible, allowing both developers and analysts to work with data more effectively.
The Declarative Nature of SQL
One of the most important characteristics of SQL is that it is declarative rather than procedural. In procedural languages, developers must define step-by-step instructions for how a task should be performed. SQL, on the other hand, focuses on what result is needed rather than how to achieve it.
For example, instead of writing logic to loop through records and filter data manually, a SQL query simply defines the conditions that the data must meet. The database engine then determines the most efficient way to execute that query. This abstraction significantly reduces complexity and allows developers to focus on business logic rather than implementation details.
Core Components of SQL: DDL and DML
SQL is generally divided into two main components that serve different purposes in database management.
The first is Data Definition Language, commonly known as DDL. This part of SQL is responsible for defining and managing the structure of database objects. It includes commands that create, modify, and delete tables, indexes, and other schema elements. Through DDL, developers establish the structure that governs how data is stored and organized.
DDL ensures that databases have a well-defined structure. It allows constraints such as primary keys and foreign keys to be implemented, which help maintain relationships and ensure data consistency across tables.
The second component is Data Manipulation Language, known as DML. This part focuses on working with the actual data stored in the database. It includes operations such as retrieving records, inserting new data, updating existing entries, and deleting records that are no longer needed.
DML is the most frequently used part of SQL because it directly interacts with the data used by applications and users. Together, DDL and DML form the foundation of SQL functionality.
Limitations of Standard SQL in Complex Applications
While SQL is highly effective for structured data operations, it has limitations when it comes to complex business logic. SQL was originally designed to work with sets of data rather than procedural workflows. This means it is not naturally suited for tasks that require loops, conditional branching, or advanced computations.
As applications became more complex, developers needed a way to perform more advanced operations directly within the database. Relying solely on external application code created inefficiencies and increased complexity, especially when handling large volumes of data.
Emergence of Stored Procedures
To address these limitations, database systems introduced stored procedures. A stored procedure is a precompiled set of SQL statements stored inside the database server. These procedures can include both SQL commands and procedural logic.
Stored procedures allow developers to execute complex operations directly within the database environment. This reduces the need for repeated communication between the application and the database, improving performance and reducing network overhead. It also enables better encapsulation of business logic at the database level.
Evolution of SQL into Vendor-Specific Extensions
As the need for more advanced functionality grew, database vendors began extending SQL with proprietary features. These extensions introduced procedural capabilities such as variables, loops, conditionals, and error handling.
Although SQL has a standardized version defined by international organizations, each database system has its own implementation with additional features. These differences allow vendors to optimize performance and add functionality, but they also lead to variations in syntax and behavior across platforms.
This evolution marked the beginning of SQL dialects, where the core language remains consistent but extensions vary depending on the database system.
Introduction of PL/SQL and T-SQL
Two of the most important SQL dialects that emerged from this evolution are PL/SQL and T-SQL. Both are procedural extensions of SQL designed to overcome its limitations while integrating tightly with their respective database systems.
PL/SQL is associated with Oracle database systems, while T-SQL is used in Microsoft SQL Server environments. Although both languages share similarities in purpose, they differ in design, syntax, and features.
These extensions allow SQL to function not only as a query language but also as a full programming language capable of handling complex logic, error management, and procedural workflows.
Role of Standard SQL in Modern Systems
Despite the rise of extended dialects, standard SQL remains the foundation of relational database interaction. It provides a common language that ensures basic compatibility across different database systems.
Standard SQL focuses on portability and consistency, making it possible to perform core database operations regardless of the underlying platform. However, it deliberately avoids complex procedural features to maintain simplicity and universality.
In real-world systems, developers often use a combination of standard SQL and vendor-specific extensions to balance portability with functionality.
Data Integrity and Structural Control in SQL
SQL plays a crucial role in maintaining data integrity within relational databases. Constraints defined through SQL ensure that data remains accurate, consistent, and logically structured.
Primary keys enforce uniqueness within tables, while foreign keys establish relationships between different tables. Additional constraints, such as not-null rules and unique indexes, further enhance data reliability.
These mechanisms ensure that databases maintain consistency even as data is inserted, updated, or deleted over time.
Security and Access Control in SQL Systems
Security is another important aspect of SQL-based systems. Database management systems implement permission structures that control who can access or modify specific data.
These permissions can be defined at different levels, including tables, schemas, and individual columns. By restricting access based on roles and privileges, SQL systems ensure that sensitive information remains protected while still allowing authorized users to perform necessary operations.
Performance Optimization in SQL Execution
Modern database systems use advanced optimization techniques to execute SQL queries efficiently. When a query is submitted, the database engine analyzes it and determines the most efficient execution plan.
Techniques such as indexing, query rewriting, and execution planning help improve performance. Indexes allow the system to locate data quickly without scanning entire tables, significantly reducing query execution time in large datasets.
These optimizations are largely invisible to developers but play a critical role in system performance and scalability.
Transition Toward Integrated Database Logic
As applications evolved, databases began to take on a more active role in application logic. Instead of serving only as data storage systems, databases now often handle business rules, validation, and transaction processing.
This shift has increased the importance of procedural SQL extensions, which allow logic to be executed directly within the database environment. This integration reduces complexity in application code and improves overall system efficiency.
Foundation for Advanced SQL Dialects
The evolution of SQL from a simple query language into a more complex ecosystem of procedural extensions sets the stage for understanding dialects like PL/SQL and T-SQL. These languages build on the core principles of SQL while introducing additional capabilities tailored to specific database systems.
Understanding these foundations is essential for exploring how different SQL variants operate, how they differ in design, and how they are used in real-world database applications.
Introduction to T-SQL and Its Role in Microsoft SQL Server
T-SQL, short for Transact-SQL, is Microsoft’s proprietary extension of the SQL language used primarily in SQL Server environments. While standard SQL provides a universal way to interact with relational databases, T-SQL expands this foundation to support advanced programming constructs, system-level operations, and tightly integrated database programming within the Microsoft ecosystem.
T-SQL is not just a querying language; it is a full procedural extension that allows developers to build complex logic directly inside the database. It is designed to work seamlessly with Microsoft SQL Server and is the primary language used for database administration, data manipulation, and backend logic execution within this platform.
Unlike standard SQL, which focuses on set-based operations, T-SQL introduces procedural capabilities such as variables, loops, conditional logic, and error handling. These additions make it suitable for developing sophisticated database applications that require logic beyond simple data retrieval and modification.
Origins and Evolution of T-SQL
T-SQL originated from Sybase SQL, a database system developed in collaboration with Microsoft in the early stages of relational database adoption. As Microsoft SQL Server evolved, T-SQL became its core language, diverging from Sybase while incorporating new features tailored to Microsoft’s platform.
Over time, Microsoft enhanced T-SQL to integrate more deeply with the Windows operating system and later with cloud environments such as Azure. This evolution transformed T-SQL into a powerful language that supports both traditional on-premises databases and modern cloud-based data solutions.
Today, T-SQL is a central component of SQL Server development and administration, used by database developers, administrators, and data engineers to manage large-scale systems.
Core Structure and Syntax of T-SQL
T-SQL retains the fundamental structure of SQL but extends it with procedural programming elements. This means that while SELECT, INSERT, UPDATE, and DELETE statements remain central, they can be combined with variables, control-of-flow statements, and batch processing logic.
T-SQL introduces the concept of batches, where multiple statements are grouped and executed together. It also supports scripting capabilities that allow complex operations to be written and executed as a single unit.
This blend of declarative and procedural programming makes T-SQL highly flexible and suitable for a wide range of database tasks.
Procedural Features in T-SQL
One of the defining characteristics of T-SQL is its support for procedural programming constructs. These features allow developers to create logic-based workflows inside the database.
T-SQL includes support for variables, which can store temporary values during execution. These variables enable dynamic data manipulation within scripts and stored procedures.
Conditional logic is implemented through structures that allow decision-making based on specific conditions. This enables branching logic where different operations are performed depending on the state of the data.
Looping constructs are also available, allowing repeated execution of statements. While loops are less commonly used in database design compared to set-based operations, they are useful in specific scenarios that require iterative processing.
Error Handling and Transaction Control in T-SQL
T-SQL provides robust error-handling mechanisms that allow developers to manage exceptions during execution. This is essential for maintaining data integrity and ensuring reliable application behavior.
Error-handling structures allow developers to capture and respond to runtime errors without terminating the entire operation. This makes it possible to implement fallback logic or rollback operations when something goes wrong.
Transaction control is another critical feature of T-SQL. Transactions ensure that a series of operations is executed as a single unit. If any part of the transaction fails, the entire operation can be rolled back to maintain consistency.
This capability is especially important in financial systems, inventory management, and other environments where data accuracy is critical.
Stored Procedures and Functions in T-SQL
Stored procedures are a central feature of T-SQL programming. They are precompiled collections of SQL and procedural statements stored within the database. These procedures can be executed multiple times, improving performance and reusability.
Stored procedures allow developers to encapsulate business logic within the database layer. This reduces redundancy and ensures that complex operations are executed consistently.
T-SQL also supports user-defined functions, which are reusable code blocks that return values. These functions can be used within queries to perform calculations or transformations on data.
The combination of stored procedures and functions makes T-SQL a powerful tool for building modular and maintainable database applications.
System Functions and Built-in Capabilities
T-SQL includes a wide range of built-in functions that extend its functionality beyond basic SQL operations. These functions cover areas such as string manipulation, mathematical calculations, date and time processing, and system metadata access.
These built-in capabilities reduce the need for external processing and allow many operations to be performed directly within the database. This improves performance and simplifies application design.
System functions also provide access to database metadata, allowing developers to retrieve information about tables, indexes, and system configurations.
Integration with the Microsoft Ecosystem
One of the key strengths of T-SQL is its deep integration with the Microsoft ecosystem. It works seamlessly with tools such as SQL Server Management Studio and integrates with programming languages like C#, .NET, and PowerShell.
This integration allows developers to build end-to-end solutions where T-SQL handles data processing while external applications manage user interfaces and business workflows.
T-SQL also integrates with reporting and analytics tools, enabling data extraction and transformation for business intelligence purposes.
T-SQL and Set-Based vs Procedural Thinking
While T-SQL introduces procedural features, it still strongly emphasizes set-based operations. Set-based processing is more efficient in relational databases because it allows operations to be performed on entire datasets rather than individual rows.
However, T-SQL gives developers the flexibility to combine set-based logic with procedural constructs when necessary. This hybrid approach allows for both performance optimization and logical complexity.
Understanding when to use set-based operations versus procedural logic is a key skill in T-SQL development.
Performance Considerations in T-SQL
Performance optimization is an important aspect of T-SQL programming. Since SQL Server is often used in high-performance environments, efficient query design is critical.
T-SQL allows developers to write optimized queries that take advantage of indexing, query execution plans, and caching mechanisms. Poorly written queries can significantly impact performance, especially in large databases.
Stored procedures also contribute to performance improvements by reducing compilation overhead and reusing execution plans.
T-SQL in Modern Cloud Environments
With the rise of cloud computing, T-SQL has evolved to support cloud-based database services. SQL Server in cloud environments retains full T-SQL compatibility, allowing applications to be migrated without major code changes.
Cloud integration introduces additional capabilities such as scalability, automated backups, and distributed processing. T-SQL remains the primary language for interacting with these cloud-based SQL Server instances.
This continuity ensures that developers familiar with T-SQL can transition smoothly into modern cloud architectures.
Security Features in T-SQL
Security is an essential component of T-SQL-based systems. SQL Server implements role-based security models that allow administrators to control access to data and database objects.
T-SQL supports the creation of roles and permissions that define what users can see and do within the database. This includes access control at the table, schema, and object levels.
Encryption features and authentication mechanisms further enhance security, ensuring that sensitive data is protected both at rest and in transit.
T-SQL in Enterprise Applications
T-SQL is widely used in enterprise environments where large-scale data processing and complex business logic are required. Its ability to handle both data manipulation and procedural logic makes it suitable for mission-critical applications.
Industries such as finance, healthcare, logistics, and retail rely heavily on T-SQL for backend data processing and transaction management.
Its reliability, performance, and integration capabilities make it a preferred choice for organizations using Microsoft-based infrastructure.
Relationship Between T-SQL and Standard SQL
While T-SQL is based on standard SQL, it diverges significantly through its extended features. Standard SQL provides portability across systems, while T-SQL prioritizes functionality and integration within SQL Server.
This means that while basic SQL queries may work across multiple systems, advanced T-SQL features are specific to Microsoft environments.
Understanding this distinction is important for developers working in multi-platform or migration scenarios.
Importance of T-SQL in Data Management Systems
T-SQL plays a critical role in modern data management by enabling efficient data processing, complex logic execution, and system-level integration. Its combination of declarative and procedural capabilities allows it to handle a wide range of database tasks.
As data systems continue to evolve, T-SQL remains a key technology for managing structured data within Microsoft environments, supporting both traditional applications and modern cloud-based architectures.
Bridge Toward Comparative SQL Dialects
The features and capabilities of T-SQL provide a foundation for understanding how SQL dialects evolve to meet platform-specific needs. While T-SQL is optimized for Microsoft SQL Server, other systems adopt different approaches to extending SQL.
This sets the stage for exploring PL/SQL, Oracle’s procedural extension, and comparing how different database ecosystems solve similar challenges using distinct language designs.
Introduction to PL/SQL and Its Role in Oracle Databases
PL/SQL, which stands for Procedural Language/Structured Query Language, is Oracle’s proprietary extension of SQL. It is designed to enhance the capabilities of standard SQL by adding procedural programming features, enabling developers to build complex database applications directly within the Oracle Database environment.
While SQL focuses on querying and manipulating data in a declarative manner, PL/SQL introduces a procedural layer that allows developers to write logic-driven programs. This includes loops, conditions, variables, exceptions, and modular code structures. PL/SQL is tightly integrated with Oracle Database and is used extensively in enterprise-level systems where performance, reliability, and scalability are essential.
Unlike standalone programming languages that interact with databases externally, PL/SQL runs directly inside the database engine. This close integration allows for efficient data processing and reduces the need for repeated communication between application layers and the database.
Origins and Development of PL/SQL
PL/SQL was developed by Oracle Corporation as a response to the limitations of standard SQL in handling complex business logic. As organizations began building more sophisticated applications, it became clear that SQL alone was insufficient for tasks requiring procedural control and structured programming logic.
The goal of PL/SQL was to combine the power of SQL with the flexibility of a procedural language. By embedding SQL within a procedural framework, Oracle created a language capable of handling both data manipulation and application logic within a single environment.
Over time, PL/SQL evolved into a robust programming language with features comparable to general-purpose languages, while remaining deeply integrated with Oracle Database systems.
Core Structure of PL/SQL Programs
PL/SQL programs are organized into logical blocks that define how code is structured and executed. Each block typically consists of a declaration section, an execution section, and an exception-handling section.
The declaration section is used to define variables, constants, and data types. The execution section contains the main logic of the program, including SQL statements and procedural code. The exception-handling section is used to manage runtime errors and ensure that the program behaves predictably in case of unexpected conditions.
This structured approach allows PL/SQL programs to be modular, maintainable, and reusable.
Procedural Capabilities in PL/SQL
One of the defining features of PL/SQL is its support for procedural programming constructs. These include variables, loops, conditional statements, and control structures that allow developers to implement complex logic.
Variables in PL/SQL are used to store temporary data during program execution. They can hold values retrieved from database queries or computed within the program itself.
Conditional statements allow decision-making within PL/SQL programs. Based on specific conditions, different blocks of code can be executed, enabling dynamic behavior.
Looping structures enable repeated execution of code blocks. These are useful for processing large datasets or performing iterative operations on records retrieved from the database.
Exception Handling in PL/SQL
PL/SQL provides a powerful exception-handling mechanism that allows developers to manage runtime errors gracefully. Instead of causing the program to terminate abruptly, exceptions can be caught and handled within the code.
This feature is essential for maintaining data integrity and ensuring reliable application behavior. Common exceptions include data type mismatches, constraint violations, and runtime errors caused by invalid operations.
By defining exception-handling blocks, developers can implement recovery logic, log errors, or perform alternative actions when something goes wrong.
Stored Procedures, Functions, and Packages in PL/SQL
PL/SQL supports the creation of stored procedures and functions, which are reusable program units stored within the database. Stored procedures perform specific tasks and may or may not return values, while functions always return a value.
These constructs allow developers to encapsulate business logic within the database layer, improving reusability and consistency across applications.
In addition to procedures and functions, PL/SQL introduces the concept of packages. A package is a collection of related procedures, functions, variables, and other elements grouped as a single unit. Packages help organize code logically and improve modularity.
This modular structure is one of the key strengths of PL/SQL, making it suitable for large-scale enterprise applications.
Integration of PL/SQL with SQL
PL/SQL is designed to work seamlessly with SQL. SQL statements can be embedded directly within PL/SQL blocks, allowing developers to perform data retrieval and manipulation as part of procedural logic.
This integration eliminates the need for external data access layers in many cases, reducing complexity and improving performance. It also ensures that business logic and data operations remain closely aligned.
However, PL/SQL extends SQL by allowing these operations to be controlled through procedural logic, making it far more powerful than SQL alone.
Performance Advantages of PL/SQL
One of the key benefits of PL/SQL is its performance efficiency. Because PL/SQL code runs inside the database engine, it reduces the need for multiple round-trips between the application and the database.
This is particularly important in high-performance systems where network latency and data transfer overhead can significantly impact execution time.
By executing complex logic directly within the database, PL/SQL minimizes external dependencies and optimizes data processing workflows.
PL/SQL and Oracle Database Ecosystem
PL/SQL is deeply integrated into the Oracle Database ecosystem. It is the primary language used for writing database logic, triggers, and backend processes in Oracle systems.
This tight integration allows PL/SQL to take advantage of Oracle-specific features such as advanced indexing, partitioning, and memory management.
It also enables PL/SQL programs to interact directly with database objects, making it a central component of Oracle-based application development.
Security and Access Control in PL/SQL
Security is an important aspect of PL/SQL programming. Oracle Database provides robust security mechanisms that control access to PL/SQL objects and database resources.
Permissions can be granted or restricted at various levels, including schema objects, procedures, and packages. This ensures that only authorized users can execute specific operations or access sensitive data.
PL/SQL also supports definer rights and invoker rights, which determine the execution context of stored programs and help enforce security policies.
PL/SQL in Enterprise Application Development
PL/SQL is widely used in enterprise environments where complex data processing and business logic are required. Its ability to handle large-scale operations within the database makes it suitable for industries such as finance, healthcare, telecommunications, and government systems.
In these environments, PL/SQL is often used to implement transaction processing systems, reporting engines, and data validation layers.
Its reliability and scalability make it a preferred choice for mission-critical applications that require high availability and data integrity.
Comparison of PL/SQL and T-SQL at a Conceptual Level
PL/SQL and T-SQL serve similar purposes but are designed for different database systems. Both extend SQL with procedural capabilities, but they differ in syntax, structure, and implementation.
PL/SQL is tightly integrated with Oracle Database, while T-SQL is designed for Microsoft SQL Server. This difference influences how each language handles features such as error management, transaction control, and system functions.
While PL/SQL emphasizes modular programming through packages, T-SQL focuses on batch-oriented execution and system integration.
Despite these differences, both languages aim to solve the same fundamental problem: enabling procedural logic within relational databases.
Differences in Language Design Philosophy
The design philosophy behind PL/SQL is centered on robustness, modularity, and enterprise scalability. Oracle emphasizes structured programming, code reuse, and long-term maintainability.
T-SQL, on the other hand, emphasizes simplicity, integration with Microsoft tools, and ease of use within SQL Server environments.
These philosophical differences influence how developers approach database programming in each system.
Portability and Vendor Lock-In Considerations
One of the challenges associated with PL/SQL and T-SQL is the lack of portability. Because both are proprietary extensions, code written in one system cannot be easily transferred to another.
This creates vendor lock-in, where applications become tightly coupled to a specific database platform. While this allows deeper integration and optimization, it reduces flexibility when migrating systems.
Standard SQL provides a more portable alternative, but it lacks the advanced features offered by these procedural extensions.
Role of SQL Dialects in Modern Data Architecture
SQL dialects such as PL/SQL and T-SQL play a critical role in modern data architecture. They allow databases to function not just as storage systems but as active components of application logic.
This shift has led to more efficient architectures where data processing occurs closer to the data itself, reducing latency and improving performance.
In distributed and cloud-based systems, these dialects continue to evolve to support scalability, automation, and integration with external services.
Security, Performance, and Maintainability Trade-Offs
Using procedural SQL extensions involves balancing several factors, including performance, security, and maintainability.
PL/SQL and T-SQL improve performance by reducing external data access, but can increase complexity if not properly managed. They also enhance security by centralizing logic within the database, but may reduce portability.
Maintaining large codebases in these languages requires careful design to ensure readability and modularity.
Final Comparative Perspective on SQL, PL/SQL, and T-SQL
SQL serves as the foundational language for relational databases, providing a standardized way to interact with data. PL/SQL and T-SQL extend this foundation by introducing procedural capabilities tailored to specific database systems.
PL/SQL is optimized for Oracle environments with a strong emphasis on modular programming and enterprise-scale reliability. T-SQL is optimized for Microsoft SQL Server with a focus on integration and system-level functionality.
Together, these languages represent different approaches to solving the same core challenge: enabling efficient, reliable, and scalable data management within relational database systems.
Conclusion
SQL, PL/SQL, and T-SQL represent three closely related but fundamentally different approaches to working with relational databases, and understanding their distinctions is essential for anyone working in data-driven systems. At the core, SQL remains the universal foundation. It provides a standardized, declarative way to query and manipulate structured data stored in relational database systems. Its strength lies in simplicity, portability, and consistency across platforms. Because it focuses on what data is required rather than how to retrieve it, SQL allows database engines to optimize execution internally, making it highly efficient for set-based operations.
However, as applications evolved and business requirements became more complex, SQL alone was no longer sufficient. Modern systems demanded more than simple queries and updates; they required conditional logic, iterative processing, error handling, and the ability to encapsulate business rules directly within the database layer. This gap between SQL’s declarative model and real-world application complexity led to the development of procedural extensions such as PL/SQL and T-SQL. These languages transformed databases from passive data storage systems into active processing environments capable of executing business logic internally.
PL/SQL, developed by Oracle, and T-SQL, developed for Microsoft SQL Server, both extend SQL in different ways while maintaining the core principles of relational data manipulation. They introduce procedural programming constructs such as variables, loops, conditionals, and exception handling. This allows developers to write more sophisticated logic directly inside the database, reducing dependency on external application code. By executing logic closer to the data, both languages improve performance, reduce network overhead, and enhance transactional consistency.
Despite their similarities in purpose, PL/SQL and T-SQL differ significantly in design philosophy and implementation. PL/SQL is deeply integrated into the Oracle ecosystem and emphasizes modular programming through structures such as packages, procedures, and functions. It is designed with enterprise-scale systems in mind, prioritizing robustness, code organization, and long-term maintainability. Its block-structured approach encourages developers to build reusable and well-organized components, making it particularly effective in large and complex database environments.
T-SQL, on the other hand, is tightly integrated with Microsoft SQL Server and focuses on simplicity, flexibility, and system integration. It extends SQL with procedural capabilities while maintaining a strong emphasis on set-based operations. T-SQL is designed to work seamlessly with Microsoft tools and frameworks, making it highly suitable for environments that rely on Windows-based infrastructure or Azure cloud services. Its batch-oriented execution model and built-in system functions make it efficient for both administrative tasks and application-level database programming.
One of the most important distinctions between these languages is how they handle procedural logic. While both PL/SQL and T-SQL support loops, conditionals, and variables, their syntax and structural approaches differ. PL/SQL enforces a strict block structure that clearly separates declaration, execution, and exception handling sections. This encourages disciplined programming and improves readability in large codebases. T-SQL, in contrast, integrates procedural constructs more loosely within its batch execution model, offering flexibility but sometimes leading to less structured code if not carefully managed.
Another key difference lies in error handling. PL/SQL provides a comprehensive exception-handling system that allows developers to capture and manage runtime errors in a structured way. This ensures that database operations can fail gracefully without compromising data integrity. T-SQL also supports error handling through constructs like TRY and CATCH blocks, but its implementation is more aligned with the procedural style of Microsoft environments. Both systems aim to improve reliability, but they reflect different design philosophies in how errors are managed and resolved.
Performance considerations also play an important role in distinguishing these languages. Both PL/SQL and T-SQL improve performance by reducing the need for repeated communication between application servers and databases. By executing logic directly within the database engine, they minimize network latency and improve processing efficiency. However, the way each language achieves optimization differs based on the underlying database architecture. Oracle’s PL/SQL benefits from deep integration with Oracle’s optimizer and memory management systems, while T-SQL leverages SQL Server’s query execution plans and indexing strategies.
Security is another area where both languages provide strong capabilities, but through different mechanisms. PL/SQL integrates with Oracle’s security model, allowing fine-grained control over execution privileges through concepts such as definer rights and invoker rights. This ensures that stored procedures execute within controlled security contexts. T-SQL relies on SQL Server’s role-based security model, where permissions are assigned to users and roles at various levels of the database hierarchy. Both approaches aim to protect sensitive data while allowing controlled access to database functionality.
From a development perspective, the choice between SQL, PL/SQL, and T-SQL is often dictated by the database platform in use rather than personal preference. SQL remains universal and portable, making it essential for cross-platform compatibility. However, once a specific database system is chosen, developers typically rely on its procedural extension to fully leverage its capabilities. This creates a natural ecosystem lock-in, where applications become closely tied to either Oracle or Microsoft environments.
This lack of portability between PL/SQL and T-SQL is one of the most significant challenges in multi-database environments. Code written in one dialect cannot be directly executed in the other without modification. Differences in syntax, built-in functions, transaction handling, and procedural constructs require careful rewriting during migration. While both Oracle and Microsoft provide tools to assist with database migration, full compatibility is rarely achieved without manual adjustments.
Despite these limitations, both PL/SQL and T-SQL play a critical role in modern enterprise systems. They enable databases to function not just as storage repositories but as active participants in application logic. This shift has led to architectures where business rules, data validation, and transactional workflows are partially or fully implemented within the database layer. As a result, databases have become more than just backend components; they are now integral parts of application intelligence.
In modern cloud and distributed environments, the relevance of these languages continues to grow. Both Oracle and Microsoft have adapted their database systems to support cloud-based deployment models, ensuring that PL/SQL and T-SQL remain applicable in scalable, distributed architectures. This includes support for automated scaling, high availability, and integration with external services.
Ultimately, SQL, PL/SQL, and T-SQL represent different layers of database evolution. SQL provides the foundational language for relational data interaction. PL/SQL and T-SQL build upon this foundation to introduce procedural capabilities tailored to specific platforms. Together, they form a continuum that reflects the increasing complexity of data systems and the need for more powerful tools to manage that complexity.