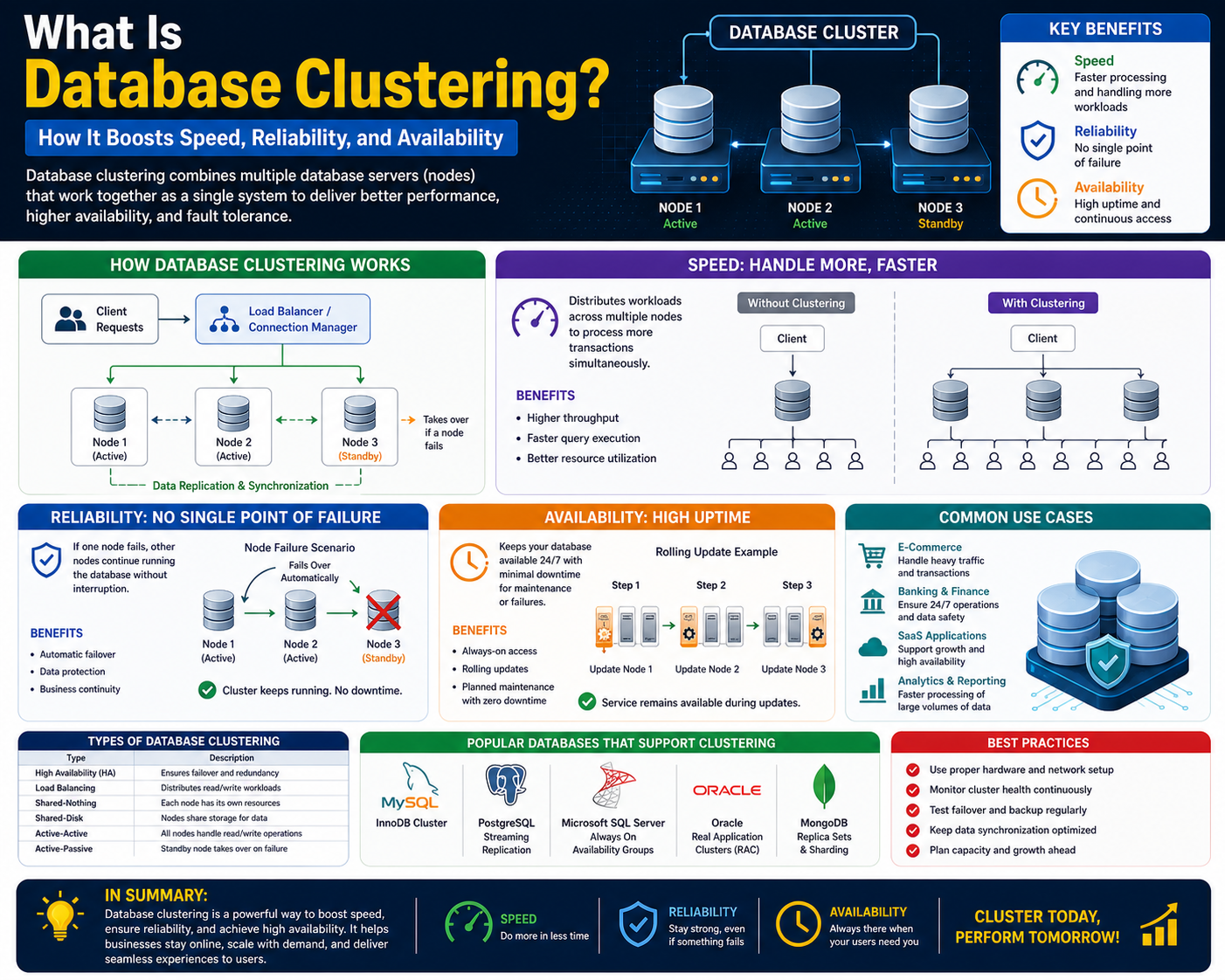
Modern digital ecosystems operate in environments where speed, uptime, and consistent data access are no longer optional requirements but foundational expectations. As applications scale across regions and user bases grow into millions, traditional single-server database designs begin to show structural limitations. These limitations often appear as performance degradation during peak traffic, increased latency under load, and complete service disruption when hardware failures occur. Database clustering emerges as a response to these challenges by transforming how database systems are architected and operated. Instead of relying on one machine to handle all data responsibilities, clustering distributes those responsibilities across multiple interconnected servers, allowing the system to function as a unified and resilient whole. This architectural shift enables systems to remain operational under heavy demand, recover quickly from failures, and scale more predictably as workloads increase. In practice, clustering is widely used in environments where continuous data availability and operational stability are essential for business continuity and user satisfaction.
Conceptual Foundation of Database Clustering
Database clustering is fundamentally a distributed computing approach applied specifically to database management systems. In this model, multiple servers known as nodes are linked together through a high-speed communication layer and configured to behave as a single logical database instance. Each node participates in processing queries, managing transactions, and maintaining data integrity depending on the design of the cluster. From the perspective of an application or end user, the cluster appears as a single database endpoint, even though multiple machines are working behind the scenes. This abstraction is essential because it allows developers to build applications without needing to manage the complexity of multiple databases manually. The primary goal of clustering is to eliminate single points of failure while improving throughput, scalability, and system resilience. By distributing workloads intelligently across nodes, clustering ensures that no single server becomes a bottleneck, even under high concurrency scenarios.
Operational Mechanics of Clustered Database Systems
The internal operation of a database cluster relies on continuous coordination between nodes to ensure consistency and availability. When a query enters the system, a routing mechanism determines which node should handle the request based on factors such as current load, node health, and data locality. Read operations are often distributed across multiple nodes to maximize performance, while write operations require stricter coordination to maintain data consistency. Once a write request is processed by one node, the update must be propagated to other nodes in the cluster through synchronization protocols. These protocols ensure that all nodes maintain an aligned view of the dataset, even when changes occur frequently. Additionally, monitoring mechanisms known as heartbeat signals continuously check the health of each node. If a node becomes unresponsive, failover processes automatically redirect traffic to healthy nodes, ensuring uninterrupted service delivery. This operational model creates a self-healing system capable of adapting to failures without manual intervention.
Core Structural Components of a Database Cluster
A database cluster is composed of multiple interdependent components that collectively ensure stability, performance, and data integrity. Nodes serve as the primary computing units responsible for executing queries and storing data. A communication layer enables fast and reliable exchange of information between nodes, which is essential for synchronization and coordination. Load balancing systems distribute incoming requests across nodes in a way that prevents overload and ensures optimal resource utilization. Storage architecture may vary depending on the clustering model, with some systems using shared storage while others rely on distributed storage across nodes. Failover mechanisms detect node failures and seamlessly transfer responsibilities to operational nodes. Synchronization engines ensure that data remains consistent across all nodes regardless of where updates occur. Together, these components form a tightly integrated system designed to function as a unified database service while maintaining internal distribution.
Data Flow and Transaction Processing in Clustered Environments
In a clustered database environment, data flow is carefully managed to balance performance and consistency. When a transaction is initiated, it is first received by a coordinator node or load balancer, which determines how the request should be processed. If the transaction involves reading data, it may be served by any available node that contains the relevant dataset. However, write transactions require more complex handling because they modify the state of the database. In such cases, the initiating node must ensure that changes are properly recorded and propagated across the cluster. This often involves locking mechanisms or consensus protocols that prevent conflicting updates. Once the transaction is confirmed, the changes are replicated to other nodes to maintain consistency. This structured flow ensures that even in distributed environments, data integrity is preserved across all operations.
Importance of Coordination and Consensus Mechanisms
Coordination is one of the most critical aspects of database clustering because multiple nodes must work together without introducing inconsistencies. Without proper coordination, simultaneous operations across nodes could result in conflicting updates or corrupted data states. To address this, clustered systems rely on consensus mechanisms that allow nodes to agree on the state of the system before executing critical operations. These mechanisms often involve electing a leader node responsible for managing specific tasks such as transaction ordering or cluster state decisions. Consensus algorithms ensure that even if some nodes fail or become temporarily unreachable, the system can still make reliable decisions based on majority agreement. This structured coordination allows clusters to maintain correctness while operating in unpredictable network conditions.
Data Distribution Strategies Across Cluster Nodes
Data distribution is a defining characteristic of database clustering and plays a major role in determining system efficiency and scalability. There are several strategies used to distribute data across nodes, each with its own advantages and trade-offs. In replicated systems, each node maintains a full copy of the dataset, which enhances availability and simplifies failover but increases storage requirements. In partitioned systems, data is divided into segments or shards, with each node responsible for a specific portion of the dataset. This approach improves scalability by allowing the system to handle larger datasets without overloading individual nodes. Hybrid distribution models combine replication and partitioning to balance performance and redundancy. The chosen strategy directly impacts system design, query performance, and fault tolerance behavior.
Shared-Nothing Clustering Model and Its Characteristics
The shared-nothing model is one of the most widely used clustering architectures in modern distributed systems. In this configuration, each node operates independently with its own dedicated storage, memory, and processing resources. Nodes do not share underlying hardware components, which reduces contention and eliminates bottlenecks associated with shared resources. This independence allows systems to scale horizontally by adding new nodes without significantly impacting existing infrastructure. Each node is responsible for a subset of the overall dataset, making workload distribution highly efficient. If one node fails, other nodes continue functioning without disruption, provided that data is properly partitioned or replicated. The shared-nothing model is particularly effective for large-scale applications that require high throughput and linear scalability.
Shared-Disk Clustering Model and Operational Behavior
In shared-disk clustering, multiple nodes access a centralized storage system while maintaining separate processing capabilities. This model simplifies data management because all nodes operate on the same dataset, eliminating the need for complex partitioning strategies. When a node processes a request, it reads and writes directly to shared storage, ensuring that all nodes have access to the most recent data. This architecture provides strong high-availability characteristics because any node can take over processing tasks if another node fails. However, shared access to storage introduces challenges related to concurrency control and data consistency. To manage these challenges, systems implement locking mechanisms and coordination protocols that prevent multiple nodes from modifying the same data simultaneously in conflicting ways. While this model enhances availability, it requires careful tuning to maintain performance under heavy load.
Hybrid Clustering Model and Adaptive Infrastructure Design
The hybrid clustering model integrates elements of both shared-nothing and shared-disk architectures to create a flexible and adaptive system. In this approach, certain data components may be shared across nodes while others are distributed independently. This allows system architects to optimize performance based on workload characteristics and operational requirements. For example, frequently accessed data may be replicated across multiple nodes to improve read performance, while less critical data may be partitioned to reduce redundancy overhead. Hybrid models are particularly useful in complex enterprise environments where workloads vary significantly across different applications. By combining multiple architectural principles, hybrid clustering enables systems to achieve a balance between scalability, performance, and reliability without being constrained by a single design philosophy.
Evolution of Cluster-Based Database Systems
Database clustering has evolved significantly alongside advancements in distributed computing and network infrastructure. Early database systems relied heavily on vertical scaling, where performance improvements were achieved by upgrading hardware on a single server. As data volumes increased and applications became more distributed, this approach became unsustainable. Clustering introduced horizontal scaling as a more efficient alternative, allowing systems to grow by adding more machines rather than relying on increasingly powerful hardware. Over time, improvements in network speed, synchronization algorithms, and distributed consensus techniques have made clustering more efficient and widely applicable. Modern systems now incorporate automated failover, intelligent load balancing, and real-time synchronization, making clustering a standard component of enterprise-level database architecture.
System Consistency Models in Clustered Databases
Consistency is a critical consideration in clustered environments because data is distributed across multiple nodes. Different systems adopt different consistency models depending on performance and reliability requirements. Strong consistency ensures that all nodes reflect the same data state at all times, but it may introduce latency due to synchronization overhead. Eventual consistency allows temporary differences between nodes with the expectation that they will converge over time, offering better performance at the cost of immediate accuracy. Some systems implement hybrid consistency models that adjust behavior based on operation type or system load. These models allow database clusters to balance trade-offs between speed, availability, and accuracy depending on operational context.
Fault Tolerance and Automatic Recovery Mechanisms
Fault tolerance is one of the defining strengths of database clustering. When a node fails due to hardware issues, software errors, or network disruptions, the cluster detects the failure through monitoring mechanisms. Once detected, traffic is automatically rerouted to healthy nodes, ensuring that users experience minimal disruption. In replicated systems, data from the failed node is already available on other nodes, allowing seamless continuation of operations. In partitioned systems, recovery mechanisms redistribute responsibilities or rebuild failed partitions. These automated recovery processes reduce downtime and eliminate the need for manual intervention, making clustered systems highly reliable in production environments.
Scaling Capabilities in Database Clustering Architectures
One of the most important advantages of database clustering is its ability to scale systems beyond the limitations of a single server. In traditional database environments, scaling often depends on vertical upgrades such as adding more CPU power, memory, or storage to a single machine. This approach eventually reaches physical and financial limits, making it unsuitable for modern high-demand applications. Database clustering instead enables horizontal scaling, where additional servers are added to the system to increase capacity. Each new node contributes processing power, memory, and storage resources, allowing the system to handle increased workloads without degrading performance. This scaling model is particularly effective in environments with unpredictable traffic patterns, such as online services, analytics platforms, and distributed applications that must respond dynamically to user demand.
Horizontal Scaling vs Vertical Scaling in Cluster Systems
In clustered database environments, horizontal scaling plays a central role in long-term system growth. Horizontal scaling, also known as scaling out, involves adding more nodes to distribute workload across a larger pool of resources. This approach increases system capacity in a modular and incremental way. In contrast, vertical scaling, or scaling up, focuses on enhancing the capabilities of a single server. While vertical scaling can provide short-term performance improvements, it eventually encounters hardware limitations. Clustered systems rely on horizontal scaling because it allows nearly unlimited expansion as long as additional nodes can be integrated into the network. This flexibility ensures that organizations can grow their infrastructure gradually without needing to redesign the entire system.
Load Distribution and Traffic Management in Clusters
Efficient load distribution is essential for maintaining performance in database clusters. When multiple users send requests to a database system simultaneously, the cluster must determine how to allocate these requests across available nodes. Load balancers play a key role in this process by analyzing node availability, current workload, and system health. Requests are then routed to the most appropriate node to prevent overloading any single server. This distribution ensures that system resources are utilized evenly, which helps maintain consistent response times even during peak usage periods. In advanced systems, load balancing may also consider data locality, meaning requests are directed to nodes that already contain relevant data, reducing latency and improving efficiency.
Dynamic Workload Adjustment in Clustered Systems
Database clusters are not static systems; they continuously adjust to changing workloads in real time. As user demand increases or decreases, the cluster redistributes tasks to maintain optimal performance. This dynamic adjustment is achieved through monitoring systems that track CPU usage, memory consumption, and query response times across all nodes. When a node becomes heavily loaded, new requests are redirected to less busy nodes. Similarly, when demand decreases, resources can be rebalanced to improve efficiency. This adaptive behavior ensures that the system remains responsive under varying conditions and avoids performance degradation caused by uneven resource utilization.
Performance Optimization Techniques in Database Clustering
Performance optimization in clustered environments involves a combination of architectural design and operational strategies. One common technique is query optimization, where database queries are analyzed and executed in the most efficient manner possible. Another approach involves caching frequently accessed data closer to the nodes that require it, reducing the need for repeated data retrieval from storage. Indexing strategies also play a crucial role in improving query performance by enabling faster data lookup. Additionally, some systems implement data partitioning strategies that ensure related data is stored together, minimizing cross-node communication. These techniques collectively enhance system responsiveness and reduce latency in high-demand environments.
Impact of Network Latency on Cluster Performance
Network latency is a significant factor that influences the performance of database clusters. Since nodes must communicate continuously to synchronize data and coordinate operations, any delay in network communication can impact overall system efficiency. High latency can slow down data replication, delay transaction confirmation, and reduce the responsiveness of distributed queries. To mitigate these issues, clustered systems are often deployed within high-speed, low-latency network environments. Advanced configurations may also include regional clustering, where nodes are grouped geographically to reduce communication delays between frequently interacting components. Minimizing latency is essential for maintaining consistent performance in distributed database architectures.
Fault Tolerance Mechanisms and System Stability
Fault tolerance is one of the core strengths of database clustering, allowing systems to continue operating even when individual components fail. This resilience is achieved through redundancy, where multiple nodes store or process the same data. When a node becomes unavailable, the system automatically reroutes requests to functioning nodes without disrupting service. Monitoring systems continuously check the health of each node using heartbeat signals, which indicate whether a node is active and responsive. If a failure is detected, failover mechanisms activate immediately, ensuring continuity of operations. This ability to withstand failures without service interruption makes clustering essential for mission-critical systems.
Failover Strategies in Distributed Database Systems
Failover is the process of transferring responsibilities from a failed node to a healthy node within a cluster. There are several types of failover strategies used in database clustering. Automatic failover occurs without human intervention and is triggered immediately when a node becomes unresponsive. Manual failover requires administrative action and is typically used during planned maintenance. In some systems, proactive failover is implemented, where potential issues are detected before a complete failure occurs, allowing the system to migrate workloads preemptively. These strategies ensure that users experience minimal disruption even in the event of hardware or software failures.
Data Replication Techniques in Cluster Environments
Data replication is a fundamental mechanism used to maintain consistency and availability in clustered databases. In synchronous replication, data changes are immediately propagated to all nodes before a transaction is considered complete. This ensures strong consistency but may introduce latency due to waiting for confirmation from multiple nodes. Asynchronous replication, on the other hand, allows changes to be written to one node first and propagated to others afterward. This improves performance but may result in temporary inconsistencies between nodes. Some systems use hybrid replication models that combine both approaches depending on the criticality of the data being processed.
Consistency Management Across Distributed Nodes
Maintaining consistency across multiple nodes is one of the most complex challenges in database clustering. Since data is distributed and operations occur simultaneously across different servers, there is always a risk of inconsistency. To address this, clustering systems use synchronization protocols that ensure all nodes agree on the current state of the database. These protocols often involve locking mechanisms, version control, and transaction ordering. Consistency models may vary depending on system requirements, with some systems prioritizing strict consistency and others allowing eventual consistency for improved performance. The choice of consistency model directly affects system behavior and application design.
Partitioning Strategies and Data Segmentation
Data partitioning, also known as sharding, is a technique used to divide large datasets into smaller, more manageable segments. Each segment is assigned to a specific node within the cluster. This approach improves performance by reducing the amount of data each node must process and allows the system to scale more efficiently. Partitioning strategies can be based on various criteria such as geographic location, user ID ranges, or data categories. Proper partitioning ensures balanced workload distribution and minimizes cross-node communication, which can be a major source of latency in distributed systems.
Resource Utilization Efficiency in Clustered Systems
Efficient resource utilization is a key objective in database clustering. Since multiple nodes are available to handle workloads, it is important to ensure that system resources are used effectively. Load balancing algorithms distribute tasks in a way that prevents some nodes from becoming overloaded while others remain underutilized. Resource monitoring tools track CPU usage, memory consumption, and disk activity across the cluster to identify inefficiencies. By optimizing resource allocation, clustered systems can achieve higher performance levels without requiring additional hardware investments.
Concurrency Control in Multi-Node Environments
Concurrency control is essential in database clustering because multiple nodes may attempt to access or modify the same data simultaneously. Without proper control mechanisms, this could lead to conflicts and data corruption. Clustering systems use techniques such as locking, timestamp ordering, and optimistic concurrency control to manage simultaneous operations. These mechanisms ensure that transactions are executed in a controlled and predictable manner. Concurrency control also plays a role in maintaining isolation between transactions, ensuring that operations do not interfere with each other in unintended ways.
Real-Time Processing Capabilities in Clusters
Many modern applications require real-time or near-real-time data processing capabilities. Database clustering supports these requirements by distributing processing tasks across multiple nodes, allowing systems to handle large volumes of data quickly. Real-time processing is particularly important in environments such as financial systems, monitoring platforms, and analytics engines. Clusters enable continuous data ingestion and processing without delays, ensuring that insights and results are available immediately. This capability is achieved through optimized data pipelines and parallel processing techniques that maximize throughput.
Impact of Cluster Design on Application Performance
The design of a database cluster has a direct impact on application performance. Factors such as node configuration, data distribution strategy, and communication protocols all influence how efficiently the system operates. Poorly designed clusters may suffer from bottlenecks, uneven load distribution, or synchronization delays. In contrast, well-designed clusters provide smooth scalability, consistent performance, and high availability. Application developers must consider cluster architecture when designing systems to ensure that database interactions are optimized for distributed environments.
System Monitoring and Health Management in Clusters
Continuous monitoring is essential for maintaining the health and stability of database clusters. Monitoring systems track various performance indicators such as response time, resource usage, and error rates. These metrics help identify potential issues before they escalate into system failures. Health management systems also provide alerts and automated responses to abnormal conditions. For example, if a node becomes overloaded, the system can automatically redistribute traffic to maintain balance. This proactive approach ensures that clusters remain stable and responsive under all operating conditions.
Enterprise-Scale Database Clustering Architectures
In large-scale enterprise environments, database clustering evolves beyond basic redundancy and performance optimization into a highly engineered infrastructure layer that supports global operations. These systems are designed to handle massive transaction volumes, distributed user bases, and mission-critical workloads that cannot tolerate downtime. Enterprise clustering architectures typically integrate multiple clustering models, advanced synchronization techniques, and geographically distributed nodes to ensure continuous availability. Unlike simpler deployments, enterprise clusters must support complex workflows involving cross-region replication, compliance requirements, and real-time analytics processing. This level of complexity requires careful orchestration of data movement, compute distribution, and system monitoring to maintain consistent performance across all operational conditions.
Geographically Distributed Clustering and Multi-Region Design
Geographically distributed clustering extends database systems across multiple physical locations, often spanning cities, countries, or continents. This design improves resilience by ensuring that data remains available even if an entire region experiences a failure. In such configurations, each region typically hosts a subset of cluster nodes that handle local traffic while synchronizing with nodes in other regions. This reduces latency for end users by bringing data closer to their location while maintaining global consistency. However, multi-region clustering introduces challenges related to network latency, data synchronization delays, and consistency management across long distances. To address these challenges, systems often implement intelligent routing mechanisms that direct user requests to the nearest available node while maintaining synchronization through optimized replication strategies.
Data Consistency Challenges in Distributed Environments
Maintaining consistent data across multiple nodes in a distributed cluster is one of the most complex aspects of database design. Since nodes may be separated by significant physical distances or network conditions, ensuring that all nodes reflect the same data state at the same time is difficult. Consistency issues often arise during concurrent updates, network partitions, or node failures. To manage these challenges, clustered systems rely on distributed consensus protocols that ensure agreement among nodes before committing changes. These protocols enforce rules about how and when data can be modified, ensuring that all nodes eventually converge to a consistent state. Depending on system design, consistency may be prioritized over performance or balanced with availability requirements to achieve optimal behavior.
Trade-Offs Between Consistency, Availability, and Performance
In clustered database systems, there is a fundamental trade-off between consistency, availability, and performance. Strong consistency ensures that all nodes reflect identical data at all times, but this often requires additional synchronization overhead that can impact performance. High availability prioritizes system uptime, allowing operations to continue even when some nodes are unavailable, but this may result in temporary inconsistencies. Performance optimization focuses on reducing latency and increasing throughput, sometimes at the cost of strict consistency guarantees. These trade-offs are influenced by the CAP principle, which highlights that distributed systems cannot simultaneously guarantee all three properties at maximum levels. Database clustering architectures are designed by carefully balancing these factors based on application requirements.
Advanced Replication Strategies in Cluster Systems
Replication in advanced database clusters goes beyond simple data copying and involves sophisticated strategies designed to optimize performance and reliability. Synchronous replication ensures that all nodes are updated simultaneously before a transaction is confirmed, providing strong consistency but increasing latency. Asynchronous replication allows updates to be applied to secondary nodes after the primary transaction is completed, improving performance but introducing temporary data lag. Semi-synchronous replication offers a balance between the two by requiring confirmation from a subset of nodes before completing a transaction. Some systems also implement multi-master replication, where multiple nodes can accept write operations simultaneously, requiring advanced conflict resolution mechanisms to maintain data integrity.
Conflict Resolution Mechanisms in Multi-Node Systems
When multiple nodes are allowed to process write operations independently, conflicts can arise when different nodes attempt to modify the same data simultaneously. Conflict resolution mechanisms are essential to ensure that the system maintains a consistent state. These mechanisms may include timestamp-based resolution, where the most recent update is prioritized, or version control systems that track changes and merge them intelligently. Some systems use application-level conflict resolution, allowing developers to define custom rules for handling conflicting updates. In more advanced architectures, consensus-based approaches ensure that all nodes agree on the final state of conflicting data before committing changes. These mechanisms are critical for maintaining reliability in distributed environments.
Role of Consensus Algorithms in Cluster Stability
Consensus algorithms play a vital role in ensuring that distributed database clusters operate reliably and consistently. These algorithms enable nodes to agree on system states, transaction ordering, and leadership roles within the cluster. Common consensus techniques ensure that even if some nodes fail or become unreachable, the remaining nodes can still make decisions based on majority agreement. This prevents split-brain scenarios, where different parts of the system operate independently with conflicting data. Consensus mechanisms also support leader election processes, where one node is selected to coordinate specific operations within the cluster. This structured decision-making process ensures that distributed systems remain stable and predictable under varying conditions.
Impact of Network Partitions on Cluster Behavior
Network partitions occur when communication between nodes in a cluster is disrupted, leading to isolated groups of nodes that cannot exchange information. This scenario presents a significant challenge for maintaining consistency and availability. During a partition, some nodes may continue processing requests independently, potentially leading to divergent data states. To mitigate this risk, clustered systems implement partition-tolerant strategies that prioritize either consistency or availability depending on system design. Some systems choose to restrict write operations during partitions to preserve consistency, while others allow continued operation with eventual synchronization once connectivity is restored. Handling network partitions effectively is essential for maintaining system reliability in distributed environments.
Security Considerations in Database Clustering
Security in clustered database environments involves protecting data both at rest and in transit across multiple nodes. Since data is continuously exchanged between nodes, encryption protocols are used to secure communication channels and prevent unauthorized access. Authentication mechanisms ensure that only authorized nodes can join the cluster, preventing malicious entities from interfering with system operations. Access control policies regulate how users and applications interact with the database, limiting permissions based on roles and responsibilities. Additionally, audit logging systems track all operations performed within the cluster, providing visibility into system activity and supporting compliance requirements. Security considerations are especially important in distributed systems where data traverses multiple network boundaries.
Backup and Disaster Recovery Strategies in Clustered Systems
Backup and disaster recovery mechanisms are essential components of database clustering strategies. Since data is distributed across multiple nodes, backups must be coordinated to ensure consistency across the entire system. Snapshots are often used to capture the state of the database at a specific point in time, allowing recovery in case of data corruption or system failure. In geographically distributed clusters, disaster recovery strategies involve replicating data to remote locations to ensure availability even in the event of regional outages. Recovery processes are designed to restore system functionality quickly while minimizing data loss. These strategies ensure that clustered systems remain resilient under extreme failure scenarios.
Performance Bottlenecks in High-Density Cluster Environments
Despite their advantages, database clusters can still experience performance bottlenecks under certain conditions. Common bottlenecks include network congestion, excessive synchronization overhead, and uneven workload distribution across nodes. When too many nodes attempt to communicate simultaneously, network bandwidth can become a limiting factor. Similarly, frequent data synchronization between nodes can introduce latency, especially in write-heavy workloads. Improper data partitioning may lead to some nodes becoming overloaded while others remain underutilized. Identifying and addressing these bottlenecks requires continuous monitoring and optimization of system configuration to ensure balanced resource utilization.
Resource Contention and Optimization Techniques
Resource contention occurs when multiple nodes or processes compete for the same system resources, such as CPU, memory, or storage bandwidth. In clustered environments, this can impact overall system performance if not properly managed. Optimization techniques include workload isolation, where specific nodes are assigned dedicated tasks, and resource throttling, which limits the amount of resources a single process can consume. Advanced scheduling algorithms also help distribute workloads more evenly across nodes. Additionally, caching frequently accessed data reduces pressure on underlying storage systems. These optimization strategies ensure that cluster resources are utilized efficiently without causing performance degradation.
Evolution Toward Autonomous Clustered Databases
Modern database clustering systems are increasingly moving toward autonomous operation, where many management tasks are automated using intelligent algorithms. These systems can automatically adjust resource allocation, detect performance anomalies, and optimize query execution without human intervention. Machine-driven monitoring tools analyze system behavior in real time and make adjustments to improve efficiency. Autonomous clustering reduces operational complexity and minimizes the need for manual tuning. This evolution reflects the growing demand for self-managing infrastructure capable of supporting large-scale, data-intensive applications with minimal administrative overhead.
Future Direction of Database Clustering Technologies
The future of database clustering is closely tied to advancements in distributed computing, artificial intelligence, and cloud-native architectures. Emerging systems are expected to become more adaptive, capable of self-healing, self-optimizing, and dynamically scaling based on workload patterns. Integration with edge computing environments will further reduce latency by processing data closer to users. Additionally, improvements in consensus algorithms and network protocols will enhance consistency and performance across distributed systems. As data volumes continue to grow, clustering will remain a fundamental technology for building scalable, resilient, and high-performance database systems.
Conclusion
Database clustering has become one of the most important architectural foundations in modern data-driven systems, not because it introduces a completely new way of storing information, but because it fundamentally changes how reliability, performance, and scalability are achieved at scale. Instead of depending on a single machine to carry the entire operational burden of a database, clustering distributes that responsibility across multiple interconnected nodes. This shift transforms databases from fragile, single-point systems into resilient, adaptive infrastructures capable of sustaining heavy workloads, hardware failures, and unpredictable traffic patterns without significant disruption.
At its core, clustering solves a problem that has grown more severe as digital systems expand: the mismatch between increasing user demand and the physical limitations of individual servers. Applications today are expected to respond instantly, remain continuously available, and handle massive volumes of concurrent operations. A single database server, no matter how powerful, eventually becomes a bottleneck under these conditions. Clustering addresses this by dividing responsibilities across multiple systems that work together as a unified logical database. This approach ensures that no single failure or overload condition is enough to bring the entire system down.
One of the most significant outcomes of clustering is the improvement in system resilience. In traditional database setups, a hardware failure, software crash, or network interruption can lead to full system downtime. In contrast, clustered environments are designed to anticipate such failures. Through redundancy, replication, and failover mechanisms, the system ensures that if one node becomes unavailable, others immediately take over its workload. This seamless transition is not just a technical convenience; it is a critical requirement for systems that support financial transactions, e-commerce operations, enterprise workflows, and real-time analytics. The ability to maintain continuity under failure conditions is what makes clustering essential in modern infrastructure design.
Equally important is the impact of clustering on performance optimization. By distributing queries across multiple nodes, clusters reduce the burden on any single server and enable parallel processing of operations. Read-heavy workloads, in particular, benefit significantly from this distribution, as multiple nodes can serve data simultaneously. Even in write-intensive systems, carefully designed synchronization strategies ensure that updates are handled efficiently without compromising consistency. This balance between workload distribution and data integrity allows clustered systems to maintain responsiveness even under extreme demand conditions.
Scalability is another defining advantage of database clustering. Unlike vertical scaling, which is constrained by hardware limitations, clustering allows systems to grow horizontally by adding more nodes. This modular growth model is particularly valuable in environments where demand fluctuates or increases unpredictably. Organizations can start with a small cluster and gradually expand it as their data requirements grow, without needing to redesign the entire system. This flexibility makes clustering a future-proof approach, capable of adapting to both short-term performance spikes and long-term data expansion.
However, the benefits of clustering do not come without complexity. Designing and maintaining a clustered database system requires careful planning, especially in areas such as data synchronization, consistency management, and network optimization. Ensuring that all nodes maintain a consistent view of data is one of the most challenging aspects of clustering. Depending on the architecture, systems may prioritize strict consistency or adopt eventual consistency models to improve performance. Each approach carries trade-offs, and selecting the appropriate model depends heavily on application requirements and operational priorities.
Another important consideration is the cost and operational overhead associated with clustering. While it can reduce reliance on expensive high-end servers, it introduces additional complexity in terms of infrastructure management, monitoring, and maintenance. Multiple nodes must be continuously monitored for performance, health, and synchronization accuracy. Failures must be detected quickly, and recovery mechanisms must activate automatically to maintain system stability. This requires advanced tooling and expertise, making clustering more suitable for environments where reliability and scalability are critical enough to justify the complexity.
Despite these challenges, clustering remains a foundational technology in modern computing environments. Its applications span across industries that depend heavily on continuous data access and high availability. In transactional systems, it ensures that operations such as payments, bookings, and orders are processed without interruption. In analytics platforms, it enables the processing of large datasets in real time, allowing organizations to derive insights quickly. In enterprise systems, it supports collaboration across distributed teams and global operations. In all these cases, clustering acts as the underlying structure that keeps systems stable, responsive, and scalable.
The evolution of database clustering also reflects broader trends in distributed computing. As systems become more decentralized and data becomes more geographically distributed, clustering technologies continue to adapt. Modern implementations increasingly incorporate automation, intelligent load balancing, and self-healing capabilities that reduce the need for manual intervention. These advancements are moving clustering toward a more autonomous model, where systems can dynamically adjust to workload changes, detect anomalies, and optimize performance in real time.
Looking forward, the role of database clustering is expected to grow even further as data volumes continue to increase and applications become more complex. Emerging technologies such as edge computing, real-time analytics, and globally distributed applications will rely heavily on clustered architectures to function efficiently. Improvements in network infrastructure, synchronization algorithms, and distributed consensus models will continue to enhance the performance and reliability of these systems. As a result, clustering will remain a central pillar of scalable system design for the foreseeable future.
Ultimately, database clustering represents a shift in thinking about how data systems should operate. Instead of building systems that rely on individual strength, it emphasizes coordination, distribution, and collective reliability. It reflects a move toward systems that are not only powerful but also resilient by design. In an environment where downtime, latency, and data loss can have significant consequences, clustering provides a structured and scalable way to ensure that databases remain fast, available, and dependable under all conditions.